
概率分布 - torch.distributions
译者:hijkzzz
distributions 包含可参数化的概率分布和采样函数. 这允许构造用于优化的随机计算图和随机梯度估计器. 这个包一般遵循 TensorFlow Distributions 包的设计.
通常, 不可能直接通过随机样本反向传播. 但是, 有两种主要方法可创建可以反向传播的代理函数. 即得分函数估计器/似然比估计器/REINFORCE和pathwise derivative估计器. REINFORCE通常被视为强化学习中策略梯度方法的基础, 并且pathwise derivative估计器常见于变分自动编码器中的重新参数化技巧. 得分函数仅需要样本的值 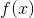 , pathwise derivative 需要导数
, pathwise derivative 需要导数 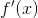 . 接下来的部分将在一个强化学习示例中讨论这两个问题. 有关详细信息, 请参阅 Gradient Estimation Using Stochastic Computation Graphs .
. 接下来的部分将在一个强化学习示例中讨论这两个问题. 有关详细信息, 请参阅 Gradient Estimation Using Stochastic Computation Graphs .
得分函数
当概率密度函数相对于其参数可微分时, 我们只需要sample()和log_prob()来实现REINFORCE:
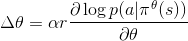
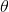 是参数,
是参数, 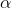 是学习速率,
是学习速率,  是奖励 并且
是奖励 并且 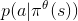 是在状态
是在状态  以及给定策略
以及给定策略 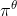 执行动作
执行动作  的概率.
的概率.
在实践中, 我们将从网络输出中采样一个动作, 将这个动作应用于一个环境中, 然后使用log_prob构造一个等效的损失函数. 请注意, 我们使用负数是因为优化器使用梯度下降, 而上面的规则假设梯度上升. 有了确定的策略, REINFORCE的实现代码如下:
probs = policy_network(state)
# Note that this is equivalent to what used to be called multinomial
m = Categorical(probs)
action = m.sample()
next_state, reward = env.step(action)
loss = -m.log_prob(action) * reward
loss.backward()
Pathwise derivative
实现这些随机/策略梯度的另一种方法是使用来自rsample()方法的重新参数化技巧, 其中参数化随机变量可以通过无参数随机变量的参数确定性函数构造. 因此, 重新参数化的样本变得可微分. 实现Pathwise derivative的代码如下:
params = policy_network(state)
m = Normal(*params)
# Any distribution with .has_rsample == True could work based on the application
action = m.rsample()
next_state, reward = env.step(action) # Assuming that reward is differentiable
loss = -reward
loss.backward()
分布
class torch.distributions.distribution.Distribution(batch_shape=torch.Size([]), event_shape=torch.Size([]), validate_args=None)
基类: object
Distribution是概率分布的抽象基类.
arg_constraints
从参数名称返回字典到 Constraint 对象(应该满足这个分布的每个参数).不是张量的arg不需要出现在这个字典中.
batch_shape
返回批量参数的形状.
cdf(value)
返回value处的累积密度/质量函数估计.
| 参数: | value (Tensor) – |
entropy()
返回分布的熵, 批量的形状为 batch_shape.
| 返回值: | Tensor 形状为 batch_shape. |
enumerate_support(expand=True)
返回包含离散分布支持的所有值的张量. 结果将在维度0上枚举, 所以结果的形状将是 (cardinality,) + batch_shape + event_shape (对于单变量分布 event_shape = ()).
注意, 这在lock-step中枚举了所有批处理张量[[0, 0], [1, 1], …]. 当 expand=False, 枚举沿着维度 0进行, 但是剩下的批处理维度是单维度, [[0], [1], ...
遍历整个笛卡尔积的使用 itertools.product(m.enumerate_support()).
| 参数: | expand (bool) – 是否扩展对批处理dim的支持以匹配分布的 batch_shape. |
| 返回值: | 张量在维上0迭代. |
event_shape
返回单个样本的形状 (非批量).
expand(batch_shape, _instance=None)
返回一个新的分布实例(或填充派生类提供的现有实例), 其批处理维度扩展为 batch_shape. 这个方法调用 expand 在分布的参数上. 因此, 这不会为扩展的分布实例分配新的内存. 此外, 第一次创建实例时, 这不会在中重复任何参数检查或参数广播在 __init__.py.
参数:
- batch_shape (torch.Size) – 所需的扩展尺寸.
- _instance – 由需要重写
.expand的子类提供的新实例.
| 返回值: | 批处理维度扩展为batch_size的新分布实例. |
icdf(value)
返回按value计算的反向累积密度/质量函数.
| 参数: | value (Tensor) – |
log_prob(value)
返回按value计算的概率密度/质量函数的对数.
| 参数: | value (Tensor) – |
mean
返回分布的平均值.
perplexity()
返回分布的困惑度, 批量的关于 batch_shape.
| 返回值: | 形状为 batch_shape 的张量. |
rsample(sample_shape=torch.Size([]))
如果分布的参数是批量的, 则生成sample_shape形状的重新参数化样本或sample_shape形状的批量重新参数化样本.
sample(sample_shape=torch.Size([]))
如果分布的参数是批量的, 则生成sample_shape形状的样本或sample_shape形状的批量样本.
sample_n(n)
如果分布参数是分批的, 则生成n个样本或n批样本.
stddev
返回分布的标准差.
support
返回Constraint 对象表示该分布的支持.
variance
返回分布的方差.
ExponentialFamily
class torch.distributions.exp_family.ExponentialFamily(batch_shape=torch.Size([]), event_shape=torch.Size([]), validate_args=None)
基类: torch.distributions.distribution.Distribution
指数族是指数族概率分布的抽象基类, 其概率质量/密度函数的形式定义如下
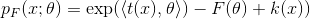
 表示自然参数,
表示自然参数, 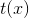 表示充分统计量,
表示充分统计量, 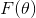 是给定族的对数归一化函数
是给定族的对数归一化函数 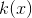 是carrier measure.
是carrier measure.
注意
该类是Distribution类与指数族分布之间的中介, 主要用于检验.entropy()和解析KL散度方法的正确性. 我们使用这个类来计算熵和KL散度使用AD框架和Bregman散度 (出自: Frank Nielsen and Richard Nock, Entropies and Cross-entropies of Exponential Families).
entropy()
利用对数归一化器的Bregman散度计算熵的方法.
Bernoulli
class torch.distributions.bernoulli.Bernoulli(probs=None, logits=None, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建参数化的伯努利分布, 根据 probs 或者 logits (但不是同时都有).
样本是二值的 (0 或者 1). 取值 1 伴随概率 p , 或者 0 伴随概率 1 - p.
例子:
>>> m = Bernoulli(torch.tensor([0.3]))
>>> m.sample() # 30% chance 1; 70% chance 0
tensor([ 0.])
参数:
- probs (Number_,_ Tensor) – the probabilty of sampling
1 - logits (Number_,_ Tensor) – the log-odds of sampling
1
arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
entropy()
enumerate_support(expand=True)
expand(batch_shape, _instance=None)
has_enumerate_support = True
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support = Boolean()
variance
Beta
class torch.distributions.beta.Beta(concentration1, concentration0, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
Beta 分布, 参数为 concentration1 和 concentration0.
例子:
>>> m = Beta(torch.tensor([0.5]), torch.tensor([0.5]))
>>> m.sample() # Beta distributed with concentration concentration1 and concentration0
tensor([ 0.1046])
参数:
- concentration1 (float or Tensor) – 分布的第一个浓度参数(通常称为alpha)
- concentration0 (float or Tensor) – 分布的第二个浓度参数(通常称为beta)
arg_constraints = {'concentration0': GreaterThan(lower_bound=0.0), 'concentration1': GreaterThan(lower_bound=0.0)}
concentration0
concentration1
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
rsample(sample_shape=())
support = Interval(lower_bound=0.0, upper_bound=1.0)
variance
Binomial
class torch.distributions.binomial.Binomial(total_count=1, probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建一个Binomial 分布, 参数为 total_count 和 probs 或者 logits (但不是同时都有使用). total_count 必须和 [probs] 之间可广播(#torch.distributions.binomial.Binomial.probs "torch.distributions.binomial.Binomial.probs")/logits.
例子:
>>> m = Binomial(100, torch.tensor([0 , .2, .8, 1]))
>>> x = m.sample()
tensor([ 0., 22., 71., 100.])
>>> m = Binomial(torch.tensor([[5.], [10.]]), torch.tensor([0.5, 0.8]))
>>> x = m.sample()
tensor([[ 4., 5.],
[ 7., 6.]])
参数:
- total_count (int or Tensor) – 伯努利试验次数
- probs (Tensor) – 事件概率
- logits (Tensor) – 事件 log-odds
arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0), 'total_count': IntegerGreaterThan(lower_bound=0)}
enumerate_support(expand=True)
expand(batch_shape, _instance=None)
has_enumerate_support = True
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support
variance
Categorical
class torch.distributions.categorical.Categorical(probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建一个 categorical 分布, 参数为 probs 或者 logits (但不是同时都有).
注意
它等价于从 torch.multinomial() 的采样.
样本是整数来自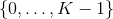
K 是 probs.size(-1).
如果 probs 是 1D 的, 长度为K, 每个元素是在该索引处对类进行抽样的相对概率.
如果 probs 是 2D 的, 它被视为一组相对概率向量.
注意
probs 必须是非负的、有限的并且具有非零和, 并且它将被归一化为和为1.
请参阅: torch.multinomial()
例子:
>>> m = Categorical(torch.tensor([ 0.25, 0.25, 0.25, 0.25 ]))
>>> m.sample() # equal probability of 0, 1, 2, 3
tensor(3)
参数:
- probs (Tensor) – event probabilities
- logits (Tensor) – event log probabilities
arg_constraints = {'logits': Real(), 'probs': Simplex()}
entropy()
enumerate_support(expand=True)
expand(batch_shape, _instance=None)
has_enumerate_support = True
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support
variance
Cauchy
class torch.distributions.cauchy.Cauchy(loc, scale, validate_args=None)
基类: torch.distributions.distribution.Distribution
样本来自柯西(洛伦兹)分布. 均值为0的独立正态分布随机变量之比服从柯西分布.
例子:
>>> m = Cauchy(torch.tensor([0.0]), torch.tensor([1.0]))
>>> m.sample() # sample from a Cauchy distribution with loc=0 and scale=1
tensor([ 2.3214])
参数:
- loc (float or Tensor) – 分布的模态或中值.
- scale (float or Tensor) – half width at half maximum.
arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(value)
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
support = Real()
variance
Chi2
class torch.distributions.chi2.Chi2(df, validate_args=None)
基类: torch.distributions.gamma.Gamma
创建由形状参数df参数化的Chi2分布. 这完全等同于 Gamma(alpha=0.5*df, beta=0.5)
例子:
>>> m = Chi2(torch.tensor([1.0]))
>>> m.sample() # Chi2 distributed with shape df=1
tensor([ 0.1046])
| 参数: | df (float or Tensor) – 分布的形状参数 |
arg_constraints = {'df': GreaterThan(lower_bound=0.0)}
df
expand(batch_shape, _instance=None)
Dirichlet
class torch.distributions.dirichlet.Dirichlet(concentration, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建一个 Dirichlet 分布, 参数为concentration.
例子:
>>> m = Dirichlet(torch.tensor([0.5, 0.5]))
>>> m.sample() # Dirichlet distributed with concentrarion concentration
tensor([ 0.1046, 0.8954])
| 参数: | concentration (Tensor) – 分布的浓度参数(通常称为alpha) |
arg_constraints = {'concentration': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
rsample(sample_shape=())
support = Simplex()
variance
Exponential
class torch.distributions.exponential.Exponential(rate, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建由rate参数化的指数分布.
例子:
>>> m = Exponential(torch.tensor([1.0]))
>>> m.sample() # Exponential distributed with rate=1
tensor([ 0.1046])
| 参数: | rate (float or Tensor) – rate = 1 / 分布的scale |
arg_constraints = {'rate': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(value)
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
stddev
support = GreaterThan(lower_bound=0.0)
variance
FisherSnedecor
class torch.distributions.fishersnedecor.FisherSnedecor(df1, df2, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建由df1和df2参数化的Fisher-Snedecor分布
例子:
>>> m = FisherSnedecor(torch.tensor([1.0]), torch.tensor([2.0]))
>>> m.sample() # Fisher-Snedecor-distributed with df1=1 and df2=2
tensor([ 0.2453])
参数:
- df1 (float or Tensor) – 自由度参数1
- df2 (float or Tensor) – 自由度参数2
arg_constraints = {'df1': GreaterThan(lower_bound=0.0), 'df2': GreaterThan(lower_bound=0.0)}
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
support = GreaterThan(lower_bound=0.0)
variance
Gamma
class torch.distributions.gamma.Gamma(concentration, rate, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建由concentration和rate参数化的伽马分布. .
例子:
>>> m = Gamma(torch.tensor([1.0]), torch.tensor([1.0]))
>>> m.sample() # Gamma distributed with concentration=1 and rate=1
tensor([ 0.1046])
参数:
- concentration (float or Tensor) – 分布的形状参数(通常称为alpha)
- rate (float or Tensor) – rate = 1 / 分布scale (通常称为beta )
arg_constraints = {'concentration': GreaterThan(lower_bound=0.0), 'rate': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
support = GreaterThan(lower_bound=0.0)
variance
Geometric
class torch.distributions.geometric.Geometric(probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建由probs参数化的几何分布, 其中probs是伯努利试验成功的概率. 它表示概率在  次伯努利试验中, 前
次伯努利试验中, 前  试验失败, 然后成功.
试验失败, 然后成功.
样本是非负整数 [0, 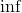 ).
).
例子:
>>> m = Geometric(torch.tensor([0.3]))
>>> m.sample() # underlying Bernoulli has 30% chance 1; 70% chance 0
tensor([ 2.])
参数:
- probs (Number_,_ Tensor) – 抽样
1的概率 . 必须是在范围 (0, 1] - logits (Number_,_ Tensor) – 抽样
1的log-odds.
arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
entropy()
expand(batch_shape, _instance=None)
log_prob(value)
logits
mean
probs
sample(sample_shape=torch.Size([]))
support = IntegerGreaterThan(lower_bound=0)
variance
Gumbel
class torch.distributions.gumbel.Gumbel(loc, scale, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
来自Gumbel分布的样本.
Examples:
>>> m = Gumbel(torch.tensor([1.0]), torch.tensor([2.0]))
>>> m.sample() # sample from Gumbel distribution with loc=1, scale=2
tensor([ 1.0124])
参数:
- loc (float or Tensor) – 分布的位置参数
- scale (float or Tensor) – 分布的scale 参数
arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
mean
stddev
support = Real()
variance
HalfCauchy
class torch.distributions.half_cauchy.HalfCauchy(scale, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
创建scale参数化的半正态分布:
X ~ Cauchy(0, scale)
Y = |X| ~ HalfCauchy(scale)
例子:
>>> m = HalfCauchy(torch.tensor([1.0]))
>>> m.sample() # half-cauchy distributed with scale=1
tensor([ 2.3214])
| 参数: | scale (float or Tensor) – 完全柯西分布的scale |
arg_constraints = {'scale': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(prob)
log_prob(value)
mean
scale
support = GreaterThan(lower_bound=0.0)
variance
HalfNormal
class torch.distributions.half_normal.HalfNormal(scale, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
创建按scale参数化的半正态分布:
X ~ Normal(0, scale)
Y = |X| ~ HalfNormal(scale)
例子:
>>> m = HalfNormal(torch.tensor([1.0]))
>>> m.sample() # half-normal distributed with scale=1
tensor([ 0.1046])
| 参数: | scale (float or Tensor) – 完全正态分布的scale |
arg_constraints = {'scale': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(prob)
log_prob(value)
mean
scale
support = GreaterThan(lower_bound=0.0)
variance
Independent
class torch.distributions.independent.Independent(base_distribution, reinterpreted_batch_ndims, validate_args=None)
基类: torch.distributions.distribution.Distribution
重新解释一些分布的批量 dims 作为 event dims.
这主要用于改变log_prob()结果的形状.例如, 要创建与多元正态分布形状相同的对角正态分布(因此它们是可互换的), 您可以这样做:
>>> loc = torch.zeros(3)
>>> scale = torch.ones(3)
>>> mvn = MultivariateNormal(loc, scale_tril=torch.diag(scale))
>>> [mvn.batch_shape, mvn.event_shape]
[torch.Size(()), torch.Size((3,))]
>>> normal = Normal(loc, scale)
>>> [normal.batch_shape, normal.event_shape]
[torch.Size((3,)), torch.Size(())]
>>> diagn = Independent(normal, 1)
>>> [diagn.batch_shape, diagn.event_shape]
[torch.Size(()), torch.Size((3,))]
参数:
- base_distribution (torch.distributions.distribution.Distribution) – 基础分布
- reinterpreted_batch_ndims (int) –要重解释的批量dims的数量
arg_constraints = {}
entropy()
enumerate_support(expand=True)
expand(batch_shape, _instance=None)
has_enumerate_support
has_rsample
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
sample(sample_shape=torch.Size([]))
support
variance
Laplace
class torch.distributions.laplace.Laplace(loc, scale, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建参数化的拉普拉斯分布, 参数是 loc 和 :attr:’scale’.
例子:
>>> m = Laplace(torch.tensor([0.0]), torch.tensor([1.0]))
>>> m.sample() # Laplace distributed with loc=0, scale=1
tensor([ 0.1046])
参数:
- loc (float or Tensor) – 分布均值
- scale (float or Tensor) – 分布scale
arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(value)
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
stddev
support = Real()
variance
LogNormal
class torch.distributions.log_normal.LogNormal(loc, scale, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
创建参数化的对数正态分布, 参数为 loc 和 scale:
X ~ Normal(loc, scale)
Y = exp(X) ~ LogNormal(loc, scale)
例子:
>>> m = LogNormal(torch.tensor([0.0]), torch.tensor([1.0]))
>>> m.sample() # log-normal distributed with mean=0 and stddev=1
tensor([ 0.1046])
参数:
- loc (float or Tensor) – 分布对数平均值
- scale (float or Tensor) – 分布对数的标准差
arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
loc
mean
scale
support = GreaterThan(lower_bound=0.0)
variance
LowRankMultivariateNormal
class torch.distributions.lowrank_multivariate_normal.LowRankMultivariateNormal(loc, cov_factor, cov_diag, validate_args=None)
基类: torch.distributions.distribution.Distribution
使用由cov_factor和cov_diag参数化的低秩形式的协方差矩阵创建多元正态分布:
covariance_matrix = cov_factor @ cov_factor.T + cov_diag
Example
>>> m = LowRankMultivariateNormal(torch.zeros(2), torch.tensor([1, 0]), torch.tensor([1, 1]))
>>> m.sample() # normally distributed with mean=`[0,0]`, cov_factor=`[1,0]`, cov_diag=`[1,1]`
tensor([-0.2102, -0.5429])
参数:
- loc (Tensor) – 分布的均值, 形状为
batch_shape + event_shape - cov_factor (Tensor) – 协方差矩阵低秩形式的因子部分, 形状为
batch_shape + event_shape + (rank,) - cov_diag (Tensor) – 协方差矩阵的低秩形式的对角部分, 形状为
batch_shape + event_shape
注意
避免了协方差矩阵的行列式和逆的计算, 当 cov_factor.shape[1] << cov_factor.shape[0] 由于 Woodbury matrix identity 和 matrix determinant lemma. 由于这些公式, 我们只需要计算小尺寸“capacitance”矩阵的行列式和逆:
capacitance = I + cov_factor.T @ inv(cov_diag) @ cov_factor
arg_constraints = {'cov_diag': GreaterThan(lower_bound=0.0), 'cov_factor': Real(), 'loc': Real()}
covariance_matrix
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
precision_matrix
rsample(sample_shape=torch.Size([]))
scale_tril
support = Real()
variance
Multinomial
class torch.distributions.multinomial.Multinomial(total_count=1, probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建由total_count和probs或logits(但不是两者)参数化的多项式分布. probs的最内层维度是对类别的索引. 所有其他维度索引批次.
注意 total_count 不需要指定, 当只有 log_prob() 被调用
注意
probs 必须是非负的、有限的并且具有非零和, 并且它将被归一化为和为1.
sample()所有参数和样本都需要一个共享的total_count.log_prob()允许每个参数和样本使用不同的total_count.
例子:
>>> m = Multinomial(100, torch.tensor([ 1., 1., 1., 1.]))
>>> x = m.sample() # equal probability of 0, 1, 2, 3
tensor([ 21., 24., 30., 25.])
>>> Multinomial(probs=torch.tensor([1., 1., 1., 1.])).log_prob(x)
tensor([-4.1338])
参数:
- total_count (int) – 试验次数
- probs (Tensor) – 事件概率
- logits (Tensor) – 事件对数概率
arg_constraints = {'logits': Real(), 'probs': Simplex()}
expand(batch_shape, _instance=None)
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support
variance
MultivariateNormal
class torch.distributions.multivariate_normal.MultivariateNormal(loc, covariance_matrix=None, precision_matrix=None, scale_tril=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建由均值向量和协方差矩阵参数化的多元正态(也称为高斯)分布.
多元正态分布可以用正定协方差矩阵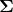 来参数化或者一个正定的精度矩阵
来参数化或者一个正定的精度矩阵 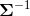 或者是一个正对角项的下三角矩阵
或者是一个正对角项的下三角矩阵 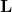 , 例如
, 例如 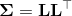 . 这个三角矩阵可以通过协方差的Cholesky分解得到.
. 这个三角矩阵可以通过协方差的Cholesky分解得到.
例子
>>> m = MultivariateNormal(torch.zeros(2), torch.eye(2))
>>> m.sample() # normally distributed with mean=`[0,0]` and covariance_matrix=`I`
tensor([-0.2102, -0.5429])
参数:
- loc (Tensor) – 分布的均值
- covariance_matrix (Tensor) – 正定协方差矩阵
- precision_matrix (Tensor) – 正定精度矩阵
- scale_tril (Tensor) – 具有正值对角线的下三角协方差因子
注意
仅仅一个 covariance_matrix 或者 precision_matrix 或者 scale_tril 可被指定.
使用 scale_tril 会更有效率: 内部的所有计算都基于 scale_tril. 如果 covariance_matrix 或者 precision_matrix 已经被传入, 它仅用于使用Cholesky分解计算相应的下三角矩阵.
arg_constraints = {'covariance_matrix': PositiveDefinite(), 'loc': RealVector(), 'precision_matrix': PositiveDefinite(), 'scale_tril': LowerCholesky()}
covariance_matrix
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
precision_matrix
rsample(sample_shape=torch.Size([]))
scale_tril
support = Real()
variance
NegativeBinomial
class torch.distributions.negative_binomial.NegativeBinomial(total_count, probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建一个负二项分布, 即在达到total_count失败之前所需的独立相同伯努利试验的数量的分布. 每次伯努利试验成功的概率都是probs.
参数:
- total_count (float or Tensor) – 非负数伯努利试验停止的次数, 虽然分布仍然对实数有效
- probs (Tensor) – 事件概率, 区间为 [0, 1)
- logits (Tensor) – 事件对数几率 - 成功概率的几率
arg_constraints = {'logits': Real(), 'probs': HalfOpenInterval(lower_bound=0.0, upper_bound=1.0), 'total_count': GreaterThanEq(lower_bound=0)}
expand(batch_shape, _instance=None)
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support = IntegerGreaterThan(lower_bound=0)
variance
Normal
class torch.distributions.normal.Normal(loc, scale, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建由loc和scale参数化的正态(也称为高斯)分布
例子:
>>> m = Normal(torch.tensor([0.0]), torch.tensor([1.0]))
>>> m.sample() # normally distributed with loc=0 and scale=1
tensor([ 0.1046])
参数:
- loc (float or Tensor) – 均值 (也被称为 mu)
- scale (float or Tensor) – 标准差(也被称为) sigma)
arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(value)
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
sample(sample_shape=torch.Size([]))
stddev
support = Real()
variance
OneHotCategorical
class torch.distributions.one_hot_categorical.OneHotCategorical(probs=None, logits=None, validate_args=None)
基类: torch.distributions.distribution.Distribution
创建一个由probs或logits参数化的One Hot Categorical 分布
样本是大小为 probs.size(-1)热编码向量.
注意
probs必须是非负的, 有限的并且具有非零和, 并且它将被归一化为总和为1.
请参见: torch.distributions.Categorical() 对于指定 probs 和 logits.
例子:
>>> m = OneHotCategorical(torch.tensor([ 0.25, 0.25, 0.25, 0.25 ]))
>>> m.sample() # equal probability of 0, 1, 2, 3
tensor([ 0., 0., 0., 1.])
参数:
- probs (Tensor) – event probabilities
- logits (Tensor) – event log probabilities
arg_constraints = {'logits': Real(), 'probs': Simplex()}
entropy()
enumerate_support(expand=True)
expand(batch_shape, _instance=None)
has_enumerate_support = True
log_prob(value)
logits
mean
param_shape
probs
sample(sample_shape=torch.Size([]))
support = Simplex()
variance
Pareto
class torch.distributions.pareto.Pareto(scale, alpha, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
来自Pareto Type 1分布的样本.
例子:
>>> m = Pareto(torch.tensor([1.0]), torch.tensor([1.0]))
>>> m.sample() # sample from a Pareto distribution with scale=1 and alpha=1
tensor([ 1.5623])
参数:
- scale (float or Tensor) – 分布的Scale
- alpha (float or Tensor) – 分布的Shape
arg_constraints = {'alpha': GreaterThan(lower_bound=0.0), 'scale': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
mean
support
variance
Poisson
class torch.distributions.poisson.Poisson(rate, validate_args=None)
基类: torch.distributions.exp_family.ExponentialFamily
创建按rate参数化的泊松分布
样本是非负整数, pmf是
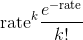
例子:
>>> m = Poisson(torch.tensor([4]))
>>> m.sample()
tensor([ 3.])
| 参数: | rate (Number_,_ Tensor) – rate 参数 |
arg_constraints = {'rate': GreaterThan(lower_bound=0.0)}
expand(batch_shape, _instance=None)
log_prob(value)
mean
sample(sample_shape=torch.Size([]))
support = IntegerGreaterThan(lower_bound=0)
variance
RelaxedBernoulli
class torch.distributions.relaxed_bernoulli.RelaxedBernoulli(temperature, probs=None, logits=None, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
创建一个RelaxedBernoulli分布, 通过temperature参数化, 以及probs或logits(但不是两者). 这是伯努利分布的松弛版本, 因此值在(0,1)中, 并且具有可重参数化的样本.
例子:
>>> m = RelaxedBernoulli(torch.tensor([2.2]),
torch.tensor([0.1, 0.2, 0.3, 0.99]))
>>> m.sample()
tensor([ 0.2951, 0.3442, 0.8918, 0.9021])
参数:
- temperature (Tensor) – 松弛 temperature
- probs (Number_,_ Tensor) –采样
1的概率 - logits (Number_,_ Tensor) – 采样
1的对数概率
arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
expand(batch_shape, _instance=None)
has_rsample = True
logits
probs
support = Interval(lower_bound=0.0, upper_bound=1.0)
temperature
RelaxedOneHotCategorical
class torch.distributions.relaxed_categorical.RelaxedOneHotCategorical(temperature, probs=None, logits=None, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
创建一个由温度参数化的RelaxedOneHotCategorical分布, 以及probs或logits. 这是OneHotCategorical分布的松弛版本, 因此它的样本是单一的, 并且可以重参数化.
例子:
>>> m = RelaxedOneHotCategorical(torch.tensor([2.2]),
torch.tensor([0.1, 0.2, 0.3, 0.4]))
>>> m.sample()
tensor([ 0.1294, 0.2324, 0.3859, 0.2523])
参数:
- temperature (Tensor) – 松弛 temperature
- probs (Tensor) – 事件概率
- logits (Tensor) –对数事件概率.
arg_constraints = {'logits': Real(), 'probs': Simplex()}
expand(batch_shape, _instance=None)
has_rsample = True
logits
probs
support = Simplex()
temperature
StudentT
class torch.distributions.studentT.StudentT(df, loc=0.0, scale=1.0, validate_args=None)
基类: torch.distributions.distribution.Distribution
根据自由度df, 平均loc和scale创建学生t分布.
例子:
>>> m = StudentT(torch.tensor([2.0]))
>>> m.sample() # Student's t-distributed with degrees of freedom=2
tensor([ 0.1046])
参数:
- df (float or Tensor) – 自由度
- loc (float or Tensor) – 均值
- scale (float or Tensor) – 分布的scale
arg_constraints = {'df': GreaterThan(lower_bound=0.0), 'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
support = Real()
variance
TransformedDistribution
class torch.distributions.transformed_distribution.TransformedDistribution(base_distribution, transforms, validate_args=None)
基类: torch.distributions.distribution.Distribution
Distribution类的扩展, 它将一系列变换应用于基本分布. 假设f是所应用变换的组成:
X ~ BaseDistribution
Y = f(X) ~ TransformedDistribution(BaseDistribution, f)
log p(Y) = log p(X) + log |det (dX/dY)|
注意 .event_shape of a TransformedDistribution 是其基本分布及其变换的最大形状, 因为变换可以引入事件之间的相关性.
一个使用例子 TransformedDistribution:
# Building a Logistic Distribution
# X ~ Uniform(0, 1)
# f = a + b * logit(X)
# Y ~ f(X) ~ Logistic(a, b)
base_distribution = Uniform(0, 1)
transforms = [SigmoidTransform().inv, AffineTransform(loc=a, scale=b)]
logistic = TransformedDistribution(base_distribution, transforms)
有关更多示例, 请查看有关实现 Gumbel, HalfCauchy, HalfNormal, LogNormal, Pareto, Weibull, RelaxedBernoulli 和 RelaxedOneHotCategorical
arg_constraints = {}
cdf(value)
通过逆变换和计算基分布的分数来计算累积分布函数.
expand(batch_shape, _instance=None)
has_rsample
icdf(value)
使用transform(s)计算逆累积分布函数, 并计算基分布的分数.
log_prob(value)
通过反转变换并使用基本分布的分数和日志abs det jacobian计算分数来对样本进行评分
rsample(sample_shape=torch.Size([]))
如果分布参数是批处理的, 则生成sample_shape形状的重新参数化样本或sample_shape形状的重新参数化样本批次. 首先从基本分布中采样, 并对列表中的每个变换应用transform()
sample(sample_shape=torch.Size([]))
如果分布参数是批处理的, 则生成sample_shape形样本或sample_shape形样本批处理. 首先从基本分布中采样, 并对列表中的每个变换应用transform().
support
Uniform
class torch.distributions.uniform.Uniform(low, high, validate_args=None)
基类: torch.distributions.distribution.Distribution
从半开区间[low, high)生成均匀分布的随机样本
例子:
>>> m = Uniform(torch.tensor([0.0]), torch.tensor([5.0]))
>>> m.sample() # uniformly distributed in the range [0.0, 5.0)
tensor([ 2.3418])
参数:
- low (float or Tensor) – 下限(含).
- high (float or Tensor) – 上限(排除).
arg_constraints = {'high': Dependent(), 'low': Dependent()}
cdf(value)
entropy()
expand(batch_shape, _instance=None)
has_rsample = True
icdf(value)
log_prob(value)
mean
rsample(sample_shape=torch.Size([]))
stddev
support
variance
Weibull
class torch.distributions.weibull.Weibull(scale, concentration, validate_args=None)
基类: torch.distributions.transformed_distribution.TransformedDistribution
来自双参数Weibull分布的样本.
Example
>>> m = Weibull(torch.tensor([1.0]), torch.tensor([1.0]))
>>> m.sample() # sample from a Weibull distribution with scale=1, concentration=1
tensor([ 0.4784])
参数:
- scale (float or Tensor) – Scale (lambda).
- concentration (float or Tensor) – Concentration (k/shape).
arg_constraints = {'concentration': GreaterThan(lower_bound=0.0), 'scale': GreaterThan(lower_bound=0.0)}
entropy()
expand(batch_shape, _instance=None)
mean
support = GreaterThan(lower_bound=0.0)
variance
KL Divergence
torch.distributions.kl.kl_divergence(p, q)
计算Kullback-Leibler散度 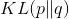 对于两个分布.
对于两个分布.
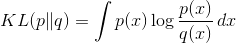
参数:
- p (Distribution) –
Distribution对象. - q (Distribution) –
Distribution对象.
| 返回值: | 批量的 KL 散度, 形状为 batch_shape. |
| 返回类型: | Tensor |
| 异常: | NotImplementedError – 如果分布类型尚未通过注册 register_kl(). |
torch.distributions.kl.register_kl(type_p, type_q)
装饰器注册kl_divergence()的成对函数
@register_kl(Normal, Normal)
def kl_normal_normal(p, q):
# insert implementation here
Lookup返回由子类排序的最具体(type,type)匹配. 如果匹配不明确, 则会引发RuntimeWarning. 例如, 解决模棱两可的情况
@register_kl(BaseP, DerivedQ)
def kl_version1(p, q): ...
@register_kl(DerivedP, BaseQ)
def kl_version2(p, q): ...
你应该注册第三个最具体的实现, 例如:
register_kl(DerivedP, DerivedQ)(kl_version1) # Break the tie.
参数:
- type_p (type) – 子类
Distribution. - type_q (type) – 子类
Distribution.
Transforms
class torch.distributions.transforms.Transform(cache_size=0)
有可计算的log det jacobians进行可逆变换的抽象类. 它们主要用于 torch.distributions.TransformedDistribution.
缓存对于其反转昂贵或数值不稳定的变换很有用. 请注意, 必须注意记忆值, 因为可以颠倒自动记录图. 例如, 以下操作有或没有缓存:
y = t(x)
t.log_abs_det_jacobian(x, y).backward() # x will receive gradients.
但是, 由于依赖性反转, 缓存时会出现以下错误:
y = t(x)
z = t.inv(y)
grad(z.sum(), [y]) # error because z is x
派生类应该实现_call()或_inverse()中的一个或两个. 设置bijective=True的派生类也应该实现log_abs_det_jacobian()
| 参数: | cache_size (int) – 缓存大小. 如果为零, 则不进行缓存. 如果是, 则缓存最新的单个值. 仅支持0和1 |
| Variables: |
- domain (
Constraint) – 表示该变换有效输入的约束. - codomain (
Constraint) – 表示此转换的有效输出的约束, 这些输出是逆变换的输入. - bijective (bool) – 这个变换是否是双射的. 变换
t是双射的 如果t.inv(t(x)) == x并且t(t.inv(y)) == y对于每一个x和y. 不是双射的变形应该至少保持较弱的伪逆属性t(t.inv(t(x)) == t(x)andt.inv(t(t.inv(y))) == t.inv(y). - sign (int or Tensor) – 对于双射单变量变换, 它应该是+1或-1, 这取决于变换是单调递增还是递减.
- event_dim (int) – 变换event_shape中相关的维数. 这对于逐点变换应该是0, 对于在矢量上共同作用的变换是1, 对于在矩阵上共同作用的变换是2, 等等.
inv
返回逆Transform. 满足 t.inv.inv is t.
sign
如果适用, 返回雅可比行列式的符号. 一般来说, 这只适用于双射变换.
log_abs_det_jacobian(x, y)
计算 log det jacobian log |dy/dx| 给定输入和输出.
class torch.distributions.transforms.ComposeTransform(parts)
在一个链中组合多个转换. 正在组合的转换负责缓存.
| 参数: | parts (list of Transform) – 列表 transforms. |
class torch.distributions.transforms.ExpTransform(cache_size=0)
转换通过映射 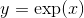 .
.
class torch.distributions.transforms.PowerTransform(exponent, cache_size=0)
转换通过映射 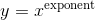 .
.
class torch.distributions.transforms.SigmoidTransform(cache_size=0)
转换通过映射 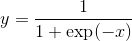 and
and 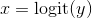 .
.
class torch.distributions.transforms.AbsTransform(cache_size=0)
转换通过映射 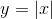 .
.
class torch.distributions.transforms.AffineTransform(loc, scale, event_dim=0, cache_size=0)
通过逐点仿射映射 进行转换 .
进行转换 .
参数:
- loc (Tensor or float) – Location.
- scale (Tensor or float) – Scale.
- event_dim (int) – 可选的
event_shape大小. T对于单变量随机变量, 该值应为零, 对于矢量分布, 1应为零, 对于矩阵的分布, 应为2.
class torch.distributions.transforms.SoftmaxTransform(cache_size=0)
从无约束空间到单纯形的转换, 通过 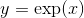 然后归一化.
然后归一化.
这不是双射的, 不能用于HMC. 然而, 这主要是协调的(除了最终的归一化), 因此适合于坐标方式的优化算法.
class torch.distributions.transforms.StickBreakingTransform(cache_size=0)
将无约束空间通过 stick-breaking 过程转化为一个额外维度的单纯形.
这种变换是Dirichlet分布的破棒构造中的迭代sigmoid变换:第一个逻辑通过sigmoid变换成第一个概率和所有其他概率, 然后这个过程重复出现.
这是双射的, 适合在HMC中使用; 然而, 它将坐标混合在一起, 不太适合优化.
class torch.distributions.transforms.LowerCholeskyTransform(cache_size=0)
将无约束矩阵转换为具有非负对角项的下三角矩阵.
这对于根据Cholesky分解来参数化正定矩阵是有用的.
Constraints
The following constraints are implemented:
constraints.booleanconstraints.dependentconstraints.greater_than(lower_bound)constraints.integer_interval(lower_bound, upper_bound)constraints.interval(lower_bound, upper_bound)constraints.lower_choleskyconstraints.lower_triangularconstraints.nonnegative_integerconstraints.positiveconstraints.positive_definiteconstraints.positive_integerconstraints.realconstraints.real_vectorconstraints.simplexconstraints.unit_interval
class torch.distributions.constraints.Constraint
constraints 的抽象基类.
constraint对象表示变量有效的区域, 例如, 其中可以优化变量
check(value)
返回一个字节张量 sample_shape + batch_shape 指示值中的每个事件是否满足此约束.
torch.distributions.constraints.dependent_property
alias of torch.distributions.constraints._DependentProperty
torch.distributions.constraints.integer_interval
alias of torch.distributions.constraints._IntegerInterval
torch.distributions.constraints.greater_than
alias of torch.distributions.constraints._GreaterThan
torch.distributions.constraints.greater_than_eq
alias of torch.distributions.constraints._GreaterThanEq
torch.distributions.constraints.less_than
alias of torch.distributions.constraints._LessThan
torch.distributions.constraints.interval
alias of torch.distributions.constraints._Interval
torch.distributions.constraints.half_open_interval
alias of torch.distributions.constraints._HalfOpenInterval
Constraint Registry
PyTorch 提供两个全局 ConstraintRegistry 对象 , 链接 Constraint 对象到 Transform 对象. 这些对象既有输入约束, 也有返回变换, 但是它们对双射性有不同的保证.
biject_to(constraint)查找一个双射的Transform从constraints.real到给定的constraint. 返回的转换保证具有.bijective = True并且应该实现了.log_abs_det_jacobian().transform_to(constraint)查找一个不一定是双射的Transform从constraints.real到给定的constraint. 返回的转换不保证实现.log_abs_det_jacobian().
transform_to()注册表对于对概率分布的约束参数执行无约束优化非常有用, 这些参数由每个分布的.arg_constraints指示. 这些变换通常会过度参数化空间以避免旋转; 因此, 它们更适合像Adam那样的坐标优化算法
loc = torch.zeros(100, requires_grad=True)
unconstrained = torch.zeros(100, requires_grad=True)
scale = transform_to(Normal.arg_constraints['scale'])(unconstrained)
loss = -Normal(loc, scale).log_prob(data).sum()
biject_to() 注册表对于Hamiltonian Monte Carlo非常有用, 其中来自具有约束. .support的概率分布的样本在无约束空间中传播, 并且算法通常是旋转不变的
dist = Exponential(rate)
unconstrained = torch.zeros(100, requires_grad=True)
sample = biject_to(dist.support)(unconstrained)
potential_energy = -dist.log_prob(sample).sum()
注意
一个 transform_to 和 biject_to 不同的例子是 constraints.simplex: transform_to(constraints.simplex) 返回一个 SoftmaxTransform 简单地对其输入进行指数化和归一化; 这是一种廉价且主要是坐标的操作, 适用于像SVI这样的算法. 相反, biject_to(constraints.simplex) 返回一个 StickBreakingTransform 将其输入生成一个较小维度的空间; 这是一种更昂贵的数值更少的数值稳定的变换, 但对于像HMC这样的算法是必需的.
biject_to 和 transform_to 对象可以通过用户定义的约束进行扩展, 并使用.register()方法进行转换, 作为单例约束的函数
transform_to.register(my_constraint, my_transform)
或作为参数化约束的装饰器:
@transform_to.register(MyConstraintClass)
def my_factory(constraint):
assert isinstance(constraint, MyConstraintClass)
return MyTransform(constraint.param1, constraint.param2)
您可以通过创建新的ConstraintRegistry创建自己的注册表.
class torch.distributions.constraint_registry.ConstraintRegistry
注册表, 将约束链接到转换.
register(constraint, factory=None)
在此注册表注册一个 Constraint 子类. 用法:
@my_registry.register(MyConstraintClass)
def construct_transform(constraint):
assert isinstance(constraint, MyConstraint)
return MyTransform(constraint.arg_constraints)
参数:
- constraint (subclass of
Constraint) – [Constraint]的子类(#torch.distributions.constraints.Constraint "torch.distributions.constraints.Constraint"), 或者派生类的对象. - factory (callable) – 可调用对象, 输入 constraint 对象返回
Transform对象.