
Deep Learning Cheat Sheet
Gradient ∇ (Nabla)
The gradient is the partial derivative of a function that takes in multiple vectors and outputs a single value (i.e. our cost functions in Neural Networks). The gradient tells us which direction to go on the graph to increase our output if we increase our variable input. We use the gradient and go in the opposite direction since we want to decrease our loss.
Back Propagation
Also known as back prop, this is the process of back tracking errors through the weights of the network after forward propagating inputs through the network. This is used by applying the chain rule in calculus.
Sigmoid σ
A function used to activate weights in our network in the interval of [0, 1]. This function graphed out looks like an ‘S’ which is where this function gets is name, the s is sigma in greek. Also known as the logistic function
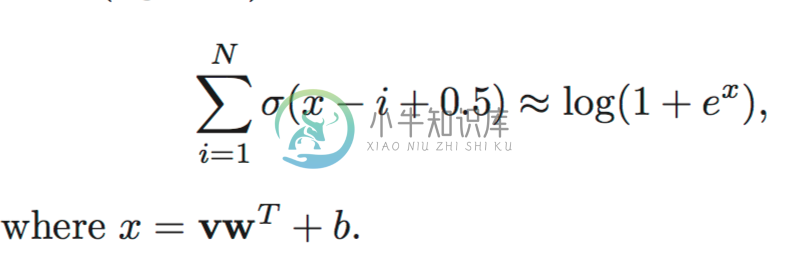
Rectified Linear Units or ReLU
The sigmoid function has an interval of [0,1], while the ReLU has a range from [0, infinity]. This means that the sigmoid is better for logistic regression and the ReLU is better at representing positive numbers. The ReLU do not suffer from the vanishing gradient problem.
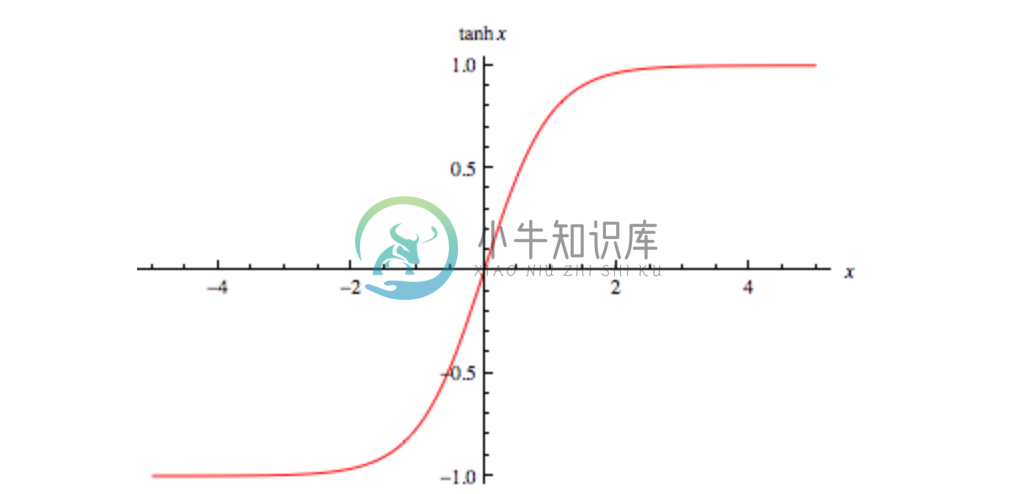
Tanh
Tanh is a function used to initialize the weights of your network of [-1, 1]. Assuming your data is normalized we will have stronger gradients: since data is centered around 0, the derivatives are higher. To see this, calculate the derivative of the tanh function and notice that input values are in the range [0,1].The range of the tanh function is [-1,1] and that of the sigmoid function is [0,1]. This also avoids bias in the gradients.
Softmax
Softmax is a function usually used at the end of a Neural Network for classification. This function does a multinomial logistic regression and is generally used for multi class classification. [2] Usually paired with cross entropy as the loss function.
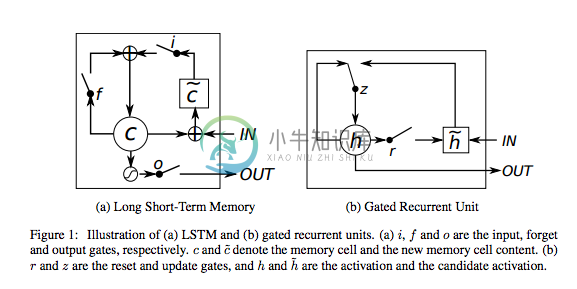
LSTM/GRU
Typically found in Recurrent Neural Networks but are expanding to use in others these are little “memory units” that keep state between inputs for training and help solve the vanishing gradient problem where after around 7 time steps an RNN loses context of the input prior.
L1 and L2 Regularization
These regularization methods prevent overfitting by imposing a penalty on the coefficients. L1 can yield sparse models while L2 cannot. Regularization is used to specify model complexity. This is important because it allows your model to generalize better and not overfit to the training data.
Objective Functions
Also known as loss function or opimization score function. The goal of a network is to minimize the loss to maximize the accuracy of the network.
F1/F Score
A measure of how accurate a model is by using precision and recall following a formula of:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
Precise: of every prediction which ones are actually positive?
Precision = True Positives / (True Positives + False Positives)
Recall: of all that actually have positive predicitions what fraction actually were positive?
Recall = True Positives / (True Positives + False Negatives)
Cross Entropy
Used to calculate how far off your label prediction is. Some times denoted by CE.
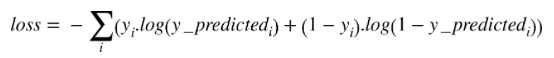
Cross entropy is a loss function is related to the entropy of thermodynamics concept of entropy. This is used in multi class classification to find the error in the predicition.