
Python numpy。随机的具有非均匀/均匀概率分布的C#中的选择

我试图把一些代码,将做同样的Python, Numpy.random.选择
关键部分是:概率
与a中的每个条目相关的概率。如果没有给定,则样本假定a中所有条目的均匀分布。
一些测试代码:
import numpy as np
n = 5
vocab_size = 3
p = np.array( [[ 0.65278451], [ 0.0868038725], [ 0.2604116175]])
print('Sum: ', repr(sum(p)))
for t in range(n):
x = np.random.choice(range(vocab_size), p=p.ravel())
print('x: %s x[x]: %s' % (x, p.ravel()[x]))
print(p.ravel())
这将产生以下输出:
Sum: array([ 1.])
x: 0 x[x]: 0.65278451
x: 0 x[x]: 0.65278451
x: 0 x[x]: 0.65278451
x: 0 x[x]: 0.65278451
x: 0 x[x]: 0.65278451
[ 0.65278451 0.08680387 0.26041162]
有时候。
这里有一个分布,它是部分随机的,但也有结构。
我想在C#中实现这一点,老实说,我不确定是否有有效的方法来实现。
大约4年前,有一个很好的问题被提出:模仿Python的随机性。选择。网
因为这已经很老了,也没有真正深入研究均匀概率分布,我想我会要求一些阐述?
现在时代变了,代码也在变,我认为可能有更好的方法来实现。NETRandom。Choice()方法。
public static int Choice(Vector sequence, int a = 0, int size = 0, bool replace = false)
{
// F(x)
var Fx = 1/(b - a)
var p = (xmax - xmin) * Fx
return random.Next(0, sequence.Length);
}
向量只有一个双[]。
我将如何从这样的向量中随机选择概率:
p = np.array(
[[ 0.01313731], [ 0.01315883], [ 0.01312814], [ 0.01316345], [ 0.01316839],
[ 0.01314225], [ 0.01317578], [ 0.01312916], [ 0.01316344], [ 0.01317046],
[ 0.01314973], [ 0.01314432], [ 0.01317042], [ 0.01314846], [ 0.01315124],
[ 0.01316694], [ 0.0131816 ], [ 0.01315033], [ 0.0131645 ], [ 0.01314199],
[ 0.01315199], [ 0.01314431], [ 0.01314458], [ 0.01314999], [ 0.01315409],
[ 0.01316245], [ 0.01315008], [ 0.01314104], [ 0.01315215], [ 0.01317024],
[ 0.01315993], [ 0.01318789], [ 0.0131677 ], [ 0.01316761], [ 0.01315658],
[ 0.01315902], [ 0.01314266], [ 0.0131637 ], [ 0.01315702], [ 0.01315776],
[ 0.01316194], [ 0.01316246], [ 0.01314769], [ 0.01315608], [ 0.01315487],
[ 0.01316117], [ 0.01315083], [ 0.01315836], [ 0.0131665 ], [ 0.01314706],
[ 0.01314923], [ 0.01317971], [ 0.01316373], [ 0.01314863], [ 0.01315498],
[ 0.01315732], [ 0.01318195], [ 0.01315505], [ 0.01315979], [ 0.01315992],
[ 0.01316072], [ 0.01314744], [ 0.0131638 ], [ 0.01315642], [ 0.01314933],
[ 0.01316188], [ 0.01315458], [ 0.01315551], [ 0.01317907], [ 0.01316296],
[ 0.01317765], [ 0.01316863], [ 0.01316804], [ 0.01314882], [ 0.01316548],
[ 0.01315487]])
Python的输出是:
Sum: array([ 1.])
x: 21 x[x]: 0.01314431
x: 30 x[x]: 0.01315993
x: 54 x[x]: 0.01315498
x: 31 x[x]: 0.01318789
x: 27 x[x]: 0.01314104
有时
编辑:咖啡和睡眠之后,更多的见解。文档解释说:
从np生成非均匀随机样本。3号arange(5)无需更换:
NP随机的选择(5,3,replace=False,p=[0.1,0,0.3,0.6,0])数组([2,3,0])
参数p为序列或选择引入了非均匀分布。
与a中的每个条目相关联的概率。如果没有给定,则样本假定a中的所有条目都具有均匀分布。
所以我想,如果:
static int[] a = new int[] { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75};
static double[] p = new double[] { 0.01313731, 0.01315883, 0.01312814, 0.01316345, 0.01316839, 0.01314225,
0.01317578, 0.01312916, 0.01316344, 0.01317046, 0.01314973, 0.01314432,
0.01317042, 0.01314846, 0.01315124, 0.01316694, 0.0131816, 0.01315033,
0.0131645, 0.01314199, 0.01315199, 0.01314431, 0.01314458, 0.01314999,
0.01315409, 0.01316245, 0.01315008, 0.01314104, 0.01315215, 0.01317024,
0.01315993, 0.01318789, 0.0131677, 0.01316761, 0.01315658, 0.01315902,
0.01314266, 0.0131637, 0.01315702, 0.01315776, 0.01316194, 0.01316246,
0.01314769, 0.01315608, 0.01315487, 0.01316117, 0.01315083, 0.01315836,
0.0131665, 0.01314706, 0.01314923, 0.01317971, 0.01316373, 0.01314863,
0.01315498, 0.01315732, 0.01318195, 0.01315505, 0.01315979, 0.01315992,
0.01316072, 0.01314744, 0.0131638, 0.01315642, 0.01314933, 0.01316188,
0.01315458, 0.01315551, 0.01317907, 0.01316296, 0.01317765, 0.01316863,
0.01316804, 0.01314882, 0.01316548, 0.01315487 };
我如何有效地计算这个分布?
编辑:
虽然上述p参数可能没有明确的分布:
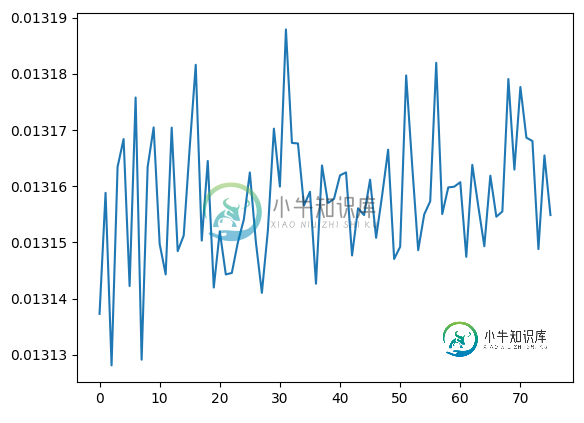
此p参数执行:
p = np.array(
[[ 3.09571694e-03], [ 6.62372261e-04], [ 2.52917874e-04], [ 6.93371978e-04],
[ 2.22301291e-04], [ 3.53796717e-02], [ 2.36204398e-04], [ 2.41100042e-04],
[ 1.59093166e-02], [ 5.17099025e-04], [ 2.72037896e-04], [ 1.29918769e-03],
[ 2.68077696e-02], [ 5.68696611e-04], [ 5.32142704e-04], [ 5.88432463e-05],
[ 2.53700138e-02], [ 2.51216588e-03], [ 4.72895541e-04], [ 4.20276848e-03],
[ 5.65701874e-05], [ 1.84972048e-03], [ 8.46515331e-03], [ 8.02505743e-02],
[ 5.34274983e-04], [ 5.18868535e-04], [ 2.22580377e-04], [ 2.50133462e-02],
[ 3.70997917e-02], [ 5.84941482e-05], [ 6.49978323e-04], [ 4.18675536e-01],
[ 6.16371962e-02], [ 3.82260752e-04], [ 6.09901544e-04], [ 2.54540201e-03],
[ 2.46758824e-04], [ 4.13621365e-04], [ 5.23495532e-04], [ 6.40675685e-03],
[ 1.14165332e-03], [ 1.89148994e-04], [ 8.41715724e-04], [ 8.65699032e-04],
[ 6.71368283e-04], [ 2.14908596e-03], [ 5.80679210e-02], [ 1.11176616e-02],
[ 6.58134137e-05], [ 2.38992622e-02], [ 2.91388753e-04], [ 1.93989753e-03],
[ 1.82157325e-03], [ 3.33691627e-03], [ 5.69157244e-03], [ 1.11033592e-04],
[ 2.42448034e-04], [ 8.42765356e-05], [ 1.31656056e-02], [ 1.68779684e-02],
[ 2.72298244e-02], [ 8.19056613e-04], [ 1.14640462e-02], [ 6.21846308e-05],
[ 9.24618073e-04], [ 3.63659515e-02], [ 7.17286486e-05], [ 6.24008652e-04],
[ 2.59900890e-03], [ 1.57848651e-04], [ 5.71378707e-05], [ 7.62828929e-04],
[ 2.91648042e-04], [ 1.67612579e-04], [ 1.65455262e-04], [ 1.01981563e-02]])

有些人认为这是一个向左倾斜的高斯分布。PoyserMath的这段视频非常棒:统计数据:使用正态分布表查找概率,解释为什么p的总和必须为1.0
编辑:12.04.17-终于找到了与此相关的python文件!!!
# Author: Hamzeh Alsalhi <ha258@cornell.edu>
#
# License: BSD 3 clause
from __future__ import division
import numpy as np
import scipy.sparse as sp
import operator
import array
from sklearn.utils import check_random_state
from sklearn.utils.fixes import astype
from ._random import sample_without_replacement
__all__ = ['sample_without_replacement', 'choice']
# This is a backport of np.random.choice from numpy 1.7
# The function can be removed when we bump the requirements to >=1.7
def choice(a, size=None, replace=True, p=None, random_state=None):
"""
choice(a, size=None, replace=True, p=None)
Generates a random sample from a given 1-D array
.. versionadded:: 1.7.0
Parameters
-----------
a : 1-D array-like or int
If an ndarray, a random sample is generated from its elements.
If an int, the random sample is generated as if a was np.arange(n)
size : int or tuple of ints, optional
Output shape. Default is None, in which case a single value is
returned.
replace : boolean, optional
Whether the sample is with or without replacement.
p : 1-D array-like, optional
The probabilities associated with each entry in a.
If not given the sample assumes a uniform distribution over all
entries in a.
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`.
Returns
--------
samples : 1-D ndarray, shape (size,)
The generated random samples
Raises
-------
ValueError
If a is an int and less than zero, if a or p are not 1-dimensional,
if a is an array-like of size 0, if p is not a vector of
probabilities, if a and p have different lengths, or if
replace=False and the sample size is greater than the population
size
See Also
---------
randint, shuffle, permutation
Examples
---------
Generate a uniform random sample from np.arange(5) of size 3:
>>> np.random.choice(5, 3) # doctest: +SKIP
array([0, 3, 4])
>>> #This is equivalent to np.random.randint(0,5,3)
Generate a non-uniform random sample from np.arange(5) of size 3:
>>> np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0]) # doctest: +SKIP
array([3, 3, 0])
Generate a uniform random sample from np.arange(5) of size 3 without
replacement:
>>> np.random.choice(5, 3, replace=False) # doctest: +SKIP
array([3,1,0])
>>> #This is equivalent to np.random.shuffle(np.arange(5))[:3]
Generate a non-uniform random sample from np.arange(5) of size
3 without replacement:
>>> np.random.choice(5, 3, replace=False, p=[0.1, 0, 0.3, 0.6, 0])
... # doctest: +SKIP
array([2, 3, 0])
Any of the above can be repeated with an arbitrary array-like
instead of just integers. For instance:
>>> aa_milne_arr = ['pooh', 'rabbit', 'piglet', 'Christopher']
>>> np.random.choice(aa_milne_arr, 5, p=[0.5, 0.1, 0.1, 0.3])
... # doctest: +SKIP
array(['pooh', 'pooh', 'pooh', 'Christopher', 'piglet'],
dtype='|S11')
"""
random_state = check_random_state(random_state)
# Format and Verify input
a = np.array(a, copy=False)
if a.ndim == 0:
try:
# __index__ must return an integer by python rules.
pop_size = operator.index(a.item())
except TypeError:
raise ValueError("a must be 1-dimensional or an integer")
if pop_size <= 0:
raise ValueError("a must be greater than 0")
elif a.ndim != 1:
raise ValueError("a must be 1-dimensional")
else:
pop_size = a.shape[0]
if pop_size is 0:
raise ValueError("a must be non-empty")
if p is not None:
p = np.array(p, dtype=np.double, ndmin=1, copy=False)
if p.ndim != 1:
raise ValueError("p must be 1-dimensional")
if p.size != pop_size:
raise ValueError("a and p must have same size")
if np.any(p < 0):
raise ValueError("probabilities are not non-negative")
if not np.allclose(p.sum(), 1):
raise ValueError("probabilities do not sum to 1")
shape = size
if shape is not None:
size = np.prod(shape, dtype=np.intp)
else:
size = 1
# Actual sampling
if replace:
if p is not None:
cdf = p.cumsum()
cdf /= cdf[-1]
uniform_samples = random_state.random_sample(shape)
idx = cdf.searchsorted(uniform_samples, side='right')
# searchsorted returns a scalar
idx = np.array(idx, copy=False)
else:
idx = random_state.randint(0, pop_size, size=shape)
else:
if size > pop_size:
raise ValueError("Cannot take a larger sample than "
"population when 'replace=False'")
if p is not None:
if np.sum(p > 0) < size:
raise ValueError("Fewer non-zero entries in p than size")
n_uniq = 0
p = p.copy()
found = np.zeros(shape, dtype=np.int)
flat_found = found.ravel()
while n_uniq < size:
x = random_state.rand(size - n_uniq)
if n_uniq > 0:
p[flat_found[0:n_uniq]] = 0
cdf = np.cumsum(p)
cdf /= cdf[-1]
new = cdf.searchsorted(x, side='right')
_, unique_indices = np.unique(new, return_index=True)
unique_indices.sort()
new = new.take(unique_indices)
flat_found[n_uniq:n_uniq + new.size] = new
n_uniq += new.size
idx = found
else:
idx = random_state.permutation(pop_size)[:size]
if shape is not None:
idx.shape = shape
if shape is None and isinstance(idx, np.ndarray):
# In most cases a scalar will have been made an array
idx = idx.item(0)
# Use samples as indices for a if a is array-like
if a.ndim == 0:
return idx
if shape is not None and idx.ndim == 0:
# If size == () then the user requested a 0-d array as opposed to
# a scalar object when size is None. However a[idx] is always a
# scalar and not an array. So this makes sure the result is an
# array, taking into account that np.array(item) may not work
# for object arrays.
res = np.empty((), dtype=a.dtype)
res[()] = a[idx]
return res
return a[idx]
def random_choice_csc(n_samples, classes, class_probability=None,
random_state=None):
"""Generate a sparse random matrix given column class distributions
Parameters
----------
n_samples : int,
Number of samples to draw in each column.
classes : list of size n_outputs of arrays of size (n_classes,)
List of classes for each column.
class_probability : list of size n_outputs of arrays of size (n_classes,)
Optional (default=None). Class distribution of each column. If None the
uniform distribution is assumed.
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`.
Returns
-------
random_matrix : sparse csc matrix of size (n_samples, n_outputs)
"""
data = array.array('i')
indices = array.array('i')
indptr = array.array('i', [0])
for j in range(len(classes)):
classes[j] = np.asarray(classes[j])
if classes[j].dtype.kind != 'i':
raise ValueError("class dtype %s is not supported" %
classes[j].dtype)
classes[j] = astype(classes[j], np.int64, copy=False)
# use uniform distribution if no class_probability is given
if class_probability is None:
class_prob_j = np.empty(shape=classes[j].shape[0])
class_prob_j.fill(1 / classes[j].shape[0])
else:
class_prob_j = np.asarray(class_probability[j])
if np.sum(class_prob_j) != 1.0:
raise ValueError("Probability array at index {0} does not sum to "
"one".format(j))
if class_prob_j.shape[0] != classes[j].shape[0]:
raise ValueError("classes[{0}] (length {1}) and "
"class_probability[{0}] (length {2}) have "
"different length.".format(j,
classes[j].shape[0],
class_prob_j.shape[0]))
# If 0 is not present in the classes insert it with a probability 0.0
if 0 not in classes[j]:
classes[j] = np.insert(classes[j], 0, 0)
class_prob_j = np.insert(class_prob_j, 0, 0.0)
# If there are nonzero classes choose randomly using class_probability
rng = check_random_state(random_state)
if classes[j].shape[0] > 1:
p_nonzero = 1 - class_prob_j[classes[j] == 0]
nnz = int(n_samples * p_nonzero)
ind_sample = sample_without_replacement(n_population=n_samples,
n_samples=nnz,
random_state=random_state)
indices.extend(ind_sample)
# Normalize probabilites for the nonzero elements
classes_j_nonzero = classes[j] != 0
class_probability_nz = class_prob_j[classes_j_nonzero]
class_probability_nz_norm = (class_probability_nz /
np.sum(class_probability_nz))
classes_ind = np.searchsorted(class_probability_nz_norm.cumsum(),
rng.rand(nnz))
data.extend(classes[j][classes_j_nonzero][classes_ind])
indptr.append(len(indices))
return sp.csc_matrix((data, indices, indptr),
(n_samples, len(classes)),
dtype=int)
共有2个答案

你可以试试NumSharp,numpy到C#的端口
double[] distribution = new double[] { 0.1, 0.2, 0.3, 0.4 };
//Simple choice
for (int i = 0; i < 80; i++)
{
int choice = NumSharp.np.random.choice(distribution.Count(), probabilities:distribution)[0].GetInt32();
Console.Write(choice.ToString());
}
Console.WriteLine();
12222312301223333323323223022211111233123323333133211233333233013312213033030033
NumSharp包括ditiononal参数(替换,...),但迄今为止,性能问题仍然存在:
EvalTime("NumSharp Single thread",() =>
{
for (int i = 0; i < 100000; i++)
NumSharp.np.random.choice(distribution.Count(), probabilities: distribution)[0].GetInt32();
});
EvalTime("NumSharp Multithread", () =>
{
Parallel.For(0, 100000, i =>
NumSharp.np.random.choice(distribution.Count(), probabilities: distribution)[0].GetInt32());
});
EvalTime("Evk Single thread", () =>
{
for (int i = 0; i < 100000; i++)
Choice(upTo: distribution.Count(), distribution: distribution);
});
EvalTime("Evk Multithread", () =>
{
Parallel.For(0, 100000, i =>
Choice(upTo: distribution.Count(), distribution: distribution));
});
public static void EvalTime(string Name,Action a)
{
Stopwatch sw = new Stopwatch();
sw.Start();
a();
sw.Stop();
Console.WriteLine("{0} : {1}ms", Name,sw.ElapsedMilliseconds);
}
下面是比较NumSharp和Evk在我的PC上的实现的输出(24个逻辑核)
NumSharp Single thread : 10701ms
NumSharp Multithread : 19350ms
Evk Single thread : 117ms
Evk Multithread : 61ms

如果我没弄错的话——你想根据double数组给出的分布概率,从Y个元素的列表中随机选择X个元素,其中每个元素代表返回相同索引的元素的概率。我能想到的最直接的方法是(见评论):
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading;
static readonly ThreadLocal<Random> _random = new ThreadLocal<Random>(() => new Random());
static IEnumerable<T> Choice<T>(IList<T> sequence, int size, double[] distribution) {
double sum = 0;
// first change shape of your distribution probablity array
// we need it to be cumulative, that is:
// if you have [0.1, 0.2, 0.3, 0.4]
// we need [0.1, 0.3, 0.6, 1 ] instead
var cumulative = distribution.Select(c => {
var result = c + sum;
sum += c;
return result;
}).ToList();
for (int i = 0; i < size; i++) {
// now generate random double. It will always be in range from 0 to 1
var r = _random.Value.NextDouble();
// now find first index in our cumulative array that is greater or equal generated random value
var idx = cumulative.BinarySearch(r);
// if exact match is not found, List.BinarySearch will return index of the first items greater than passed value, but in specific form (negative)
// we need to apply ~ to this negative value to get real index
if (idx < 0)
idx = ~idx;
if (idx > cumulative.Count - 1)
idx = cumulative.Count - 1; // very rare case when probabilities do not sum to 1 becuase of double precision issues (so sum is 0.999943 and so on)
// return item at given index
yield return sequence[idx];
}
}
我很难用通俗易懂的语言来解释这一点,但我认为从代码来看应该是比较明显的。也许用例子来解释是最容易的。假设我们有分布[0.1,0.4,0.4,0.1]。累积版本(当我们将之前所有项目的总和添加到当前项目中时)将如下所示:[0.1,0.5,0.9,1]。现在我们生成0到1范围内的随机数。任何值都可能是均匀分布。在0-0.1范围内的概率是多少?0.1. 在0.1-0.5范围内?0.4. 所以你们可以看到,概率均匀分布的0-1数将在给定的范围内,和我们在概率分布数组中得到的完全相同。
这样使用:
var result = Choice(Enumerable.Range(0, 5).ToArray(), 3, new double[] {0.01, 0.01, 0.48, 0.48, 0.02}).ToArray();
将导致:
[3,3,3] //
[2,3,2] // most often result with contain 2 and 3, because they both have 0.48 probablity and the rest elements have just 0.01
[1,3,2] // very rare other elements will appear
如果你需要不重复的版本,也可以对代码稍加修改。
如果您需要一个项目,请使用size=1调用上述函数,或创建重载以方便使用。如果要传递单个整数而不是序列,则相同:
static T Choice<T>(IList<T> sequence, double[] distribution) {
return Choice(sequence, 1, distribution).First();
}
static int Choice(int upTo, double[] distribution) {
return Choice(Enumerable.Range(0, upTo).ToArray(), distribution);
}
-
问题内容: 我知道如果我使用Java的Random生成器,并使用nextInt生成数字,则数字将均匀分布。但是,如果我使用2个Random实例,并使用两个Random类生成数字,会发生什么。数字是否会均匀分布? 问题答案: 每个实例生成的数字将均匀分布,因此,如果将两个实例生成的随机数序列组合在一起,则它们也应均匀分布。 请注意,即使结果分布是均匀的,您也可能要注意种子,以避免两个生成器的输出之间
-
问题内容: 我试图识别/创建一个函数(在Java中),该函数给我一个非均匀的分布式数字序列。如果我有一个函数说它将给我一个从到的随机数。 该函数最适合任何给定的函数,下面仅是我想要的示例。 但是,如果我们说函数将返回来自分布式的s nonuni。 我想例如说 约占所有案件的20%。 大约是所有情况的50%。 约占所有案件的20%。 大约是所有情况的10。 总之somting,给我一个数字,如正态分
-
0.1-0.2:********** 0.2-0.3:******** 0.3-0.4:********* 0.5-0.6:********* 0.6-0.7:********* 0.7-0.8:********* 0.4-0.5:********* 0.5-0.6:********* 0.6-0.7:********* 0.1-0.2:********* 0.2-0.3:********* 0.
-
我试图找到一种有效的算法来生成一个给定节点数的简单连通图。类似于:
-
问题内容: 您能告诉我任何生成非均匀随机数的方法吗? 我正在使用Java,但是代码示例可以随心所欲。 一种方法是通过将两个统一的随机数加在一起(即滚动2个骰子)来创建歪斜分布。 问题答案: 您想要什么分布的偏差? 这是一种始终有效的技术,但并不总是最有效的。累积扰动函数P(x)给出值低于x的时间的分数。因此,在x的最小可能值处P(x)= 0,在x的最大可能值处P(x)= 1。每个分布都有一个唯一的
-
问题内容: 我想要一个集合,并且其元素具有与之关联的概率,因此当我从集合中随机选择一个元素时,分布遵循与元素关联的概率。我想在一个非常小的Java应用程序中使用它,该应用程序存储了我要观看的电影列表,因此我可以向我推荐一部随机电影(否则我总是要花几个小时才能挑选一部电影)。对于每部电影,我都希望将向其推荐电影的次数与该电影的推荐次数成反比,该次数与从该列表中为下一个建议中挑选电影的可能性成反比。