
1.16. 概率校准
校验者: @曲晓峰 @小瑶 翻译者: @那伊抹微笑
执行分类时, 您经常希望不仅可以预测类标签, 还要获得相应标签的概率. 这个概率给你一些预测的信心. 一些模型可以给你贫乏的概率估计, 有些甚至不支持概率预测. 校准模块可以让您更好地校准给定模型的概率, 或添加对概率预测的支持.
精确校准的分类器是概率分类器, 其可以将 predict_proba 方法的输出直接解释为 confidence level(置信度级别). 例如,一个经过良好校准的(二元的)分类器应该对样本进行分类, 使得在给出一个接近 0.8 的 prediction_proba 值的样本中, 大约 80% 实际上属于正类. 以下图表比较了校准不同分类器的概率预测的良好程度:
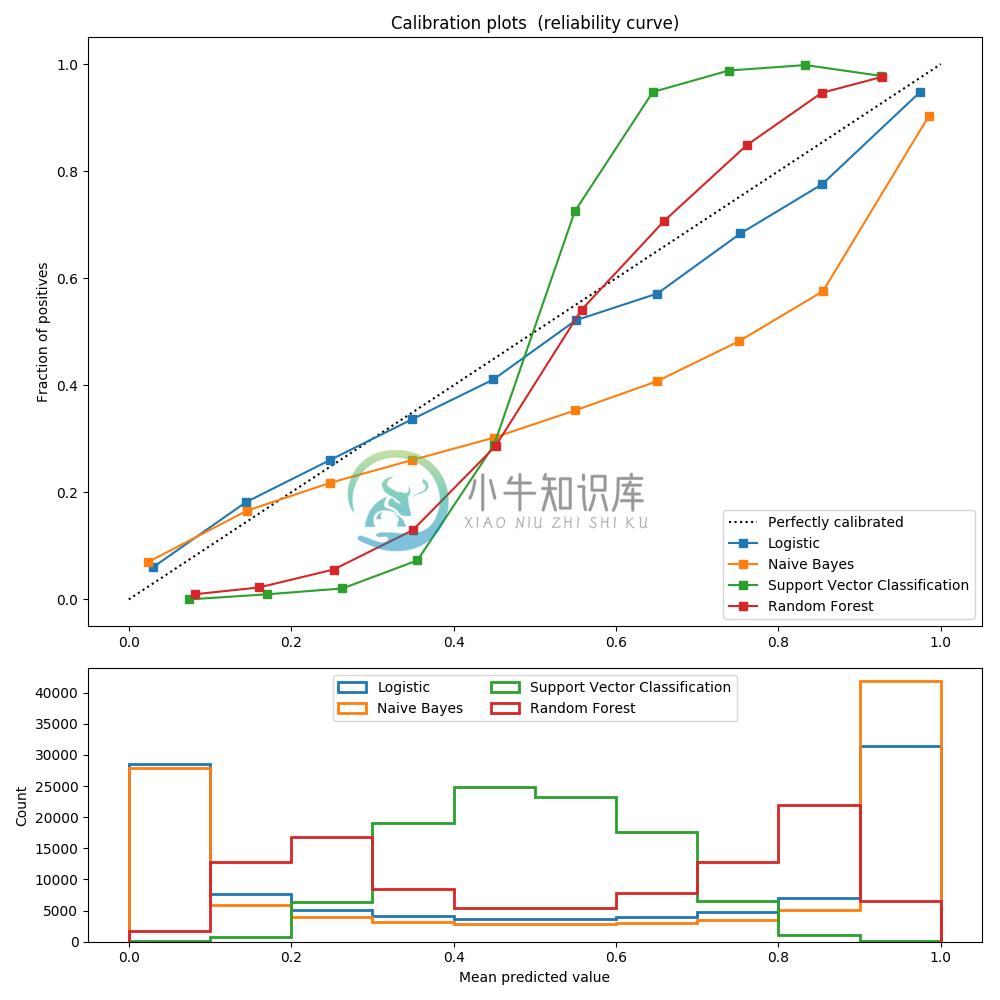
LogisticRegression 默认情况下返回良好的校准预测, 因为它直接优化了 log-loss(对数损失)情况. 相反,其他方法返回 biased probabilities(偏倚概率); 每种方法有不同的偏差:
GaussianNB往往将概率推到 0 或 1(注意直方图中的计数). 这主要是因为它假设特征在给定类别的条件下是独立的, 在该数据集中不包含 2 个冗余特征.RandomForestClassifier解释了相反的行为:直方图在约 0.2 和 0.9 的概率时显示峰值, 而接近 0 或 1 的概率非常罕见. Niculescu-Mizil 和 Caruana [4] 给出了一个解释:”诸如 bagging 和 random forests(随机森林)的方法, 从基本模型的平均预测中可能难以将预测置于 0 和 1 附近, 因为基础模型的变化会偏离预测值, 它们应该接近于零或偏离这些值, 因为预测被限制在 [0,1] 的间隔, 由方差引起的误差往往是靠近 0 和 1 的一边, 例如,如果一个模型应该对于一个案例,预测 p = 0,bagging 可以实现的唯一方法是假设所有的 bagging 树预测为零. 如果我们在 bagging 树上增加噪声, 这种噪声将导致一些树预测大于 0 的值, 因此将 bagging 的平均预测从 0 移开. 我们用随机森林最强烈地观察到这种效应, 因为用随机森林训练的 base-level 树由于特征划分而具有相对较高的方差. 因此,校准曲线也被称为可靠性图 (Wilks 1995 [5] _) 显示了一种典型的 sigmoid 形状, 表明分类器可以更多地信任其 “直觉”, 并通常将接近 0 或 1 的概率返回.线性支持向量分类 (
LinearSVC) 显示了作为 RandomForestClassifier 更多的 Sigmoid 曲线, 这是经典的最大边距方法 (compare Niculescu-Mizil and Caruana 4(#id3)), 其重点是靠近决策边界的 hard samples(支持向量).
提供了执行概率预测校准的两种方法: 基于 Platt 的 Sigmoid 模型的参数化方法和基于 isotonic regression(保序回归)的非参数方法 (sklearn.isotonic). 对于不用于模型拟合的新数据, 应进行概率校准. 类 CalibratedClassifierCV 使用交叉验证生成器, 并对每个拆分模型参数对训练样本和测试样本的校准进行估计. 然后对折叠预测的概率进行平均. 已经安装的分类器可以通过:class:<cite>CalibratedClassifierCV</cite> 传递参数 cv =”prefit” 这种方式进行校准. 在这种情况下, 用户必须手动注意模型拟合和校准的数据是不相交的.
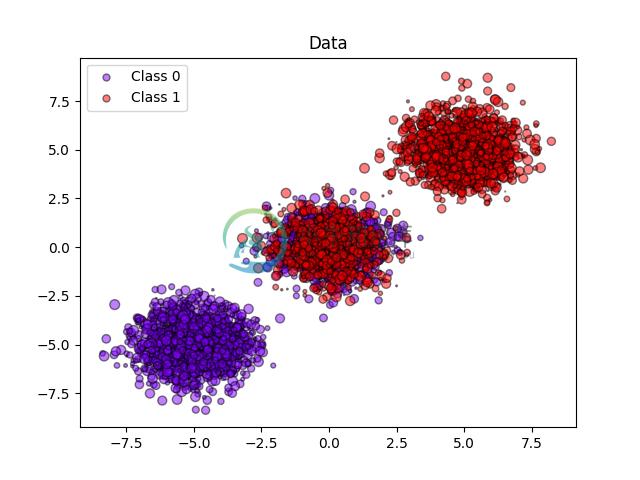
以下图像展示了概率校准的好处. 第一个图像显示一个具有 2 个类和 3 个数据块的数据集. 中间的数据块包含每个类的随机样本. 此数据块中样本的概率应为 0.5.
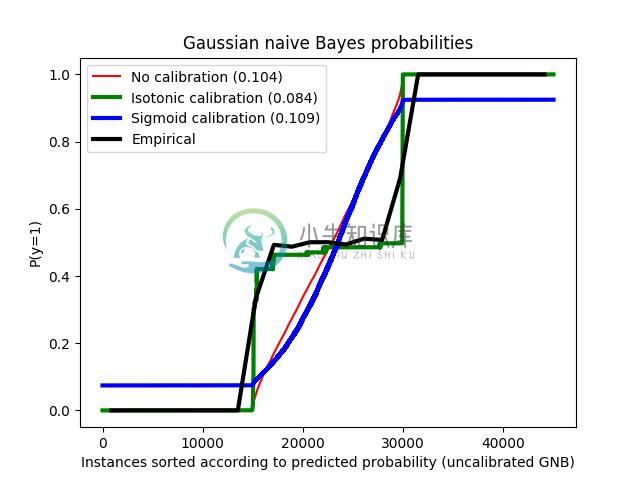
以下图像使用没有校准的高斯朴素贝叶斯分类器, 使用 sigmoid 校准和非参数的等渗校准来显示上述估计概率的数据. 可以观察到, 非参数模型为中间样本提供最准确的概率估计, 即0.5.
对具有20个特征的100.000个样本(其中一个用于模型拟合)进行二元分类的人造数据集进行以下实验. 在 20个 特征中,只有 2 个是信息量, 10 个是冗余的. 该图显示了使用逻辑回归获得的估计概率, 线性支持向量分类器(SVC)和具有 sigmoid 校准和 sigmoid 校准的线性 SVC. 校准性能使用 Brier score brier_score_loss 来计算, 请看下面的图例(越销越好).
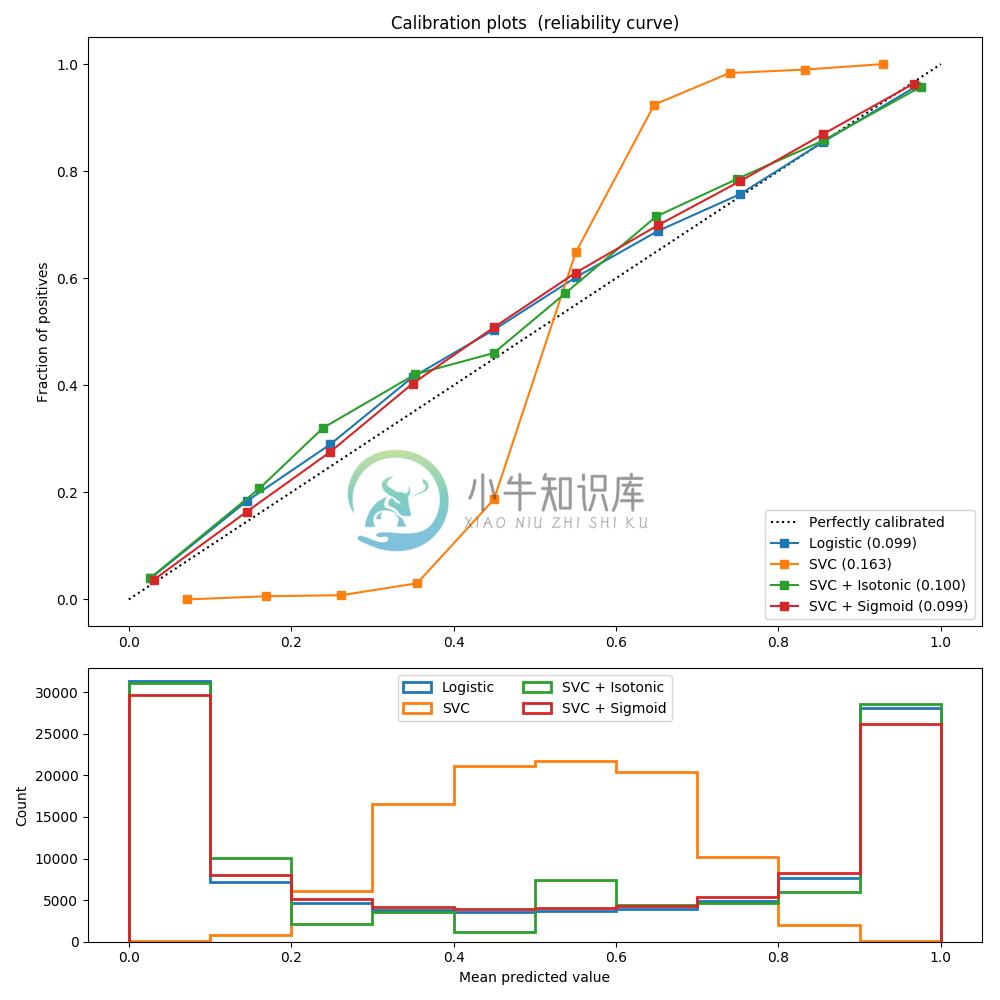
这里可以观察到, 逻辑回归被很好地校准, 因为其曲线几乎是对角线. 线性 SVC 的校准曲线或可靠性图具有 sigmoid 曲线, 这是一个典型的不够自信的分类器. 在 LinearSVC 的情况下, 这是 hinge loss 的边缘属性引起的, 这使得模型集中在靠近决策边界(支持向量)的 hard samples(硬样本)上. 这两种校准都可以解决这个问题, 并产生几乎相同的结果. 下图显示了高斯朴素贝叶斯在相同数据上的校准曲线, 具有两种校准, 也没有校准.
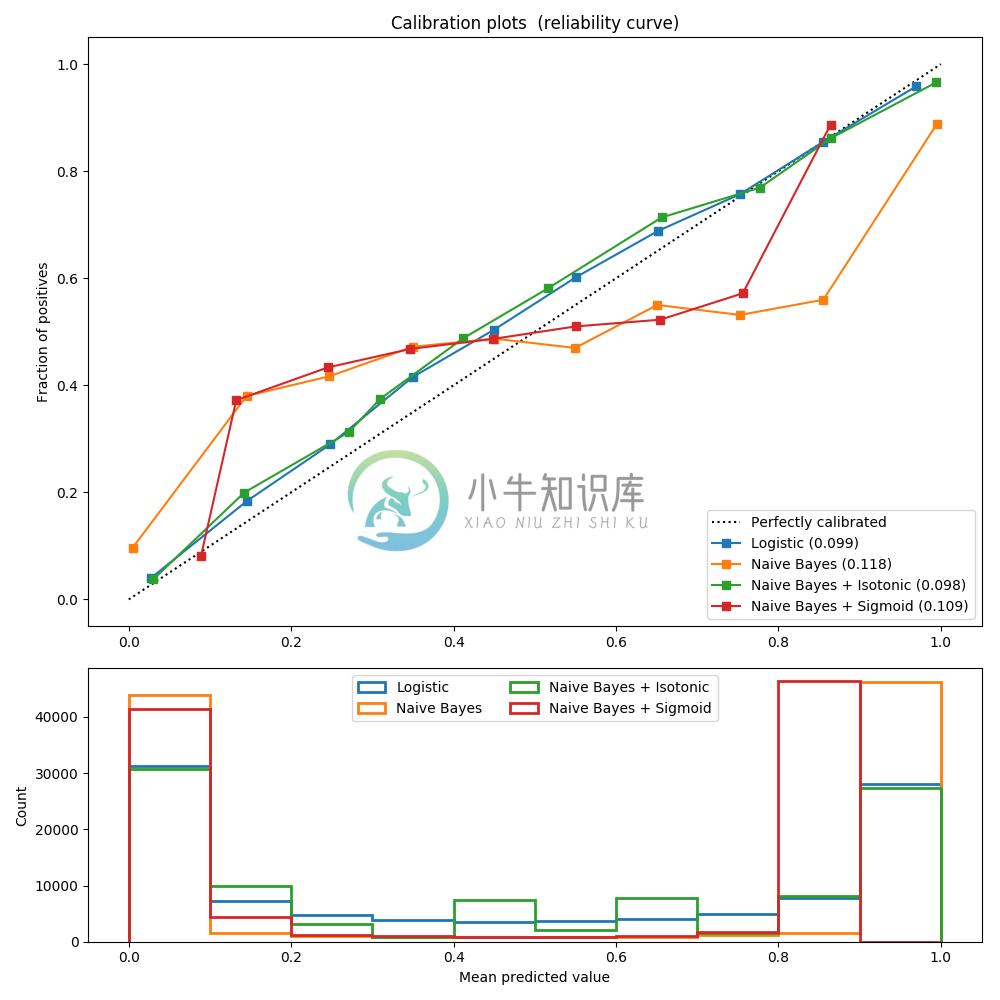
可以看出, 高斯朴素贝叶斯的表现非常差, 但是以线性 SVC 的方式也是如此. 尽管线性 SVC 显示了 sigmoid 校准曲线, 但高斯朴素贝叶斯校准曲线具有转置的 sigmoid 结构. 这对于过分自信的分类器来说是非常经典的. 在这种情况下,分类器的过度自信是由违反朴素贝叶斯特征独立假设的冗余特征引起的.
用等渗回归法对高斯朴素贝叶斯概率的校准可以解决这个问题, 从几乎对角线校准曲线可以看出. Sigmoid 校准也略微改善了 brier 评分, 尽管不如非参数等渗校准那样强烈. 这是 sigmoid 校准的固有限制,其参数形式假定为 sigmoid ,而不是转置的 sigmoid 曲线. 然而, 非参数等渗校准模型没有这样强大的假设, 并且可以处理任何形状, 只要有足够的校准数据. 通常,在校准曲线为 sigmoid 且校准数据有限的情况下, sigmoid 校准是优选的, 而对于非 sigmoid 校准曲线和大量数据可用于校准的情况,等渗校准是优选的.
CalibratedClassifierCV 也可以处理涉及两个以上类的分类任务, 如果基本估计器可以这样做的话. 在这种情况下, 分类器是以一对一的方式分别对每个类进行校准. 当预测未知数据的概率时, 分别预测每个类的校准概率. 由于这些概率并不总是一致, 因此执行后处理以使它们归一化.
下一个图像说明了 Sigmoid 校准如何改变 3 类分类问题的预测概率. 说明是标准的 2-simplex,其中三个角对应于三个类. 箭头从未校准分类器预测的概率向量指向在保持验证集上的 sigmoid 校准之后由同一分类器预测的概率向量. 颜色表示实例的真实类(red: class 1, green: class 2, blue: class 3).
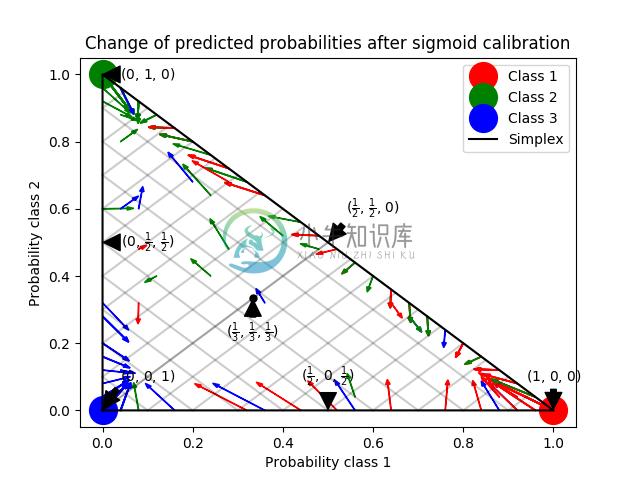
基础分类器是具有 25 个基本估计器(树)的随机森林分类器. 如果这个分类器对所有 800 个训练数据点进行了训练, 那么它的预测过于自信, 从而导致了大量的对数损失. 校准在 600 个数据点上训练的相同分类器, 其余 200 个数据点上的 method =’sigmoid’ 减少了预测的置信度, 即将概率向量从单面的边缘向中心移动:
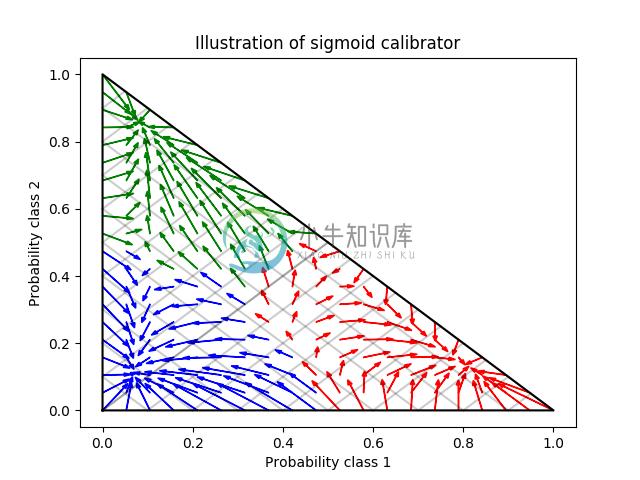
该校准导致较低的 log-loss(对数损失). 请注意,替代方案是增加基准估计量的数量, 这将导致对数损失类似的减少.
参考:
- Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers, B. Zadrozny & C. Elkan, ICML 2001
- Transforming Classifier Scores into Accurate Multiclass Probability Estimates, B. Zadrozny & C. Elkan, (KDD 2002)
- Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods, J. Platt, (1999)
| 4(#id2) | Predicting Good Probabilities with Supervised Learning, A. Niculescu-Mizil & R. Caruana, ICML 2005 |
| [5] | On the combination of forecast probabilities for consecutive precipitation periods. Wea. Forecasting, 5, 640–650., Wilks, D. S., 1990a |