
概率论12 矩与矩生成函数
我们重新回到对单随机变量分布的研究。描述量是从分布中提取出的一个数值,用来表示分布的某个特征。之前使用了两个描述量,即期望和方差。在期望和方差之外,还有其它的描述量吗?
斜度
值得思考的是,期望和方差足以用来描述一个分布吗?如果答案是可以,那么我们就没有必要寻找其它描述量的。事实上,这两个描述量并不足以完整的描述一个分布。
我们来看两个分布,一个是指数分布:
$$f(x) = \left\{ \begin{array}{rcl} e^{x} & if & x \ge 0 \\ 0 & if & x < 0 \end{array} \right.$$
它的期望为[$E(x) = 1$],方差为[$Var(x) = 1$]。
我们用Y = 2-X来获得一个新的随机变量,及其分布:
$$f(y) = \left\{ \begin{array}{rcl} e^{2-y} & if & y \le 2 \\ 0 & if & y > 2 \end{array} \right.$$
该密度曲线与原来的密度曲线关于直线X=1对称,与原来的分布有相同的期望值和方差。期望为[$E(x) = 1$],方差为[$Var(x) = 1$]
我们绘制两个分布的密度曲线,如下图: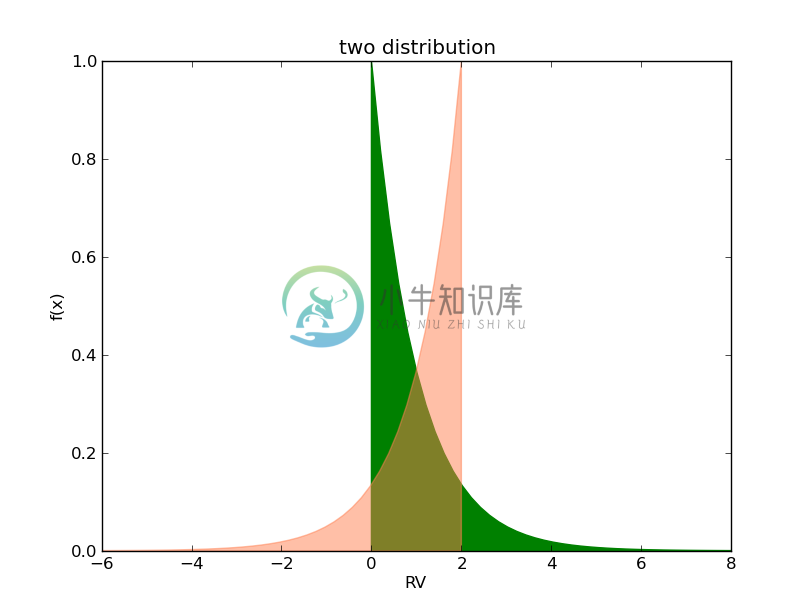
可以看到,即使期望值和方差保持不变,两个分布曲线明显不同。第一条曲线下的面积偏向左,而第二条曲线则向右侧倾斜。为了表达分布的这一特征,我们引入一个新的描述量,斜度(skewness)。它的定义如下:
$$Skew(X) = E[(X - \mu)^3]$$
上面两个分布,第一条曲线向左偏斜,斜度分别为2。另一条曲线的斜度为-2。很明显,斜度的不同可以带来差别巨大的分布(即使期望和方差都相同)。
绘制程序如下
from scipy.stats import expon
import numpy as np
import matplotlib.pyplot as plt
rv = expon(scale = 1)
x1 = np.linspace(0, 20, 100)
x2 = np.linspace(-18, 2, 100)
y1 = rv.pdf(x1)
y2 = rv.pdf(2 - x2)
plt.fill_between(x1, y1, 0.0, color = "green")
plt.fill_between(x2, y2, 0.0, color = "coral", alpha = 0.5)
plt.xlim([-6, 8])
plt.title("two distribution")
plt.xlabel("RV")
plt.ylabel("f(x)")
plt.show()矩
观察方差和斜度的定义,
$$Var(X) = E[(X - \mu)^2]$$
$$Skew(X) = E[(X - \mu)^3]$$
都是X的函数的期望。它们的区别只在于函数的形式,即[$(X - \mu)$]的乘方次数不同。方差为2次方,斜度为3次方。
上面的描述量都可以归为“矩”(moment)的一族描述量。类似于方差和斜度这样的,它们都是[$(X - \mu)$]乘方的期望,称为中心矩(central moment)。[$E[(x - \mu)^k]$]称为k阶中心矩,表示为[$\mu_k$],其中k = 2, 3, 4, ...
还有另一种是原点矩(moment about the origin),是[$X$]乘方的期望。 [$E[X^k]$]称为k阶原点矩,表示为[$\mu_k^\prime$],其中k = 1, 2, 3, ...
期望是一阶原点矩:
$$E(X) = E(X^1)$$
矩生成函数
除了表示中心、离散程序、斜度这些特性外,更高阶的矩可以描述分布的其它特性。矩统计中有重要的地位,比如参数估计的一种重要方法就是利用了矩。然而,根据矩的定义,我们需要对不同阶的X幂求期望,这个过程包含复杂的积分过程,并不容易。矩同样催生了矩生成函数(moment generating function),它是求解矩的一样有力武器。
在了解矩生成函数之前,先来回顾幂级数(power series)。幂级数是不同阶数的乘方(比如[$1, x, x^2, x^3...$])的加权总和:
$$\sum_{i=1}^{+\infty} a_ix^i$$
[$a_i$]是一个常数。
幂级数是数学中的重要工具,它的美妙之处在于,解析函数都可以写成幂级数的形式,比如三角函数[$\sin(x)$]可以写成:
$$\sin(x) = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + ...$$
将解析函数分解为幂级数的过程,就是泰勒分解(Taylor)。我们不再深入其具体过程。[$x^n$]是很简单的一种函数形式,它可以无限次求导,求导也很容易。这一特性让幂级数变得很容易处理。将解析函数写成幂级数,就起到化繁为简的效果。
(幂级数这一工具在数学上的用途极其广泛,它用于数学分析、微分方程、复变函数…… 不能不说,数学家很会活用一种研究透了的工具)
如果我们将幂级数的x看作随机变量X,并求期望。根据期望可以线性相加的特征,有:
$$E(f(X)) = a_0 + a_1E(X) + a_2E(X^2) + a_3E(X^3) + ... $$
我们可以通过矩,来计算f(X)的期望。
另一方面,我们可否通过解析函数来获得矩呢?我们观察下面一个指数函数,写成幂级数的形式:
$$e^{tx} = 1 + tx + \frac{(tx)^2}{2!} + \frac{(tx)^3}{3!} + \frac{(tx)^4}{4!} ... $$
我们再次将x看作随机变量X,并对两侧求期望,即
$$E(e^{tX}) = 1 + tE(X) + \frac{t^2E(X^2)}{2!} + \frac{t^3E(X^3)}{3!} + \frac{t^4E(X^4)}{4!} ...$$
即使随机变量的分布确定,[$E(e^{tX})$]的值还是会随t的变化而变化,因此这是一个关于t的函数。我们将它记为[$M(t)$],这就是矩生成函数(moment generating function)。对[$M(t)$]的级数形式求导,并让t等于0,可以让高阶的t的乘方消失,只留下[$E(X)$],即
$$M'(0) = E(X)$$
即一阶矩。如果继续求高阶导,并让t等于0,可以获得高阶的矩。
$$M^{\left( r \right)}(0) = E(X^r)$$
有趣的是,多次求导系数正好等于幂级数系数中的阶乘,所以可以得到上面优美的形式。我们通过幂级数的形式证明了,对矩生成函数求导,可以获得各阶的矩。相对于积分,求导是一个容易进行的操作。
矩生成函数的性质
矩生成函数的一面是幂级数,我们已经说了很多。矩生成函数的另一面,是它的指数函数的解析形式。即
$$M(t) = E[e^{tX}]= \int_{- \infty}^{\infty}e^{tx}f(x)dx$$
在我们获知了f(x)的具体形式之后,我们可以利用该积分获得矩生成函数,然后求得各阶的矩。当然,你也可以通过矩的定义来求矩。但许多情况下,上面指数形式的积分可以使用一些已有的结果,所以很容易获得矩生成函数。矩生成函数的求解矩的方式会便利许多。
矩生成函数的这一定义基于期望,因此可以使用期望的一些性质,产生有趣的结果。
性质1 如果X的矩生成函数为[$$M_X(t)],且[$Y = aX + b$],那么
$$M_Y(t) = e^{at}M_X(bt)$$
(将Y写成指数形式的期望,很容易证明该结论)
性质2 如果X和Y是独立随机变量,分别有矩生成函数[$M_X, M_Y$]。那么对于随机变量[$Z = X + Y$],有
$$M_Z(t) = M_X(t)M_Y(t)$$
(基于独立随机变量乘积的期望,等于随机变量期望的乘积)
练习:
推导Poisson分布的矩生成函数
总结
矩
矩生成函数