
PARL 是一个高性能、灵活的强化学习框架。PARL 的目标是构建一个可以完整复杂任务的智能体。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
特点
- 可复现性保证。我们提供了高质量的主流强化学习算法实现,严格地复现了论文对应的指标。
- 大规模并行支持。框架最高可支持上万个 CPU 的同时并发计算,并且支持多 GPU 强化学习模型的训练。
- 可复用性强。用户无需自己重新实现算法,通过复用框架提供的算法可以轻松地把经典强化学习算法应用到具体的场景中。
- 良好扩展性。当用户想调研新的算法时,可以通过继承我们提供的基类可以快速实现自己的强化学习算法。
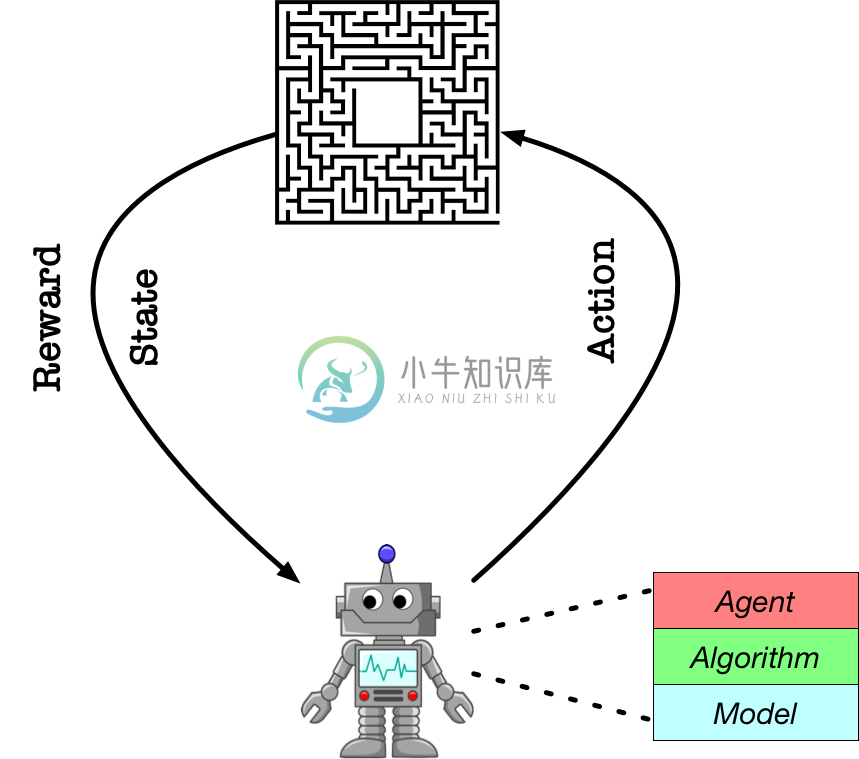
框架结构
-
一、parl的安装 首先安装paddle,见连接:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/windows-pip.html 再安装parl:见连接:https://github.com/PaddlePaddle/PARL 如果安装parl过程中遇到
-
上一节使用parl实现了并行计算 使用parl实现并行计算, 但是这是建立在项目里面不包含除了主文件以外的文件夹的情况下。那么怎样实现强化学习并行训练呢,包括实现多机并行训练。 parl实现强化学习并行训练 要实现强行学习并行训练,那么需要分发文件。 文件分发是分布式并行计算的重要功能。它负责把用户的代码还有配置文件分发到不同的机器上,让所有的机器都运行同样的代码进行并行计算。默认情况下,XPAR
-
import parl [32m[10-06 21:25:01 MainThread @utils.py:73][0m paddlepaddle version: 2.1.2. 使用parl实现并行计算 PARL(PAddlepaddle Reinfocement Learning)是百度推出的基于PaddlePaddle(飞桨)的深度强化学习框架,具有可复用性强、扩展性好、支持大规模并行计算
-
Deep Q-Learning 算法 Deep Q-Learning 算法简称DQN,DQN是在Q-Learning的基础上演变而来的,DQN对Q-Learning的修改主要有两个方面: DQN利用深度卷积神经网络逼近值函数。 DQN利用了经验回放训练强化学习的学习过程。 DQN简介 上节课介绍的表格型方法存储的状态数量有限,当面对围棋或机器人控制这类有数不清的状态的环境时,表格型方法在存储和查找
-
相关文章: 【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学 【二】-Parl基础命令 【三】-Notebook、&pdb、ipdb 调试 【四】-强化学习入门简介 【五】-Sarsa&Qlearing详细讲解 【六】-DQN 【七】-Policy Gradient 【八】-DDPG 【九】-四轴飞行器仿真 飞桨paddle遇到bug调试修正【迁移工具、版本兼容性】
-
相关文章: 【一】MADDPG-单智能体|多智能体总结(理论、算法) 【二】MADDPG多智能体深度强化学习算法算法实现(parl)--【追逐游戏复现】 程序链接:直接fork:MADDPG多智能体深度强化学习算法算法实现(parl)--【追逐游戏复现】 - 飞桨AI Studio 【一】-环境配置+python入门教学 【二】-Parl基础命令
-
最近参加了百度的的PARL深度强化学习课程,算是对强化学习有了一定了解,因为之前并没有学习过强化学习相关的知识,粗略入门,体验了PARL框架,确实对新手比较友好。 入门学习了比较基础的算法,如SARSA,Q-Learning,DQN,PG,DDPG。 能在AI studio上直接跑模型,直接感受模型的效果,对入门学习比较有帮助。 强化学习主要了解3个概念,agent,model,algorithm
-
网上对于paddle环境的搭建大多是基于pip的,Anaconda上也无法找到Parl包,这让用惯了anaconda的我很痛苦。 简单地说,可以直接在Anaconda Prompt里使用pip。期间注意版本兼容性问题和网速问题即可。 在此总结了一下成功的方法,和踩坑的经历。 环境搭建 参考博客conda安装paddle(win10 cpu 版本)_穿拖鞋的都是大佬-CSDN博客_paddle
-
我的一些包版本: python3.8环境 parl ==2.0.3 paddlepaddle ==2.2.0 gym == 0.18.0 试试这个: from parl.core.fluid import layers 我只是纯纯小白,什么也不懂噢(字面意思)
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
探索和利用。马尔科夫决策过程。Q 学习,策略学习和深度强化学习。 我刚刚吃了一些巧克力来完成最后这部分。 在监督学习中,训练数据带有来自神一般的“监督者”的答案。如果生活可以这样,该多好! 在强化学习(RL)中,没有这种答案,但是你的强化学习智能体仍然可以决定如何执行它的任务。在缺少现有训练数据的情况下,智能体从经验中学习。在它尝试任务的时候,它通过尝试和错误收集训练样本(这个动作非常好,或者非常
-
强化学习(RL)如今是机器学习的一大令人激动的领域,也是最老的领域之一。自从 1950 年被发明出来后,它被用于一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和机器控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,在多数游戏中,比人类玩的还好,它仅
-
强化学习(RL)如今是机器学习的一大令人激动的领域,当然之前也是。自从 1950 年被发明出来后,它在这些年产生了一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和及其控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了一项 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,甚至多数比人类玩的还要好,它
-
在本章中,您将详细了解使用Python在AI中强化学习的概念。 强化学习的基础知识 这种类型的学习用于基于评论者信息来加强或加强网络。 也就是说,在强化学习下训练的网络从环境中接收一些反馈。 然而,反馈是有评价性的,而不是像监督学习那样具有指导性。 基于该反馈,网络执行权重的调整以在将来获得更好的批评信息。 这种学习过程类似于监督学习,但我们的信息可能非常少。 下图给出了强化学习的方框图 - 构建
-
我正在制作一个程序,通过强化学习和基于后状态的时间差分学习方法(TD(λ)),教两名玩家玩一个简单的棋盘游戏。学习是通过训练神经网络来实现的。我使用萨顿的非线性TD/Backprop神经网络)我很想听听你对我以下困境的看法。在两个对手之间进行回合的基本算法/伪代码如下 每个玩家应在何时调用其学习方法玩家。学习(GAME\u状态)。这是难题。 选项A.在每个玩家移动后,在新的后状态出现后,如下所示:
-
译者:平淡的天 作者: Adam Paszke 本教程将展示如何使用 PyTorch 在OpenAI Gym的任务集上训练一个深度Q学习 (DQN) 智能点。 任务 智能点需要决定两种动作:向左或向右来使其上的杆保持直立。你可以在 Gym website 找到一个有各种算法和可视化的官方排行榜。 当智能点观察环境的当前状态并选择动作时,环境将转换为新状态,并返回指示动作结果的奖励。在这项任务中,每