
VAE
短短三年时间,变分编码器VAE(Variational Auto-encoder)同GAN一样,成为无监督复杂概率分布学习的最流行的方法。VAE之所以流行,是因为它建立在标准函数逼近单元,即神经网络,此外它可以利用随机梯度下降进行优化。本文将解释重点介绍VAE背后的哲学思想和直观认识及其数学原理。
VAE的最大特点是模仿自动编码机的学习预测机制,在可测函数之间进行编码、解码。同GAN类似,其最重要的idea是基于一个令人惊叹的数学事实:对于一个目标概率分布,给定任何一种概率分布,总存在一个可微的可测函数,将其映射到另一种概率分布,使得这种概率分布与目标的概率分布任意的接近。
看到这里读者可能会一头雾水。下面我们来一一阐明其中的含义。
可测函数之间的编解码?什么样的可测函数?可测函数是测度论中的概念,它是真实世界的随机事件到数学世界的随机事件的映射。当然,在形式化问题过程中我们需要对这里面的所有事件进行量化,于是我们自然地会将这个数学世界选取为欧式空间,相应的σ-代数也就是Borelσ-代数了。回到选取可测函数的问题。VAE的一个重要的哲学思想是,遵从图模型,我们希望生成的样本是由某些隐含变量所构造出来的。举个例子,比如我们想要生成0-9的手写体,影响生成这些数字的样式可能有很多因素,比如笔画粗细、笔尖的角度、写者的书写习惯、天气好坏(天气会影响写者的心情,进而影响书写方式。根据蝴蝶效应,初始条件的微小变化会影响最终的结果)。这些因素不胜枚举,一些看似不相关的因素,都有可能影响最终的结果。一个直接的方法是显示地构造出这些隐含因素的概率分布,但是这些因素实在是太多了,无穷多个,我们显然不能手工构造。VAE巧妙地避开了这个问题,利用一个联合高斯分布作为隐含可测函数的分布(这个隐含可测函数将上面所说的所有现实世界影响写字样式的隐含因素映射到欧式空间中去了),随即将问题转化为学习一个从隐含可测函数(隐含变量)到一个所希望生成样本的映射。后面我们会看到,这个过程就是解码过程。可以想象,这个映射会极为复杂。我们自然会想到利用深度学习强大的函数拟合能力来学习这个映射。
模型推导
因此,我们希望得到这样一个生成模型,如下图所示。
其中z是隐含变量(隐含可测函数),将其输入到某种解码器,输出f(z),使得f(z)尽可能在保证样本多样性的同时与真实样本相似。
但是如何通过学习得到这样的解码器呢?
这就需要我们回归到目标函数中去考虑问题了。我们仅仅已知一些现成的样本S={x(i),i=1,...,m},比如,回到我们的例子,我们仅仅已知0-9这些手写体图片的样本,希望生成一些具有多样性类似的样本。那么自然会想到利用极大似然法来估计可学习的参数Θ,即
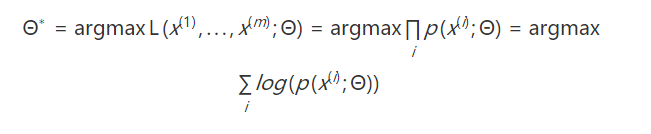
不失一般性,我们下面只针对单样本x进行讨论(略去其指标和可学习参数)。上面的似然函数仅仅是关于x的函数,我们需要想办法凑出隐变量z来。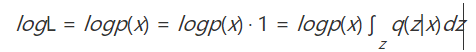
其中q(z|x)是给定样本下z的某一个条件概率分布。
这一步变换值得深思,为什么选用一个条件概率分布呢,而不选用q(z)或者p(z|x)呢?
因为q(z)的选取范围太大,我们更感兴趣的是那些更有可能生成x的隐变量z;关于p(z|x),p(⋅)可以认为是真实的概率分布,我们很难得到,我们希望做的是通过q(⋅)去逼近p(⋅),因此前者可以理解为某一种近似的概率分布。
我们继续进行推导,

我们考查其中的第一项,利用贝叶斯公式
这样我们就推导出VAE的一个核心等式,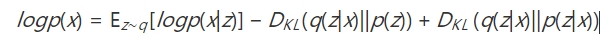
下面可以开始建模了。由前面的讨论(利用一个联合高斯分布作为隐含可测函数的分布),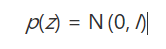
同样,q(z|x)和p(x|z)用联合高斯去建模,
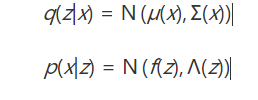
自然地,问题就转化成了用神经网络学习四种映射关系。但是,即使做了这样的建模,对于DKL(q(z|x)||p(z|x)),我们仍然难以给出其闭式解(归一化因子是一个复杂的多重积分)。因此只能退而求其次,我们对其做缩放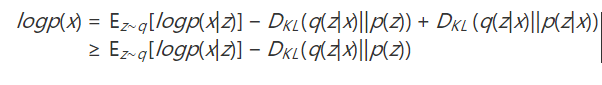
对对数似然的下界进行最大化。
进一步推导,我们将前面建模的概率模型带入这个下界中去。注意到在实际实现过程中,为了简化起见,Λ(z)取与z无关的单位阵I,于是有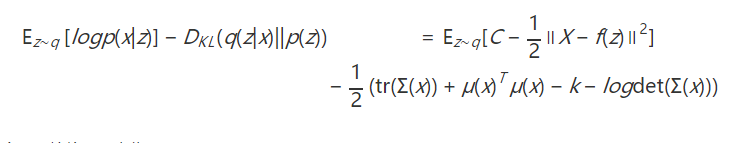
最大化这个下界等价于最小化
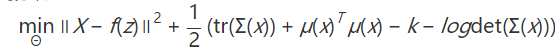
其中Θ为四个待学习映射的可学习参数集合。
至此,整个的学习框架就清晰了,如下图所示。
总结起来,整个训练框架就是在对样本x进行编解码。q是将样本x编码为隐变量z,而p又将隐含变量z解码成f(z),进而最小化重构误差。训练的目的是学习出编码器的映射函数和解码器的映射函数,所以训练过程实际上是在进行变分推断,即寻找出某一个函数来优化目标。因此取名为变分编码器VAE(Variational Auto-encoder).
关注具体实现的读者可能会发现在“解码器Decoder到μ(x)和Σ(x)”这个阶段从技术上没办法进行梯度反传。的确如此,上图只是作为帮助大家理解的示意图,而真正实现过程中,我们需要利用重参数化这个trick,如下图所示。
重参数化这个名字听起来很神秘,其实就是基于下面的一个简单的数学事实:
如果z∼N(μ,Σ),那么随机变量z可以写成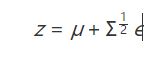
其中ϵ∼N(0,I)利用重参数化这个trick,我们成功地规避了这个问题。
参考文献
Tutorial on Variational Autoencoders. Carl Doersch. arXiv:1606.05908, 2016.