
多臂赌博机(Multi
1.多臂赌博机
多臂赌博机是指一类问题,这类问题重复的从k个行为(action)中选择一个,并获得一个奖励(reward),一次选择的时间周期称为一个时间步(time-step)。当选择并执行完一个行为后,得到一个奖励,我们称奖励的期望为这次行为的真实值(value)。在t时刻选择的行为用At表示,对应的奖励用Rt表示,对于行为a,其真实值为q∗(a),表示行为a的期望奖励,即:
$$q_*(a)=E[R_t|A_t=a]$$
如果我们知道每个行为的真实值,那么多臂赌博机的问题很容易就可以解决,但在大多数情况下,我们是不知道行为的具体值的,因此只能做近似。在t时刻用$$Q_t(a)$$作为$$q_(a)$$的估计值,即$$Q_t(a)$$约等于$$q_(a)$$
在时刻t,我们可以利用已有的知识即行为的估计值进行行为的最优选择,这种操作称为_exploit_,如果不选择当前的最优行为,我们称这种操作为_explore_,explore操作能够提高对行为值估计的准确度。exploit操作能够最大化当前步的奖励,但explore操作可能会使长期的奖励更大。如何平衡exploit操作和explore操作是强化学习中的一个重要问题。
2.估计行为值的方法
对行为值的估计是为了更好的选择行为。行为的值为每次执行该行为所得奖励的期望。因此可以用t时刻前行为已得到的奖励作为行为值的估计,即:

这只是估计行为值的一种方法,但并不是唯一同时也并不是最好的方法。这种方法称为
样本平均(sample-average)法,在t时刻选择行为时,使用贪心策略选择行为值最大的行为,即
$$A_t=arg_amaxQ_t(a)$$
这种选择行为的方法有一个缺陷,因为每次只做exploit操作,而不做explore操作,所以在选择行为时可能会漏掉那些真实值更大的行为。对此方法的一个改进是在大多数时间进行贪心策略也即exploit操作,但是会以ϵ的概率进行explore操作,也就是以ϵ的概率从其余行为(不具有最高估计值的行为)中随机选择一个执行,这种方法称为ϵ−greedy方法,这种方法的一个好处是在有限的时间步内能更新所有行为的估计值,即Qt(a)能够收敛到qt(a)
如果行为的奖励恒定不变的话,样本平均方法就可以很好的解决问题,但这种情况显然并不多。大多数情况下行为的奖励是服从某个分布的,甚至有些非平稳(nonstationary)问题,其中行为的真实值会发生变化,显然在这些情况下ϵ−greedy方法比样本平均方法能取得更好的效果。
在更新行为的估计值是有$$Q_n=\frac {R_1+R_2+...+R_{n-1}} {n-1}$$,其中$$R_i$$表示第i次执行该行为后所得的奖励。如果每次都这样直接计算$$Q_n$$,那么即浪费空间也浪费空间,所以采用一种增量式的实现,推导如下:
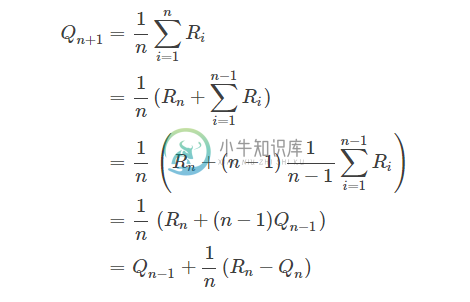
公式(4)的更新方式可以总结如下:
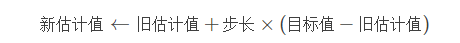
其中称(目标值−旧估计值)为误差(error)。可以看到,步长的大小随着时间而改变。后面用α或者αt表示步长。
3.初始值
对于平稳问题,前面两个方法在使用中有一个小技巧,就是提高初始值的大小。通过提高初始的行为估计值,可以有效的促进explore操作。比如,假设多臂赌博机的行为值服从期望为0,方差为1的正态分布,那么我们可以将初始的行为估计值设为5,当系统选择一个行为开始执行后,所获得的奖励很可能比5小,因此接下来就会尝试其他估计值为5的行为。这样在估计值收敛前,所有的行为都已经被执行了一遍或多遍。
通过设置较高的初始值是一种解决平稳问题的有效方法,但对于非平稳问题就没有那么好的效果。因为非平稳问题的真实行为值会发生变化
4.置信上界行为选择
上节讲到ϵ−greedy方法能够迫使agent执行explore操作,但存在一个问题,即进行explore操作时,如何选择那些不具有最高估计值的行为。一种思路是同时考虑行为的估计值与最大行为估计值的差距以及估计过程中的不确定性。用公式表示为:

其中Nt(a)表示在t时刻前行为a被执行的次数,Nt(a)越大说明行为a的估计值被更新的次数越多。如果Nt(a)=0则认为行为a首先被执行。
上述在explore操作中选择行为的思路称为置信上界(upper confidence bound, UCB),根号中的部分表示估计过程中的不确定性,因为估计的次数越少就代表不确定性越高,之所以采用t的自然对数是为了减小根号内部分的增长速度。这种思路会使所有的行为都被执行过。UCB方法在实际使用的过程中也取得了很好的效果,但相比与ϵ−greedy方法扩展性较差,而且不易应用到非平稳问题中。
5.梯度绑定算法(Gradient Bandit ALgorithms)
前面几步分主要讨论了如何估计行为值以及在explore操作中如何选择行为。本节介绍了一种新的方法,这种方法不用估计行为值既可以选择要执行的行为。每一个行为都有一个偏好度(preference),比如行为a的偏好度为Ht(a)。每次选择要执行的行为时,倾向于选择那些偏好度高的行为。例如,选择行为a的概率为:
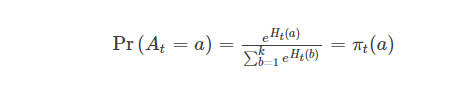
我们用$$π_t(a)$$表示在时刻t选择行为a的概率。初始化$$H_1(a)$$=0,∀a。每个时间步后按照下式进行更新:
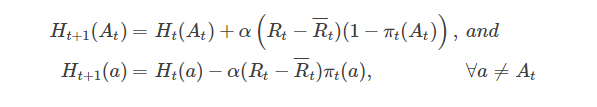
6.关联搜索
前面讲述的内容都是都是非关联性的问题,即行为和环境状态并无关联。基于非关联性的特征,在平稳问题中,agent只需学到一个最好的(奖励最高的)行为即可,在非平稳问题中,agent只需能够跟踪行为值的变化即可。然而强化学习面临的问题往往都不止一种状态,而且强化学习的目标是能够学到最大化奖励的策略。
可以举个例子对关联性问题进行说明,假设现在有5个k臂赌博机,每次我们都从这5个赌博机中随机挑选一个进行学习。这个问题是一个单一状态的非平稳问题。可以用前面讲的方法解决,但是,除非这5个赌博机的真实行为值变化不大,否则这些方法的效果并不好。我们继续在这个问题上增加一下条件,让每个赌博机都有特定的颜色,每次我们可以根据颜色知道玩的是哪一个赌博机。在这样的背景下,agent就要学习相应的策略。这样的问题就是关联性搜索的问题。