
利用 scikit-learn计 算 tf-idf 做文本词频分析

TF-IDF
TF-IDF(Term Frequency and Inverse Document Frequency),是一种用于信息检索与数据挖掘的常用加权技术。它的主要思想是:如果某个词或短语在一篇文章中出现的频率(term frequency)高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
计算公式是TF * IDF
而这里的:
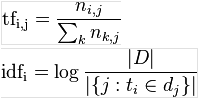
scikit-learn
基于python的一种机器学习工具,主要功能包括:分类、回归、聚类、数据降维、模型选择、数据预处理等
安装步骤:
pip install numpy
pip install scipy
pip install scikit-learn这里如果报出了MemoryError,则增加--no-cache-dir参数,执行
pip --no-cache-dir install numpy
pip --no-cache-dir install scipy
pip --no-cache-dir install scikit-learn词语转矩阵
写一个testscikit.py文件,内容如下:
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
corpus=["中华 民族 血汗",
"人民 血汗",
"共和 国 数学 中华 英语 物理"]
vectorizer=CountVectorizer()
print type(vectorizer.fit_transform(corpus))
print vectorizer.fit_transform(corpus)
print vectorizer.fit_transform(corpus).todense()这里面CountVectorizer是一个向量计数器
第一个print type(vectorizer.fit_transform(corpus))输出结果如下:
<class 'scipy.sparse.csr.csr_matrix'>这说明fit_transform把corpus二维数组转成了一个csr_matrix类型(稀疏矩阵)
第二个print vectorizer.fit_transform(corpus)输出结果如下:
(0, 0) 1
(0, 4) 1
(0, 7) 1
(1, 7) 1
(1, 1) 1
(2, 0) 1
(2, 2) 1
(2, 3) 1
(2, 6) 1
(2, 5) 1这就是稀疏矩阵的表示形式,即把二维数组里的所有词语组成的稀疏矩阵的第几行第几列有值
第三个print vectorizer.fit_transform(corpus).todense()输出如下:
[[1 0 0 0 1 0 0 1]
[0 1 0 0 0 0 0 1]
[1 0 1 1 0 1 1 0]]这就是把稀疏矩阵输出成真实矩阵
下面我们把代码改成:
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
corpus=["中华 民族 血汗",
"人民 血汗",
"共和 国 数学 中华 英语 物理"]
vectorizer=CountVectorizer()
csr_mat = vectorizer.fit_transform(corpus)
transformer=TfidfTransformer()
tfidf=transformer.fit_transform(csr_mat)
print type(tfidf)
print tfidf
print tfidf.todense()输出如下:
<class 'scipy.sparse.csr.csr_matrix'>
(0, 7) 0.517856116168
(0, 4) 0.680918560399
(0, 0) 0.517856116168
(1, 1) 0.795960541568
(1, 7) 0.605348508106
(2, 5) 0.467350981811
(2, 6) 0.467350981811
(2, 3) 0.467350981811
(2, 2) 0.467350981811
(2, 0) 0.35543246785
[[ 0.51785612 0. 0. 0. 0.68091856 0. 0. 0.51785612]
[ 0. 0.79596054 0. 0. 0. 0. 0. 0.60534851]
[ 0.35543247 0. 0.46735098 0.46735098 0. 0.46735098 0.46735098 0. ]]注意:scikit-learn算出的tf-idf值和我们用自己的公式计算出来的不一样,因为它做了很多其他的工作,比如去停用词、平滑、正则化等,只要数值都是用scikit-learn算出来的,就有可比性
从数据可以看出,返回的数据依然是稀疏矩阵csr_matrix结构
分析一下这个tf-idf数据
只出现一次的词在不同总词数的文档之间的对比:数学在6个词文档里是0.46735098,民族在三个词文档里是0.68091856,人民在两个词文档里是0.79596054,可见文档总次数越多,tf-idf越小
在所有文档里出现过一次的词和出现过两次的词在同一个文档里的tf-idf对比:数学只出现过1次,在文档3里是0.46735098,中华出现过两次,在文档3里是0.35543247,因此出现频次越多相对来说tf-idf越小
总之tf-idf越大,这个词对于这个文档越重要
我们继续修改代码,添加如下一行:
word=vectorizer.get_feature_names()
for w in word:
print w输出如下:
中华
人民
共和
数学
民族
物理
英语
血汗这里为什么没有“国”字呢?
我们做这样一个实验,在corpus里添加一些一个字的词,如:
corpus=["中华 民族 血汗",
"人民 血汗",
"共和 国 数学 中华 英语 物理 号 弄 门"]重新执行输出依然是:
中华
人民
共和
数学
民族
物理
英语
血汗经过搜寻网上的文档了解到:
note that CountVectorizer discards "words" that contain only one character, such as "s"
也就是说因为scikit-learn原生是处理英文的,所以对于单个字母的词(如:a、an、I)会被过滤掉。这个feature对于中文来说其实也试用,所以我们不去解决这个事情
好,我们整理一下,添加如下代码:
for i in range(len(tfidf_array)):
line=""
for j in range(len(word)):
line="%s\t\t%s" % (line,word[j])
print line
print
for i in range(len(tfidf_array)):
line=""
for j in range(len(word)):
line="%10s\t\t%10s" % (line,tfidf_array[i][j])
print line输出如下:
中华 人民 共和 数学 民族 物理 英语 血汗
中华 人民 共和 数学 民族 物理 英语 血汗
中华 人民 共和 数学 民族 物理 英语 血汗
0.517856116168 0.0 0.0 0.0 0.680918560399 0.0 0.0 0.517856116168
0.0 0.795960541568 0.0 0.0 0.0 0.0 0.0 0.605348508106
0.35543246785 0.0 0.467350981811 0.467350981811 0.0 0.467350981811 0.467350981811 0.0可以很清晰的看到词矩阵,以及每个词在每个文档里的tfidf了