
特征工程
特征工程是指从原始数据转换为特征向量的过程。特征工程是机器学习中最重要的起始步骤,会直接影响机器学习的效果,并通常需要大量的时间。典型的特征工程包括数据清理、特征提取、特征选择等过程。
数据清理
- 缩放特征值(归一化):将浮点特征值从自然范围(如 100 到 900)转换为标准范围(如 0 到 1)。特征集包含多个特征时,缩放特征可以加快梯度下降的收敛过程,并可以避免 NaN 陷阱。特征缩放的方法一般为 $$scaled-value = (value-mean)/stddev$$
- 处理极端离群值,如取对数、限制最大最小值等方法
- 分箱(离散化)
- 填补遗漏值
- 移除重复样本、不良标签、不良特征值等
- 平滑
- 正则化
降维
高维情形下经常会碰到数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),解决方法就是降维。
常用的降维方法有
- 主成分分析法(PCA)
- 核化线性降维(KPCA)
- 主成分回归(PCR)
- 偏最小二乘回归(PLSR)
- 萨蒙映射
- 多维尺度分析法(MDS)
- 投影寻踪法(PP)
- 线性判别分析法(LDA)
- 混合判别分析法(MDA)
- 二次判别分析法(QDA)
- 灵活判别分析法(Flexible Discriminant Analysis,FDA
特征选择
特征选择是一个从给定的特征集合中选择与当前学习任务相关的特征的过程。特征选择中所谓的 “无关特征” 是指与当前学习任务无关,比如有一类特征称为 “冗余特征” 可以从其他特征中推演出来,它在很多时候是不起作用的,并且会增加学习过程的负担。
常见的特征选择方法大致可分为三类:过滤式、包裹式和嵌入式。
- 过滤式选择:先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。典型算法为 Relief 算法。
- 方差选择法
- 相关系数法
- 卡方检验
- 互信息法
- 包裹式选择:选择直接把最终将要使用的学习器的性能作为特征子集的评价标准。典型算法为 LVM(Las Vegas Wrapper)。
- 递归特征消除法
- 嵌入式选择:将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。典型算法为岭回归(ridge regression)、LASSO 回归(Least Absolute Shrinkage and Selection Operator)等。
- 基于惩罚项的特征选择法
- 基于树模型的特征选择法
良好特征的特点包括
- 避免很少使用的离散特征值:良好的特征值应该在数据集中出现大约 5 次以上
- 最好具有清晰明确的含义
- 良好的浮点特征不包含超出范围的异常断点或 “神奇” 的值
- 特征的定义不应随时间发生变化
特征组合
特征组合(Feature Crosses)也称为特征交叉,指通过将两个或多个输入特征相乘来对特征空间中的非线性规律进行编码的合成特征。
比如,如下的问题显然是一个非线性问题:
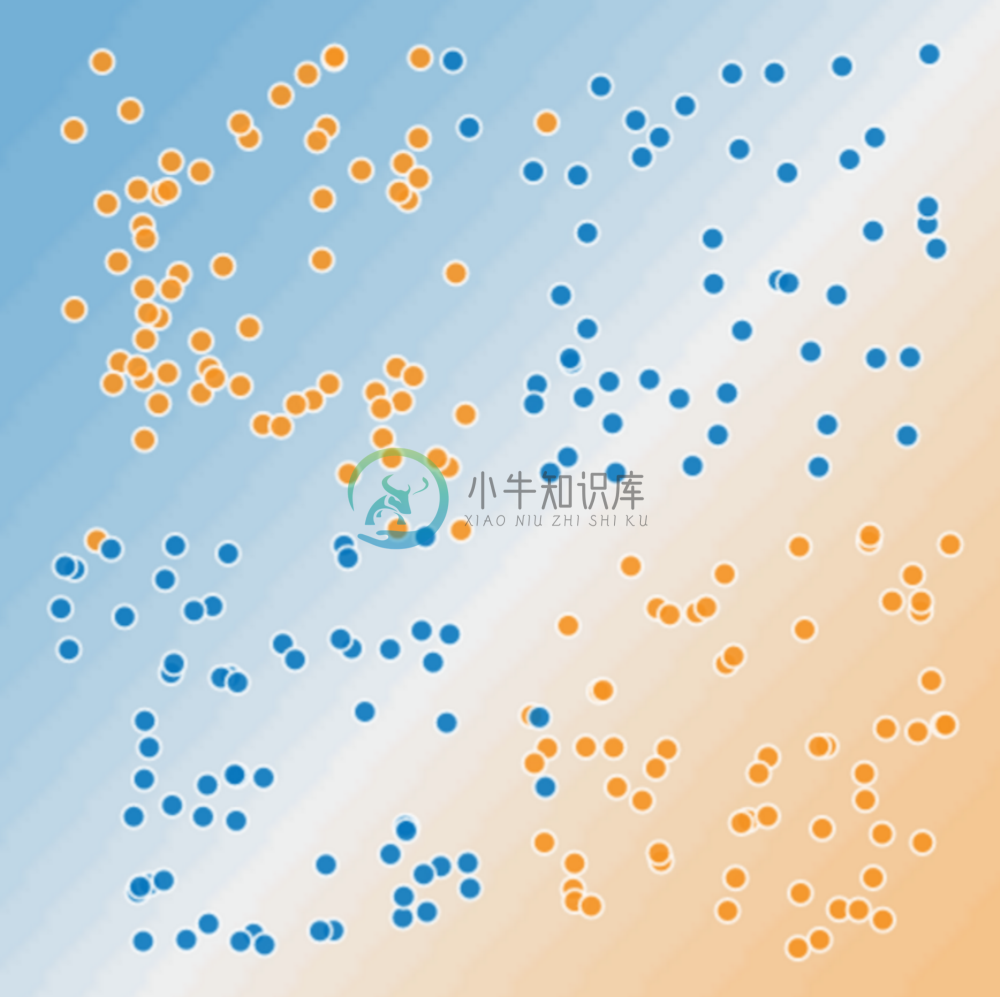
但使用特征组合可以将其转换为一个线性模型,即创建一个新的特征
$$x_3=x_1*x_2$$
$$y=b+w_1x_1+w_2x_2+w_3x_3$$
常见的特征组合方法有
- [A X B]:将两个特征的值相乘形成的特征组合。
- [A x B x C x D x E]:将五个特征的值相乘形成的特征组合。
- [A x A]:对单个特征的值求平方形成的特征组合。
借助特征组合,线性学习器可以很好扩展到大量数据,并有助于构建复杂模型解决非线性问题。