
7. 计算性能
校验者: @曲晓峰 @小瑶 翻译者: @小瑶
对于某些 applications (应用),estimators(估计器)的性能(主要是 prediction time (预测时间)的 latency (延迟)和 throughput (吞吐量))至关重要。考虑 training throughput (训练吞吐量)也可能是有意义的,但是在 production setup (生产设置)(通常在脱机中运行)通常是不太重要的。
我们将在这里审查您可以从不同上下文中的一些 scikit-learn estimators(估计器)预期的数量级,并提供一些 overcoming performance bottlenecks (解决性能瓶颈)的技巧和诀窍。
将 Prediction latency (预测延迟)作为进行预测所需的 elapsed time (经过时间)(例如,以 micro-seconds(微秒)为单位)进行测量。Latency (延迟)通常被认为一种分布,运营工程师通常将注意力集中在该分布的给定 percentile (百分位数)(例如 90 百分位数)上的延迟。
Prediction throughput (预测吞吐量)被定义为软件可以在给定的时间量内(例如每秒的预测)中 the number of predictions (可预测的预测数)。
performance optimization (性能优化)的一个重要方面也是它可能会损害 prediction accuracy (预测精度)。 实际上,更简单的模型(例如 linear (线性的),而不是 non-linear (非线性的),或者具有较少的参数)通常运行得更快,但并不总是能够考虑与更复杂的数据相同的确切属性。
7.1. 预测延迟
在使用/选择机器学习工具包时可能遇到的最直接的问题之一是生产环境中可以进行预测的 latency (延迟)。
影响 prediction latency (预测延迟)的主要因素是
- Number of features(特征的数量)
- Input data representation and sparsity(输入数据的表示和稀疏性)
- Model complexity(模型复杂性)
- Feature extraction(特征提取)
最后一个主要参数也是在 bulk or one-at-a-time mode (批量或执行一次的时间模式)下进行预测的可能性。
7.1.1. 批量与原子模式
通常,通过大量原因(branching predictability(分支可预测性), CPU cache(CPU缓存), linear algebra libraries optimizations(线性代数库优化)等),predictions in bulk(批量进行预测)(同时许多情况)更有效。 在这里,我们看到一些具有很少功能的设置,独立于估计器选择,bulk mode(批量模式)总是更快,而对于其中的一些,它们的数量大约是 1 到 2 个数量级:
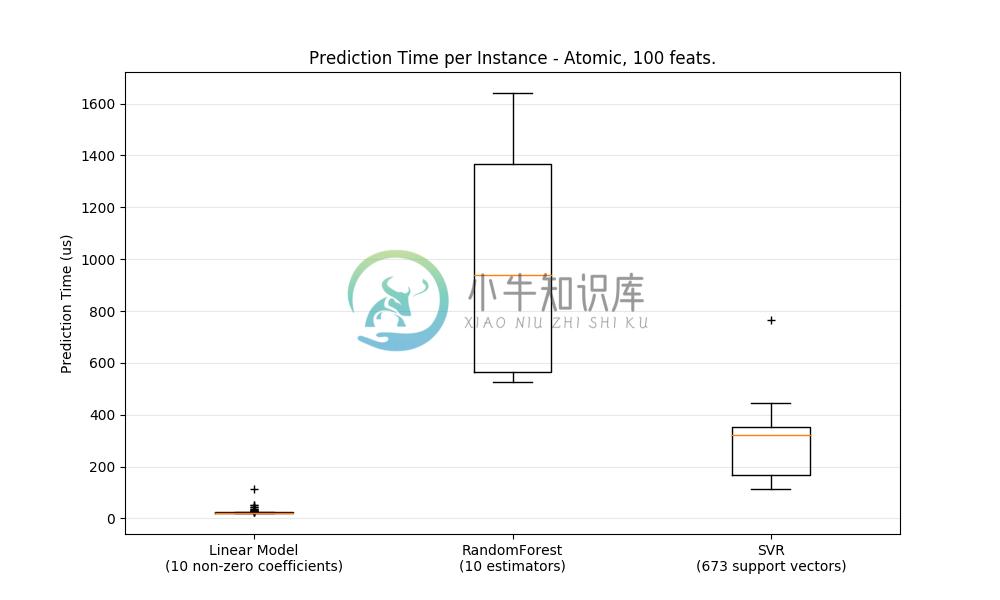
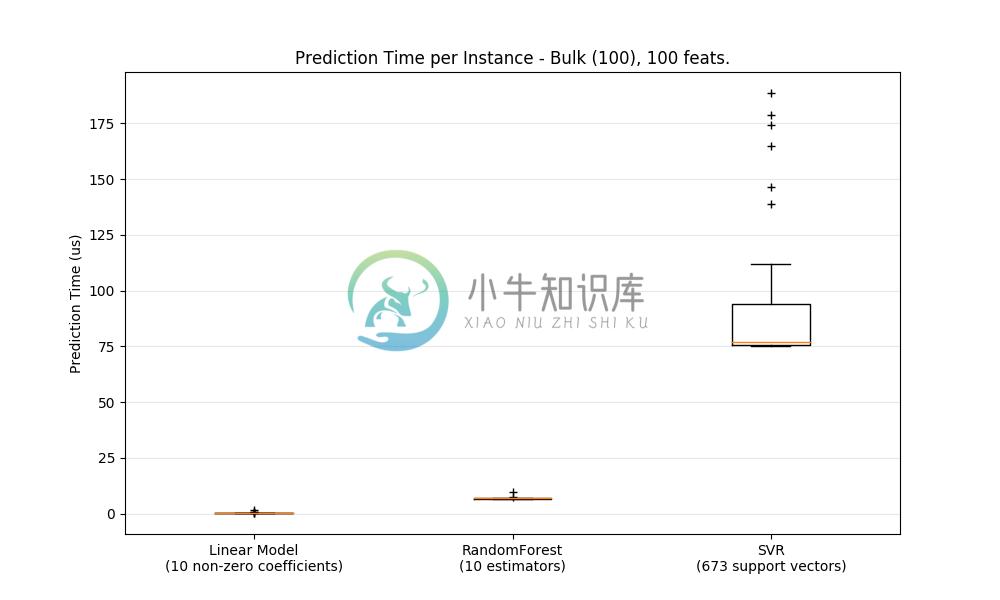
为了对您的案例的不同的 estimators 进行基准测试,您可以在此示例中简单地更改 n_features 参数: Prediction Latency. 这应该给你估计 prediction latency (预测延迟)的数量级。
配置 Scikit-learn 来减少验证开销
Scikit-learn 对数据进行了一些验证,从而增加了对 predict(预测) 和类似函数的调用开销。特别地,检查这些 features (特征)是有限的(不是 NaN 或无限)涉及对数据的完全传递。如果您确定你的数据是 acceptable (可接受的),您可以通过在导入 scikit-learn 之前将环境变量配置 SKLEARN_ASSUME_FINITE 设置为 non-empty string (非空字符串)来抑制检查有限性,或者使用以下方式在 Python 中配置 sklearn.set_config 。为了比这些全局设置更多的控制 config_context 允许您在指定的上下文中设置此配置:
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # do learning/prediction here with reduced validation
注意,这将影响上下文中的 sklearn.utils.assert_all_finite 的所有用途。
7.1.2. 特征数量的影响
显然,当特征数量增加时,每个示例的内存消耗量也会增加。实际上,对于具有 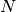 个特征的
个特征的 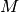 个实例的矩阵,空间复杂度在
个实例的矩阵,空间复杂度在 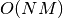 。
。
从 computing (计算)角度来看,这也意味着 the number of basic operations (基本操作的数量)(例如,线性模型中向量矩阵乘积的乘法)也增加。以下是 prediction latency (预测延迟)与 number of features(特征数) 的变化图:
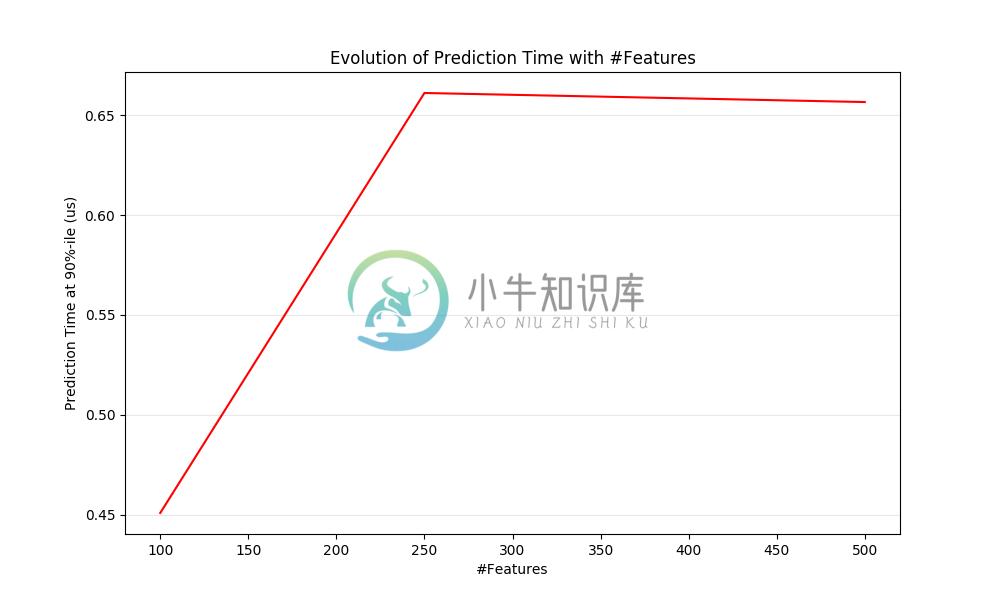
总的来说,您可以预期 prediction time (预测时间)至少随 number of features (特征数量)线性增加(非线性情况可能会发生,取决于 global memory footprint (全局内存占用)和 estimator (估计))。
7.1.3. 输入数据表示的影响
Scipy 提供对 storing sparse data(存储稀疏数据)进行优化的 sparse matrix (稀疏矩阵)数据结构。sparse formats(稀疏格式)的主要特点是您不会存储零,所以如果您的数据稀疏,那么您使用的内存会更少。sparse(稀疏) (CSR or CSC) 表示中的非零值将仅占用一个 32 位整数位置 + 64 位 floating point (浮点值) + 矩阵中每行或列的额外的 32 位。在 dense(密集) (or sparse(稀疏)) 线性模型上使用稀疏输入可以加速预测,只有非零值特征才会影响点积,从而影响模型预测。因此,如果在 1e6 维空间中有 100 个非零,则只需要 100 次乘法和加法运算而不是 1e6 。
然而,密度表示的计算可以利用 BLAS 中高度优化的向量操作和多线程,并且往往导致更少的 CPU 高速缓存 misses 。因此,sparse input (稀疏输入)表示的 sparsity (稀疏度)通常应相当高(10% 非零最大值,要根据硬件进行检查)比在具有多个 CPU 和优化 BLAS 实现的机器上的 dense input (密集输入)表示更快。
以下是测试输入 sparsity (稀疏度)的示例代码:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
根据经验,您可以考虑如果 sparsity ratio (稀疏比)大于 90% , 您可能会从 sparse formats (稀疏格式)中受益。有关如何构建(或将数据转换为) sparse matrix formats (稀疏矩阵格式)的更多信息,请参阅 Scipy 的稀疏矩阵格式文档 documentation 。大多数的时候, CSR 和 CSC 格式是最有效的。
7.1.4. 模型复杂度的影响
一般来说,当 model complexity (模型复杂度)增加时,predictive power (预测能力)和 latency (延迟)应该会增加。增加 predictive power (预测能力)通常很有意思,但对于许多应用,我们最好不要太多地增加预测延迟。我们现在将对不同 families 的 supervised models (监督模式)进行审查。
对于 sklearn.linear_model (例如 Lasso, ElasticNet, SGDClassifier/Regressor, Ridge & RidgeClassifier, PassiveAgressiveClassifier/Regressor, LinearSVC, LogisticRegression…) 在预测时间应用的 decision function (决策函数)是一样的(dot product( 点积)),所以 latency (延迟)应该是等效的。
这里有一个例子使用 sklearn.linear_model.stochastic_gradient.SGDClassifier 和 elasticnet penalty(惩罚)。 regularization strength(正则化强度)由 alpha 参数全局控制。有一个足够高的 alpha ,可以增加 elasticnet 的 l1_ratio 参数,以在模型参数中执行各种稀疏程度。这里的 Higher sparsity (较高稀疏度)被解释为 less model complexity (较少的模型复杂度),因为我们需要较少的系数充分描述它。当然, sparsity (稀疏性)会随着稀疏点积 产生时间大致与非零系数的数目成比例地影响 prediction time (预测时间)。
对于具有 non-linear kernel (非线性内核)的 sklearn.svm 算法系列,latency (延迟)与 support vectors (支持向量)的数量有关(越少越快)。 随着 SVC 或 SVR 模型中的支持向量的数量, Latency (延迟)和 throughput (吞吐量)应该渐渐地增长。kernel (内核)也将影响 latency (延迟),因为它用于计算每个 support vector (支持向量)一次 input vector(输入向量)的 projection (投影)。在下面的图中, sklearn.svm.classes.NuSVR 的 nu 参数用于影响 number of support vectors(支持向量的数量)。
对于 sklearn.ensemble 的 trees (例如 RandomForest, GBT, ExtraTrees 等) number of trees (树的数量)及其 depth(深度)发挥着最重要的作用。Latency and throughput(延迟和吞吐量)应与树的数量呈线性关系。在这种情况下,我们直接使用 sklearn.ensemble.gradient_boosting.GradientBoostingRegressor 的 n_estimators 参数。
在任何情况下都应该警告,降低的 model complexity (模型复杂性)可能会损害如上所述的准确性。例如,可以用快速线性模型来处理 non-linearly separable problem (非线性可分离问题),但是在该过程中预测能力将很可能受到影响。
7.1.5. 特征提取延迟
大多数 scikit-learn 模型通常非常快,因为它们可以通过编译的 Cython 扩展或优化的计算库来实现。 另一方面,在许多现实世界的应用中,feature extraction process(特征提取过程)(即,将 database rows or network packets (数据库行或网络分组)的原始数据转换为 numpy arrays )来控制总体预测时间。例如在 Reuters text classification task(路透社文本分类任务)中,根据所选择的模型,整个准备(读取和解析 SGML 文件,将文本进行标记并将其散列为公共向量空间)的时间比实际预测代码的时间长 100 到 500 倍。
因此,在很多情况下,建议您仔细地对 carefully time and profile your feature extraction code ( 特征提取代码进行时间预估和简档),因为当您的 overall latency (整体延迟)对您的应用程序来说太慢时,可能是开始优化的好地方。
7.2. 预测吞吐量
考虑到生产系统大小的另一个重要指标是 throughput (吞吐量),即在一定时间内可以做出的预测数量。以下是 Prediction Latency 示例的基准测试,该示例针对合成数据的多个 estimators (估计器)测量此数量:
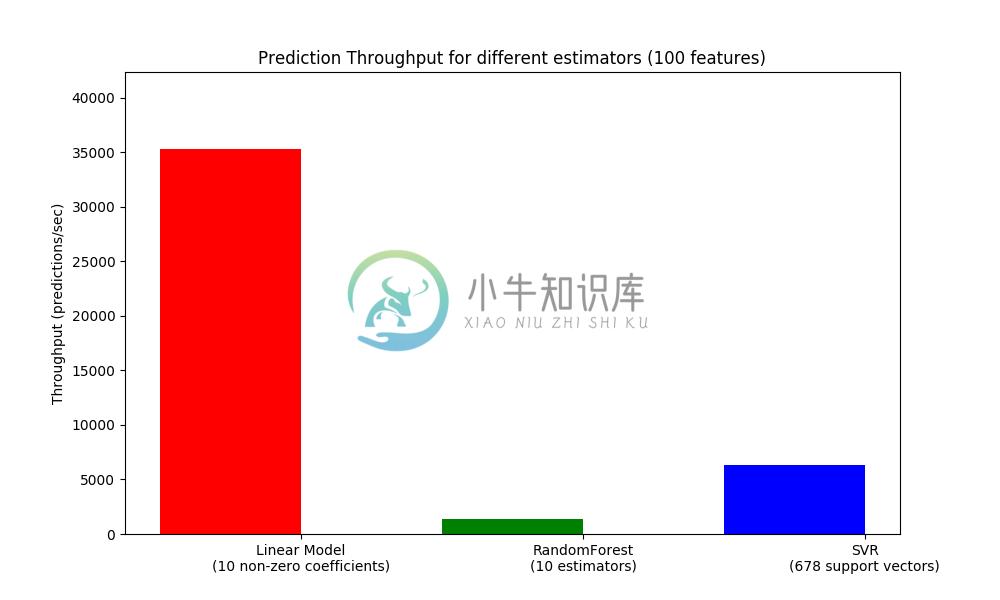
这些 throughputs(吞吐量)早单个进程上实现。提高应用程序吞吐量的一个明显的方法是产生其他实例(通常是 Python 中的进程,因为 GIL )共享相同模型。还可能添加机器来分布式负载。关于如何实现这一点的详细解释超出了本文档的范围。
7.3. 技巧和窍门
7.3.1. 线性代数库
由于 scikit-learn 在很大程度上依赖于 Numpy/Scipy 和 线性代数,所以需要理解这些库的版本。 基本上,你应该确保使用优化的 BLAS / LAPACK 构建 Numpy 库。
并非所有的模型都受益于优化的 BLAS 和 Lapack 实现。例如,基于(随机化)决策树的模型通常不依赖于内部循环中的 BLAS 调用,kernel SVMs (SVC, SVR, NuSVC, NuSVR) 。另一方面,使用 BLAS DGEMM 调用(通过 numpy.dot)实现的线性模型通常将受益于调整的 BLAS 实现,并且导致非优化 BLAS 的数量级加速。
你可以使用以下命令显示您的 NumPy / SciPy / scikit-learn 安装使用的 BLAS / LAPACK 实现:
from numpy.distutils.system_info import get_info
print(get_info('blas_opt'))
print(get_info('lapack_opt'))
Optimized(优化的) BLAS / LAPACK 实现包括:
- Atlas (需要通过在目标机器上 rebuilding 进行硬件特定调整)
- OpenBLAS
- MKL
- Apple Accelerate 和 vecLib frameworks (仅适用于 OSX)
有关更多信息,请参见 Scipy install page 并在来自 Daniel Nouri 的博客 blog post 它为 Debain / Ubuntu 提供了一些很好的一步一步的安装说明。
Warning
Multithreaded BLAS libraries(多线程 BLAS 库)有时与 Python 的 multiprocessing 模块相冲突,这个模块由例如 GridSearchCV 和大多数其他估计器,它们使用 n_jobs 参数(除了 SGDClassifier, SGDRegressor, Perceptron, PassiveAggressiveClassifier 和 基于树的方法如 random forests(随机森林))。在 OpenMP 支持的情况下, Apple 的 Accelerate 和 OpenBLAS 也是如此。
除了 scikit-learn, Numpy 和 Scipy 也在内部使用 BLAS, 如上所述。
如果您遇到带有 n_jobs>1 或 n_jobs=-1 的 hanging subprocesses (挂起子进程),请确保你有一个单线程 BLAS 库,或者设置 n_jobs=1 或者升级到 Python 3.4 有一个新版本的 multiprocessing ,应该免于这个问题。
7.3.2. 模型压缩
scikit-learn 中的 Model compression (模型压缩)只关注 linear models (线性模型)。 在这种情况下,这意味着我们要控制模型 sparsity (稀疏度)(即 模型向量中的非零坐标数)。将 model sparsity (模型稀疏度)与 sparse input data representation (稀疏输入数据表示)相结合是一个好主意。
以下是示例代码,说明了如何使用 sparsify() 方法:
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
在这个例子中,我们更喜欢 elasticnet penalty(惩罚),因为它通常是 model compactness(模型紧凑性)和 prediction power (预测能力)之间的一个很好的妥协。还可以进一步调整 l1_ratio 参数(结合正则化强度 alpha )来控制这个权衡。
对于 synthetic data (合成数据),典型的 benchmark 在模型和输入时都会降低 30% 的延迟。稀疏(分别为 0.000024 和 0.027400 非零系数比)。您的里程可能会因您的数据和模型的稀疏性和大小而有所不同。 因此,为了减少部署在生产服务器上的预测模型的内存使用,扩展可能非常有用。
7.3.3. 模型重塑
Model reshaping(模型重塑)在于仅选择一部分可用功能以适应模型。换句话说,如果模型在学习阶段 discards features (丢弃特征),我们可以从输入中删除这些特征。这有几个好处。首先,它减少了模型本身的内存(因此是减少了时间)的开销。一旦知道要从上一次运行中保留哪些功能,它也允许在 pipeline 中 discard explicit feature selection components (丢弃显式的特征选择组件)。最后,它可以通过不收集和构建模型丢弃的特征来帮助减少数据访问和 feature extraction layers (特征提取层)upstream (上游)的处理时间和 I/O 的使用。例如,如果原始数据来自数据库,则可以通过使查询返回较轻的记录,从而可以编写更简单和更快速的查询或减少 I/O 的使用。 目前,reshaping(重塑)需要在 scikit-learn 中手动执行。 在 sparse input(稀疏输入)(特别是 CSR 格式)的情况下,通常不能生成相关的特征,使其列为空。
7.3.4. 链接
- scikit-learn developer performance documentation
- Scipy sparse matrix formats documentation