
概率论09 期望
描述量
描述随机变量最完备的方法是写出该随机变量的概率分布。然而,正如我们在前面章节看到的,概率分布的表达往往都比较复杂,信息量很大。这如同我们购置汽车的时候,一辆汽车的全面数据可以说是海量的,比如汽车尺寸,油箱大小等等。我们选择一辆汽车时,往往只使用有限的几个具有代表性的量来代表汽车的主要特征,比如排气量,最大马力。我们信赖这几个量,因为它们可以“粗糙”的描述汽车的主要性能。这些量是汽车全面数据的一个缩影。
类似的,统计学家也设计了这样的投影系统,将全面的概率分布信息量投射到某几个量上,来代表随机变量的主要特征,从而掌握该随机变量的主要“性能”。这样的一些量称为随机变量的描述量(descriptor)。比如期望用于表示分布的中心位置,方差用于表示分布的分散程度等等。这些描述量可以迅速的传递其概率分布的一些主要信息,允许我们在深入研究之前,先对其特征有一个大概了解。
(买西瓜之前,先听听声音,可以对西瓜的成熟度有个了解。)
期望
期望(expectation)是概率分布的一个经典描述量,它有很深的现实根源。在生活中,我们往往对未知事件有一个预期,也就是我们的期望。比如,我们会根据自己的平时成绩,来期望高考分数。现实生活中的期望可以是许多因素的混合,比如历史表现和主观因素。

你的期望是什么?
在概率论中,我们更加定量的对未知结果进行预估。根据概率分布,我们以概率值为权重,加权平均所有可能的取值,来获得了该随机变量的期望(expectation):
$$E(x) = \sum_i x_ip(x_i)$$
如果某个取值概率较大,那么它就在最终结果中占据较大的分量。期望是一个非常简单而直观的概念。期望常用字母[$\mu$]表示 ([$\mu$]同样是高斯分布的一个参数,我们将马上看到,为什么同一个字母用在两个地方)。
期望在生活中非常常见,特别在估计收益的时候。比如,买一张彩票的收益为一个随机变量X。该彩票售价为2元,有三位数,每位数可以从0到9中任意选择。每期有一个随机选择的号获奖,奖金1000元。那么,X的分布为:
$$p(-2) = 999/1000$$
$$p(998) = 1/1000$$
因此,
$$E(X) = -2 \times p(-2) + 998 \times p(998) = -1.0$$
也就是说,如果买一张彩票,收益的期望为损失1元。
期望是在事件还没确定时,根据概率,对平均结果的估计。如果事件发生,结果并不是期望值。但是,如果重复进行大量实验,其结果的平均值会趋近期望值。需要注意的是,我们将期望写成E(X),这表示的是一个数值,而不是一个随机变量的函数。
基于相似的道理,可以用下面的积分公式,计算连续随机变量的期望:
$$E(X) = \int_{-\infty}^{+\infty}xf(x)dx$$
正态分布的期望
$$E(X) = \frac{1}{\sigma \sqrt{2 \pi}}\int_{-\infty}^{+\infty}xe^{-(x - \mu)^2/2 \sigma^2} dx = \mu$$
即,分布的参数[$\mu$]就是正态分布的期望!这也是[$\mu$]常用于表示期望的原因。
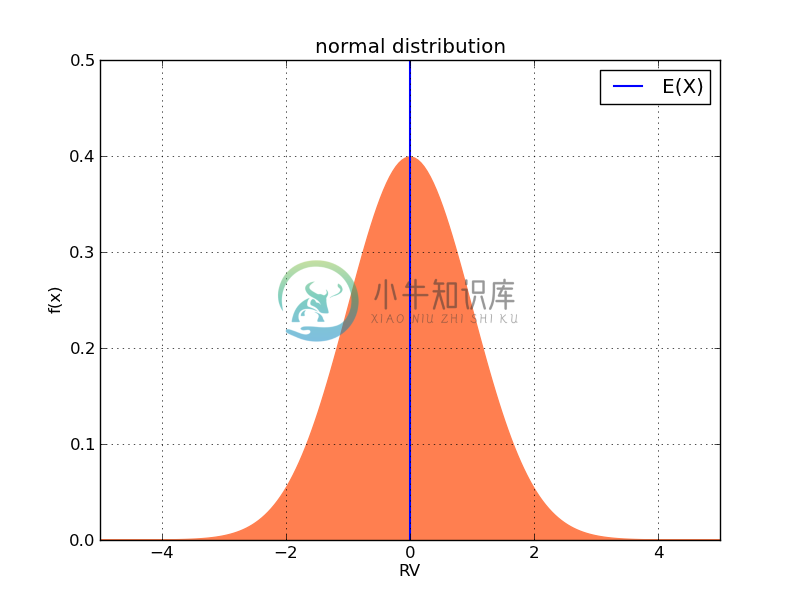
回忆正态分布的密度函数曲线,[$x = \mu$]是分布曲线的对称轴。如果将密度函数曲线下的面积看做一个“物品”,那么[$x = \mu$]是该“物品”的重心所在。比如[$\mu = 0, \sigma = 1$]时,
代码如下:
# By Vamei
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
rv = norm(loc=0, scale = 1)
x = np.linspace(-5, 5, 200)
plt.fill_between(x, rv.pdf(x), y2=0.0 color="coral", label="N(0,1)")
plt.axvline(x = rv.mean(), label="E(X)", linewidth=1.5, color="blue")
plt.legend()
plt.grid(True)
plt.xlim([-5, 5])
plt.ylim([-0.0, 0.5])
plt.title("normal distribution")
plt.xlabel("RV")
plt.ylabel("f(x)")
plt.show()上面的代码中,rv是一个随机变量对象,调用mean()方法,可以计算该随机变量的期望值。
指数分布的期望
根据指数分布的表达式,
$$f(x) = \left\{ \begin{array}{rcl} \lambda e^{-\lambda x} & if & x \ge 0 \\ 0 & if & x < 0 \end{array} \right.$$
它的期望为:
$$E(x) = 1/\lambda$$
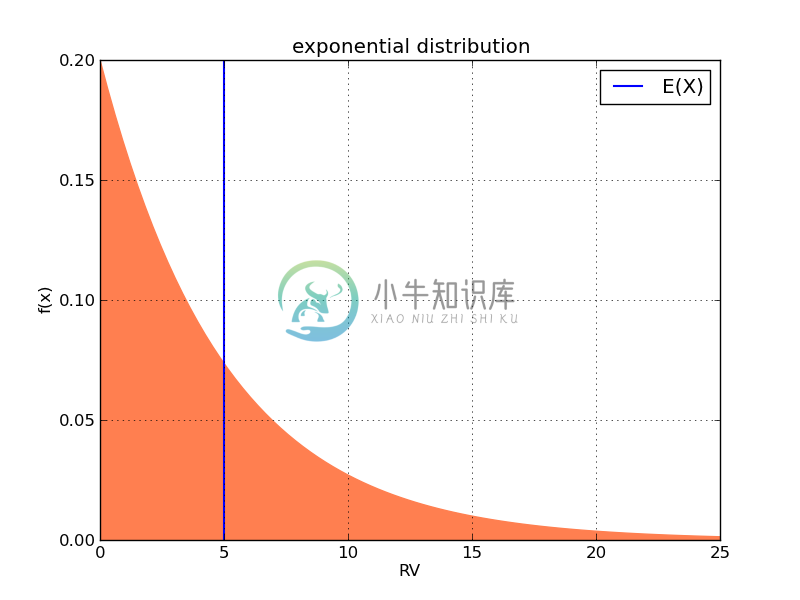
对于[$\lambda = 0.2$]的指数分布,它的期望值为5。
可以通过编程,来计算指数分布的期望。如下图所示:
# By Vamei
from scipy.stats import expon
import numpy as np
import matplotlib.pyplot as plt
rv = expon(scale = 5)
x = np.linspace(0.0, 30, 100)
print rv.pdf(x)
plt.fill_between(x, rv.pdf(x), y2=0, color="coral", label="0.2")
plt.axvline(x = rv.mean(), label="E(X)", linewidth=1.5, color="blue")
plt.grid(True)
plt.legend()
plt.xlim([0, 25])
plt.ylim([0, 0.2])
plt.title("exponential distribution")
plt.xlabel("RV")
plt.ylabel("f(x)")
plt.show()期望的性质
期望有一些很有用的性质:
性质1.
如果[$Y=g(X)$],那么当X为离散随即变量,且[$\sum |g(x)|p(x) < \infty$] (该条件保证下面的累加为有限值)
$$E(Y) = \sum_x g(x)p(x)$$
当X为连续随机变量,且[$\int |g(x)|f(x)dx < \infty$] (该条件保证下面的积分为有限值)
$$E(Y) = \int_{-\infty}^{\infty}g(x)f(x)dx$$
回忆随机变量的函数。X和Y之间存在对应关系。Y的概率分布,等于对应X的概率分布。因此,[$Y = g(X)$]根据X概率的加权平均,就是Y的期望。
性质2.
[$Y = g(X_1, X_2, ..., X_n)$]。如果[$X_i$]是离散的,且有分布[$p(x_1, ..., x_n)$],那么当[$\sum_{x_1, ..., x_n}|g(x_1, ..., x_n)|p(x_1, ..., x_n) < \infty$]时,有
$$E(Y) = \sum_{x_1, ..., x_n} g(x_1, ..., x_n)p(x_1, ..., x_n)$$
如果[$X_i$]是连续的,且有分布[$f(x_1, ..., x_n)$],那么当[$\int\int...\int |g(x_1, ..., x_n)|f(x_1, ..., x_n)dx < \infty $]时,有
$$E(Y) = \int\int...\int g(x_1, ..., x_n)f(x_1, ..., x_n)dx $$
这一性质与上面一个性质类似,只不过换成多变量联合分布的情况。
利用性质1和性质2,我们可以根据原随机变量的分布,计算随机变量函数的期望值。
性质3.
如果X和Y是独立随机变量,而g和h是两个函数,如果[$E[g(X)], E[h(Y)]$]存在,那么有
$$E[g(X)h(Y)] = {E[g(X)]}{E[h(Y)]}$$
根据独立随机变量的性质,我们可以将联合分布写成f(x)和f(y)的乘积。结合性质2,即可得出上面的结论。
一个特别的情况是,如果X和Y独立,那么[$E(XY) = E(X)E(Y)$]。
(即[$g(X) = X, h(Y) = Y$]的情况)
性质4.
如果[$Y = a + \sum_{i=1}^{n}b_iX_i$],而[$X_i$]的期望为[$E(X_i)$],那么
$$E(Y) = a + \sum_{i=1}^n b_i E(X_i)$$
这说明,期望是一个线性运算。随机变量线性组合的期望,等于期望的线性组合。
我们可以假设f(x_i, ..., x_n)的联合分布,并根据性质2来证明性质4。对联合分布的积分,可以得到单随机变量的边缘分布,从而获得单随机变量的期望。
上面四个性质的一个主要功能是,利用已知的期望值,来计算未知的期望值。有些随机变量的期望值比较难以通过定义计算。利用上面的性质,进行合理的变化,更容易计算其期望。
比如,计算二项分布的期望。二项分布是进行n次实验,其中成功的次数Y。每次成功的概率为p。根据定义计算
$$E(Y) = \sum_{k=0}^{n} \left( \begin{array}{c} n \\ k \end{array} \right) k p^k (1-p)^{n-k}$$
上面的计算并不容易。另一方面,观察可知,每次试验成功的次数X是伯努利分布,即
$$p(1) = p, p(0) = 1 - p$$
$$E(X) = p$$
二项分布Y可以表示为n个伯努利分布的和,即
$$Y = \sum_{k=i}^{n} X_i$$
所以
$$E(Y) = \sum_{k=i}^{n} E(X_i) = np$$
条件期望
条件期望将期望用于条件概率。我们已经知道,条件概率是事件B条件下, A的概率,即[$P(A|B)$]。条件概率只不过是在一个缩小了的样本空间B上,重新计算A的概率。条件概率的A与B可以是随机变量,比如[$P(X|Y = y)$],即“随机变量Y等于y”是条件,在该条件下,随机变量X的随机分布。
(在连续随机变量的情况下,我们使用条件密度函数[$f(x | Y = y)$]来描述条件分布)
对于一个已知的分布,我们可以求得条件分布的期望。对于离散随机变量:
$$E(X | Y = y) = \sum_i x_ip(x_i|Y = y)$$
其中,[$x_i$]为该离散随机变量的可能取值。也就是,在一个新的样本空间(Y = y)上,随机变量X的期望值。
对于连续随机变量,其条件期望为:
$$E(X | Y = y) = \int_{-\infty}^{+\infty}xf(x|Y = y)dx$$
一个随机变量的期望为一个数值。但一个条件分布的期望,比如[$E(X | Y = y)$],会随着随机变量Y的变化而变化。所以,条件期望是随机变量Y的函数。根据随机变量的函数的概念,[$E(X | Y = y)$]可以看作一个新的随机变量。我们可以进一步得到这一新的随机变量的期望[$E(E(X|Y))$]。
总结
期望是随机变量分布的一个描述量,用“概率加权平均”来计算,表达随机变量的预期。