
JVM垃圾回收算法的概念与分析

前言
在JVM内存模型中会将堆内存划分新生代、老年代两个区域,两块区域的主要区别在于新生代存放存活时间较短的对象,老年代存放存活时间较久的对象,除了存活时间不同外,还有垃圾回收策略的不同,在JVM中中有以下回收算法:
- 标记清除
- 标记整理
- 复制算法
- 分代收集算法
有了垃圾回收算法,那JVM是如果确定对象是垃圾对象的呢?判断对象是否存活JVM也会有几套自己判断算法了:
- 引用记数
- 可达性分析
有了垃圾回收和判断对象存在这两个概念后,再来逐步分析它们。
JVM是如何判断对象是否存活的?
要是让开发人员来判断一个对象是否有用是很简单的,简单的说就是:对象没有任何引用就认为该对象可以被回收了。假设有如下程序代码:
public class App {
public static void main(){
checkFile("/");
}
public static boolean checkFile(String path ){
File file = new File(path);
return file.exists();
}
}
程序执行起来在调用checkFile的时候JVM图大概像这样:
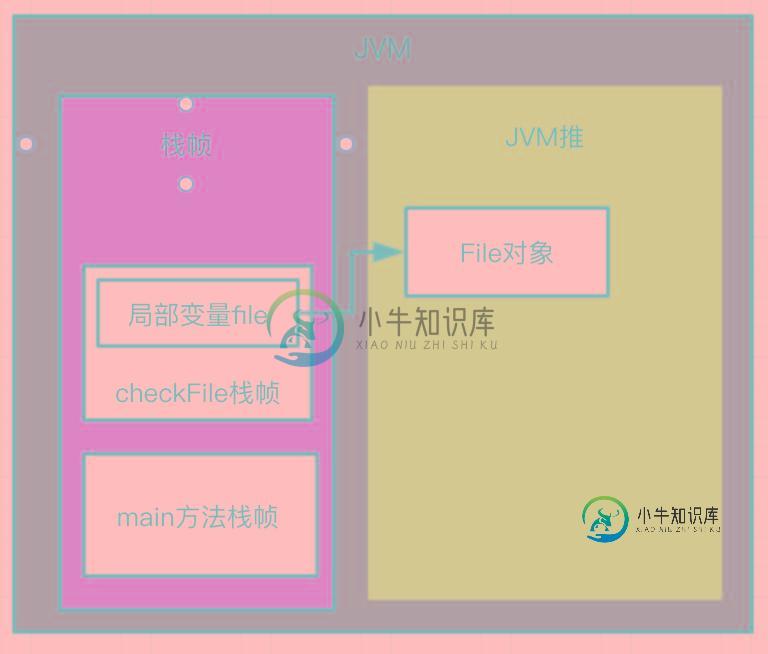
到checkFile方法执行完成之后,它里面的局部变量file就会随着栈帧一起被清理,这个时候还存活在JVM堆中的File对象也是无用的了:
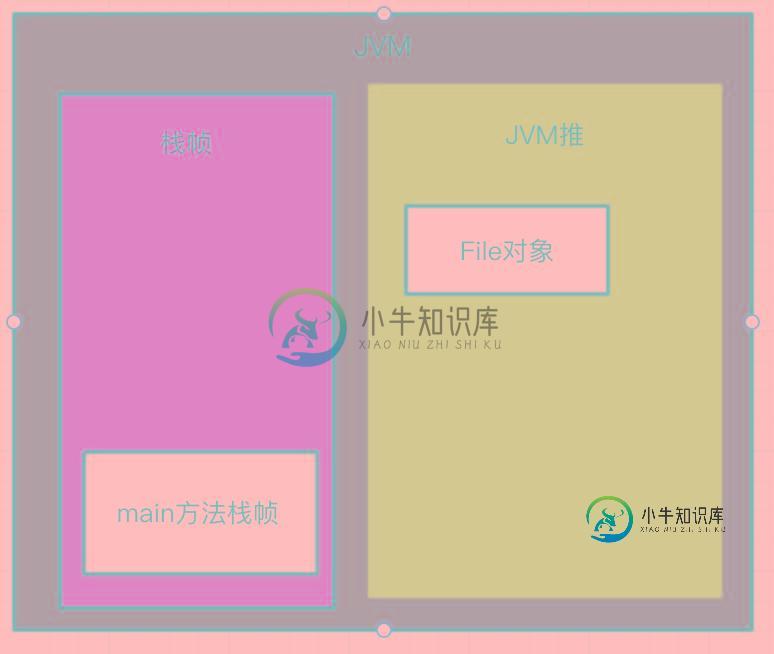
要是人为来判断非常清晰的就发现File对象已经无用了,那换成JVM它又是如何来判断对象是否能存活的呢?
引用记数
引用记数算法原理比较简单,想象下有个对象它有一个count属性,每次引用该对象都会使count加1,假设JVM在判断该对象是否存活的时候去检查这个count属性,发现这个属性不为0说明还有其他对象在引用该对象。
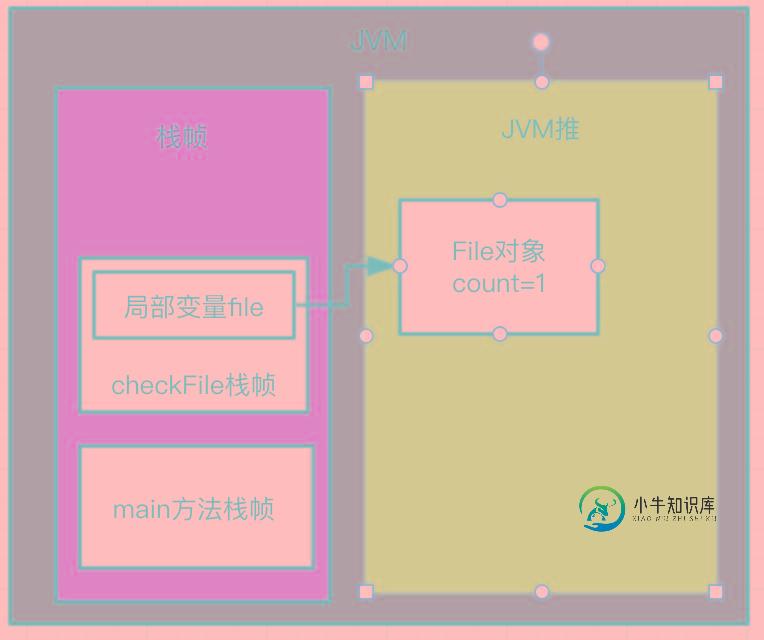
等到checkFile方法执行完之后count就会减1变成0:
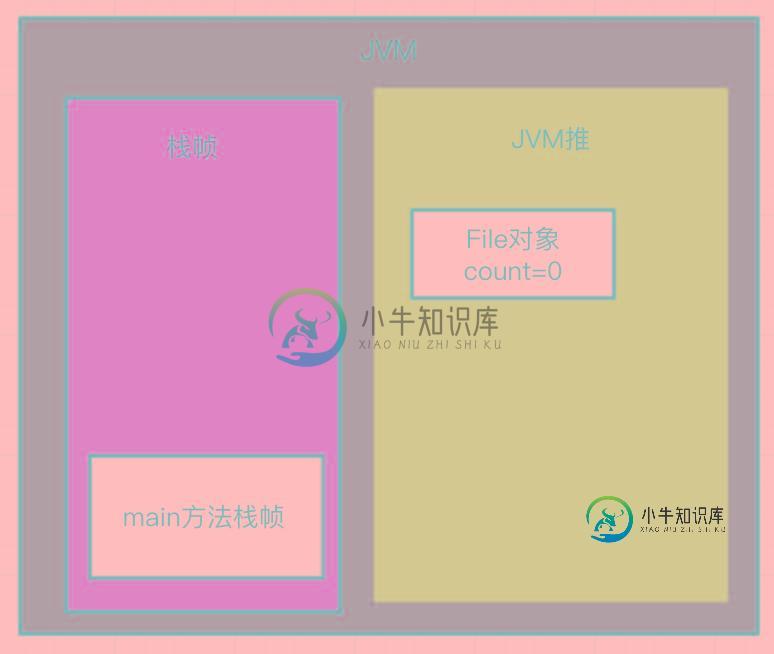
这样一来JVM就很容易判断一个对象是否存活了。
但是引用记数有一个明显的缺点,就是无法解决循环引用的问题比如:A --> B --> A 这样的对象关系它是没有办法来判断对象是否该不该回收的。
GC Root(可达性分析)
为什么会被称为可达性分析算法呢?可以这样理解如果通过GC Root能到达一个对象那么这个对象就是存活的。那什么样的对象才是GC Root呢?
在Java语言中,可作为GC Roots的对象包括下面几种:
- 虚拟机栈中引用的对象(栈帧中的本地变量表);
- 方法区中类静态属性引用的对象;
- 方法区中常量引用的对象;
- 本地方法栈中JNI(Native方法)引用的对象。
还是用上面的例子,在checkFile方法执行时,因为栈帧变量file可做为GC Root所以在执行期间JVM是绝对不会回收掉这个File对象:
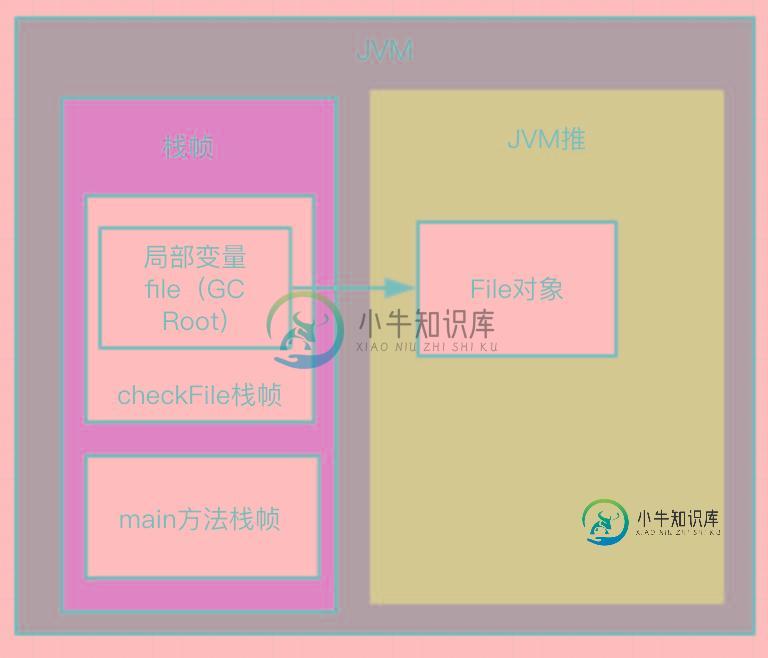
但是等到checkFile执行完成之后,这个栈帧会被弹出,其中的变量也会被释放,相应的没有GC Root能到达堆中的File对象,这个时候就可以判断这个对象是一个无用的对象了,然后安全回收。
垃圾收回算法
标记清除
这种算法分两分:标记、清除两个阶段,
标记阶段是从根集合(GC Root)开始扫描,每到达一个对象就会标记该对象为存活状态,清除阶段在扫描完成之后将没有标记的对象给清除掉。
用一张图说明:
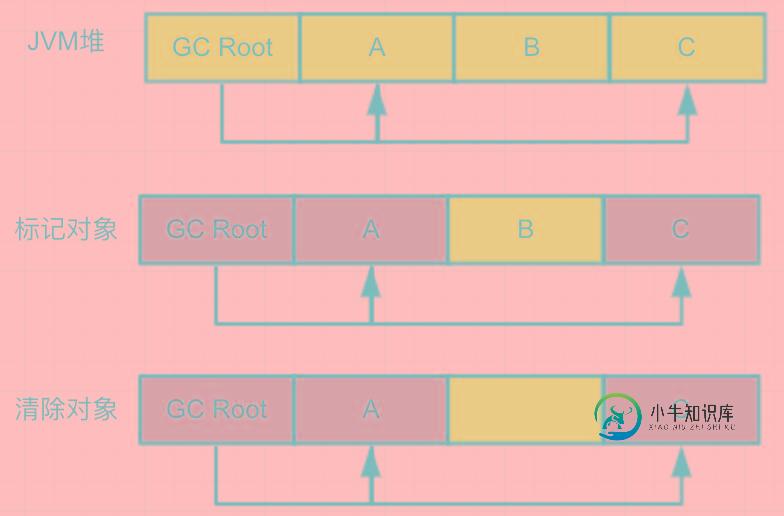
这个算法有个缺陷就是会产生内存碎片,如上图B被清除掉后会留下一块内存区域,如果后面需要分配大的对象就会导致没有连续的内存可供使用。
标记整理
标记整理就没有内存碎片的问题了,也是从根集合(GC Root)开始扫描进行标记然后清除无用的对象,清除完成后它会整理内存。
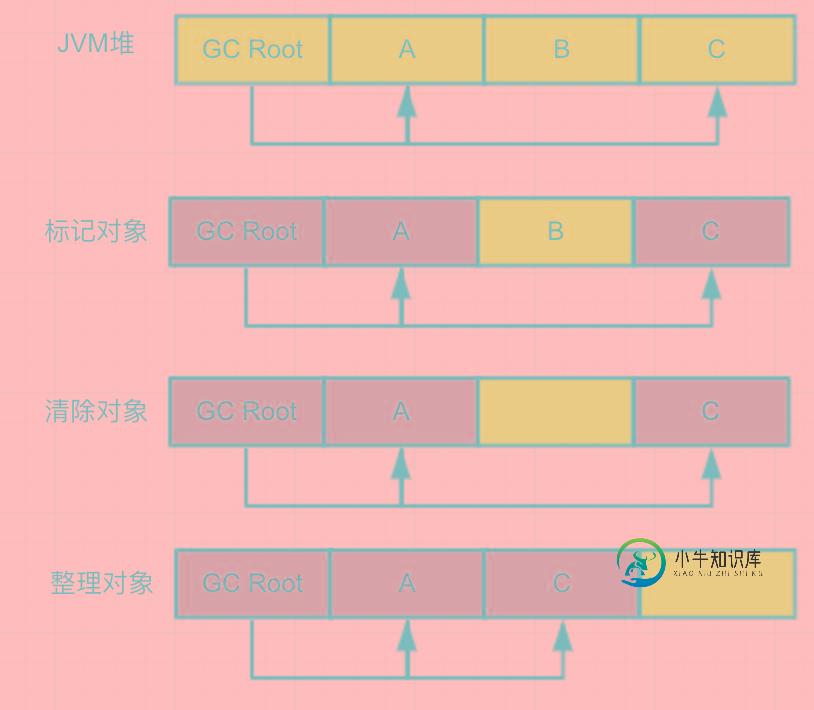
这样内存就是连续的了,但是产生的另外一个问题是:每次都得移动对象,因此成本很高。
复制算法
复制算法会将JVM推分成二等分,如果堆设置的是1g,那使用复制算法的时候堆就会有被划分为两块区域各512m。给对象分配内存的时候总是使用其中的一块来分配,分配满了以后,GC就会进行标记,然后将存活的对象移动到另外一块空白的区域,然后清除掉所有没有存活的对象,这样重复的处理,始终就会有一块空白的区域没有被合理的利用到。

两块区域交替使用,最大问题就是会导致空间的浪费,现在堆内存的使用率只有50%。
分代回收
新生代回收
JVM的堆分为新生代和老年代,两种类型有不同的特性,根据它们的特性来选择不同的回收算法,这种算法会将新生代划分为一块Eden和二个Survivor区:
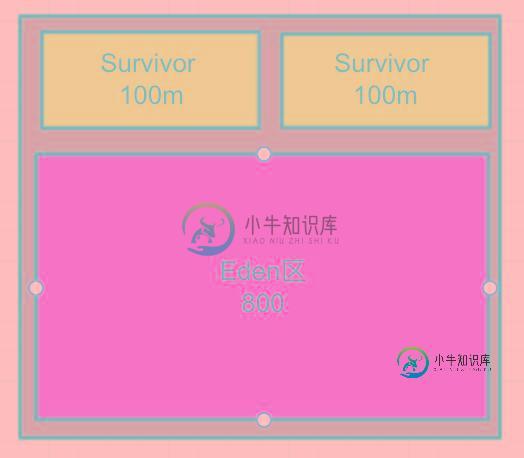
如上面的图有三块区域它们会按照8:1:1的比例进行分配,如1000m的堆Eden是800m,二个Survivor各占100m,那它们是如何运行的呢?
- 始终会有一块Survivor是空着的,内存使用率是90%
- 程序运行会在Eden和其中一块Survivor 1中分配内存
- 等到执行Minor gc,会将存活下来的对象移动到空着的Survivor 2中
- 然后在Eden和Survivor 2中继续分配内存,Survivor 1空着等着下次使用
这样就能使内存使用率达到90%,也不会产生内存碎片。
老年代回收
老年代对象即使进行了垃圾回收,对象的存活率也高,所以采用标记清除或标记整理算法都是不错的选择,这里就不做阐述。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小牛知识库的支持。
-
主要内容:垃圾回收算法,1、垃圾回收器的分类,2、串行垃圾回收器,3、吞吐量优先,4、响应时间优先,5、G1(Garbage First,jdk9默认),6、Full GC垃圾回收算法 1.标记清除 2.标记复制 3.标记整理 内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度) 内存整齐度:复制算法=标记清除算法>标记压缩算法 内存利用率:复制算法<标记清除算法=标记压缩算法 年轻代: 存活率低 复制算法 老年代: 区域大,存活率高 标记清除(内存碎片不是太多)+标记压缩共同实现 1、
-
主要内容:垃圾回收算法,1、垃圾回收器的分类,2、串行垃圾回收器,3、吞吐量优先,4、响应时间优先,5、G1(Garbage First,jdk9默认),6、Full GC垃圾回收算法 1.标记清除 2.标记复制 3.标记整理 内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度) 内存整齐度:复制算法=标记清除算法>标记压缩算法 内存利用率:复制算法<标记清除算法=标记压缩算法 年轻代: 存活率低 复制算法 老年代: 区域大,存活率高 标记清除(内存碎片不是太多)+标记压缩共同实现 1、
-
一、垃圾收集算法 1.标记-清除算法 最基础的收集算法是“标记-清除”(Mark-Sweep)算法,如同它的名字一样,算法分为“标记”和“清除”两个阶段。 ①首先标记出所有需要回收的对象 ②在标记完成后统一回收所有被标记的对象。 不足: 效率问题:标记和清除两个过程的效率都不高 空间问题:标记清除之后产生大量不连续的内存碎片,空间碎片太多可能会导致以后程序运行过程中需要分配较大对象时,无法找到足够
-
本文向大家介绍JVM的垃圾回收算法工作原理详解,包括了JVM的垃圾回收算法工作原理详解的使用技巧和注意事项,需要的朋友参考一下 怎么判断对象是否可以被回收? 共有2种方法,引用计数法和可达性分析 1.引用计数法 所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象
-
Java堆中存放着大量的Java对象实例,在垃圾收集器回收内存前,第一件事情就是确定哪些对象是“活着的”,哪些是可以回收的。 引用计数算法 引用计数算法是判断对象是否存活的基本算法:给每个对象添加一个引用计数器,没当一个地方引用它的时候,计数器值加1;当引用失效后,计数器值减1。但是这种方法有一个致命的缺陷,当两个对象相互引用时会导致这两个都无法被回收。 根搜索算法 在主流的商用语言中(Java、
-
本文向大家介绍浅析JVM垃圾回收的过程,包括了浅析JVM垃圾回收的过程的使用技巧和注意事项,需要的朋友参考一下 JVM垃圾回收的算法很多,但是不管是哪种算法,在进行GC时大致的流程都是差不多的,主要有以下3个过程: 1. 枚举根节点 这个过程主要是找到所有的GC Roots对象,这些对象一般发生在JVM虚拟机栈栈帧、常量池中的静态对象、方法区中静态类属性引用、本地方法栈中引用的对象。这个过程会发生