
池化层
池化层通过对数据进行分区采样,把一个大的矩阵降采样成一个小的矩阵,减少计算量,同时可以防止过拟合。
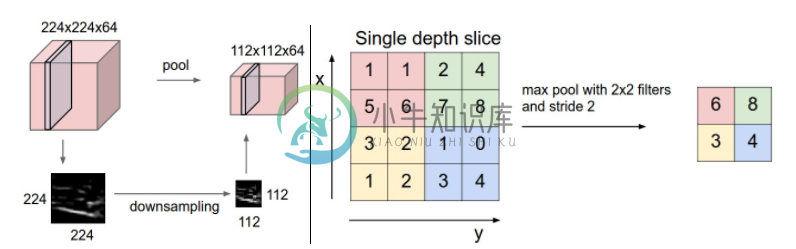
通常有最大池化层,平均池化层。最大池化层对每一个小区域选最最大值作为池化结果,平均池化层选取平均值作为池化结果。
MaxPooling1D层
MaxPooling2D层
MaxPooling3D层
本层目前只能在使用Theano为后端时可用
AveragePooling1D层
AveragePooling2D层
AveragePooling3D层
本层目前只能在使用Theano为后端时可用
GlobalMaxPooling1D层
GlobalAveragePooling1D层
GlobalMaxPooling2D层
GlobalAveragePooling2D层
Tensorflow中的最大池化层
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数是四个,和卷积很类似:
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取'VALID' 或者'SAME'
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
示例源码:
假设有这样一张图,双通道
第一个通道:
1 3 5 7
8 6 4 2
4 2 8 6
1 3 5 7
第二个通道:
2 4 6 8
7 5 3 1
3 1 7 5
2 4 6 8
用程序去做最大值池化:
import tensorflow as tf
a=tf.constant([
[[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0],
[8.0,7.0,6.0,5.0],
[4.0,3.0,2.0,1.0]],
[[4.0,3.0,2.0,1.0],
[8.0,7.0,6.0,5.0],
[1.0,2.0,3.0,4.0],
[5.0,6.0,7.0,8.0]]
])
a=tf.reshape(a,[1,4,4,2])
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,1,1,1],padding='VALID')
with tf.Session() as sess:
print("image:")
image=sess.run(a)
print (image)
print("reslut:")
result=sess.run(pooling)
print (result)
这里步长为1,窗口大小2×2,输出结果:
image:
[[[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 6. 5.]
[ 4. 3.]
[ 2. 1.]]
[[ 4. 3.]
[ 2. 1.]
[ 8. 7.]
[ 6. 5.]]
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]]]
reslut:
[[[[ 8. 7.]
[ 6. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 8. 7.]
[ 8. 7.]]
[[ 4. 4.]
[ 8. 7.]
[ 8. 8.]]]]
池化后的图就是:
8 7 6
8 8 8
4 8 8
和
7 6 8
7 7 7
4 7 8
我们还可以改变步长
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,2,2,1],padding='VALID')
输出
8 7
4 8
和
7 8
4 8