
Hyperopt-sklearn是基于scikit-learn项目的一个子集,其全称是:Hyper-parameter optimization for scikit-learn,即针对scikit-learn项目的超级参数优化工具。由于scikit-learn是基于Python的机器学习开源框架,因此Hyperopt-sklearn也基于Python语言。
Hyperopt-sklearn的文档称:对于开发者而言,针对不同的训练数据挑选一个合适的分类器(classifier)通常是困难的。而且即使选好了分类器,后面的参数调试过程也相当乏味和耗时。更严重的是,还有许多情况是开发者好不容易调试好了选定的分类器,却发现一开始的选择本身就是错误的,这本身就浪费了大量的精力和时间。针对该问题,Hyperopt-sklearn提供了一种解决方案。
Hyperopt-sklearn支持各种不同的搜索算法(包括随机搜索、Tree of Parzen Estimators、Annealing等),可以搜索所有支持的分类器(KNeightborsClassifier、KNeightborsClassifier、SGDClassifier等)或者在给定的分类器下搜索所有可能的参数配置,并评估最优选择。并且Hyperopt-sklearn还支持多种预处理流程,包括TfidfVectorizer,Normalzier和OneHotEncoder等。
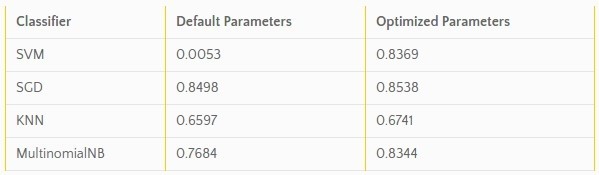
那么Hyperopt-sklearn的实际效果究竟如何?下表分别展示了使用scikit-learn默认参数和Hyperopt-sklearn优化参数运行的分类器的F-score分数,数据源来自20个不同的新闻组稿件。可以看到,经过优化的分类器的平均得分都要高于默认参数的情况。
另外,Hyperopt-sklearn的编码量也很小,并且维护团队还提供了丰富的参考样例。
-
第五章:Hyperopt-Sklearn 摘要 Hyperopt-sklearn 是一个软件项目,可提供 Scikit-learn 机器学习库的自动算法配置。遵循对 Auto-Weka 的介绍,我们认为分类器的选择甚至预处理模块的选择可以一起代表一个大的超参数优化问题。我们使用 Hyperopt 定义一个搜索空间,其中包含许多标准组件(例如 SVM,RF,KNN,PCA,TFIDF)以及将它们组合
-
针对特定的数据集选择合适的机器学习算法是冗长的过程,即使是针对特定的机器学习算法,亦需要花费大量时间和精力调整参数,才能让模型获得好的效果,Hyperopt-sklearn可以辅助解决这样的问题。 主页:http://hyperopt.github.io/hyperopt-sklearn/ 安装方法: git clone https://github.com/hyperopt/hyperopt-s
-
在2017年的圣诞节前,我翻译了有关HyperOpt的中文文档,这也时填补了空白,以此作为献给所有中国程序员,以及所有其他机器学习相关行业人员的圣诞礼物。圣诞快乐,各位。 更新 Hyperopt官方文档确实比较晦涩难懂,于是我最近补齐了原来挖的坑,Hyperopt的中文教程,同时还包括如何同时使用XGB,lightgbm与Hyperopt.很高兴看到也有其他人写过类似的东西.不过似乎写的都有点问题
-
Compare 浅谈深度学习中超参数调整策略 干货 | 拒绝日夜调参:超参数搜索算法一览 sklearn: Tuning the hyper-parameters of an estimator ML-sklearn参数随机优化:GridSearchCV、RandomizedSearchCV、hyperopt ML模型超参数调节:网格搜索、随机搜索与贝叶斯优化 sklearn中的超参数调节 (1.
-
现在又出了一个调参神器了:Hyperopt,还有Sklearn-Hyperoprt,现在做了一个Demo,仅供大家参考,但是有两点需要注意,我看网上没人说明,个人测试下来说明一下:请大家小心: 1、以下测试代码,需要Python2.7跑,Python3.5会报错,已经找到报错的原因了:TypeError: 'generator' object is not subscriptable;报这个错之后
-
Homepage:https://github.com/hyperopt 特性:Hyperopt是一个sklearn的Python库,在搜索空间上进行串行和并行优化,搜索空间可以是实值,离散和条件维度(real-valued, discrete, and conditional dimensions.)。它支持跨多台机器的并行化,并使用 MongoDb 作为存储超参数组合结果的中心数据库。 使用方
-
Hyperopt库为python中的模型选择和参数优化提供了算法和并行方案。机器学习常见的模型有KNN,SVM,PCA,决策树,GBDT等一系列的算法,但是在实际应用中,我们需要选取合适的模型,并对模型调参,得到一组合适的参数。尤其是在模型的调参阶段,需要花费大量的时间和精力,却又效率低下。但是我们可以换一个角度来看待这个问题,模型的选取,以及模型中需要调节的参数,可以看做是一组变量,模型的质量标
-
最近学习到了一个hyperopt 的一个调参工具(相对于gridsearch的暴力调参,这个速度更加快一点) 官网地址:http://hyperopt.github.io/hyperopt-sklearn/ 1.安装: sudo pip install hyperopt sudo pip install calibration (安装时遇到了 安装问题: 'generator' object is
-
问题内容: 我很难理解scikit-learn的Logistic回归中的参数如何运行。 情况 我想使用逻辑回归对非常不平衡的数据集进行二进制分类。这些类别分别标记为0(负)和1(正),并且观察到的数据的比率约为19:1,大多数样本的结果均为负。 第一次尝试:手动准备训练数据 我将我拥有的数据分为不相交的数据集进行训练和测试(大约80/20)。然后,我手工对训练数据进行了随机采样,得到的训练数据比例
-
本文向大家介绍mysql Key_buffer_size参数的优化设置,包括了mysql Key_buffer_size参数的优化设置的使用技巧和注意事项,需要的朋友参考一下 先来看看document对这个参数的解释: 缓存myisam表的索引块大小,可以被所有进程所共享。当设置key_buffer_size,操作系统不会马上分配key_buffer_size设置的值,而是在需要的时候,再分配的。
-
问题内容: 前一段时间,我使用了一种PNG优化服务,称为(我认为)“ smush it”。您向它提供了一个网络链接,它返回了所有PNG图像的zip压缩文件,它们的文件大小很好,很好地被弄脏了…… 我想在网站的图片上传过程中实现类似的优化功能;有谁知道我可以使用的预先存在的库(最好是PHP或Python)?简短的Google指示我使用了几种命令行样式工具,但我宁愿不走这条路。 问题答案: 用PHP执
-
本文向大家介绍mysql优化的重要参数 key_buffer_size table_cache,包括了mysql优化的重要参数 key_buffer_size table_cache的使用技巧和注意事项,需要的朋友参考一下 MySQL服务器端的参数有很多,但是对于大多数初学者来说,众多的参数往往使得我们不知所措,但是哪些参数是需要我们调整的,哪些对服务器的性能影响最大呢?对于使用Myisam存储引
-
我知道我的问题很笼统,但我对人工智能领域还不熟悉。我用一些参数做了一个实验(几乎6个参数)。每一个都是独立的,我想找到输出函数最大或最小的最优解。然而,如果我想用传统的编程技术来实现,这将需要很多时间,因为我将使用六个嵌套循环。 我只是想知道用哪种人工智能技术来解决这个问题?遗传算法?神经网络?机器学习? 实际上,这个问题可能有不止一个评估函数。它将有一个功能,我们应该最小化它(成本)和另一个功能
-
网格搜索 这里的网格指的是不同参数不同取值交叉后形成的一个多维网格空间。比如参数a可以取1、2,参数b可以取3、4,参数c可以取5、6,那么形成的多维网格空间就是: 1、3、5 1、3、6 1、4、5 1、4、6 2、3、5 2、3、6 2、4、5 2、4、6 一共2*2*2=8种情况 网格搜索就是遍历这8种情况进行模型训练和验证,最终选择出效果最优的参数组合 用法举例 # coding:ut