
R 语言特征工程实战

R语言介绍
熟悉R语言的朋友请直接略过。R语言是贝尔实验室开发的S语言(数据统计分析和作图的解释型语言)的一个分支,主要用于统计分析和绘图,R可以理解为是一种数学计算软件,可编程,有很多有用的函数库和数据集。
R的安装和使用
在https://mirrors.tuna.tsinghua.edu.cn/CRAN/下载对应操作系统的安装包安装。安装好后单独创建一个目录作为工作目录(因为R会自动在目录里创建一些有用的隐藏文件,用来存储必要的数据)
执行
R即可进入R的交互运行环境
简单看一个实例看一下R是如何工作的:
[root@centos:~/Developer/r_work $] R
R version 3.3.1 (2016-06-21) -- "Bug in Your Hair"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin13.4.0 (64-bit)
> x <- c(1,2,3,4,5,6,7,8,9,10)
> y <- x*x
> plot(x,y,type="l")
>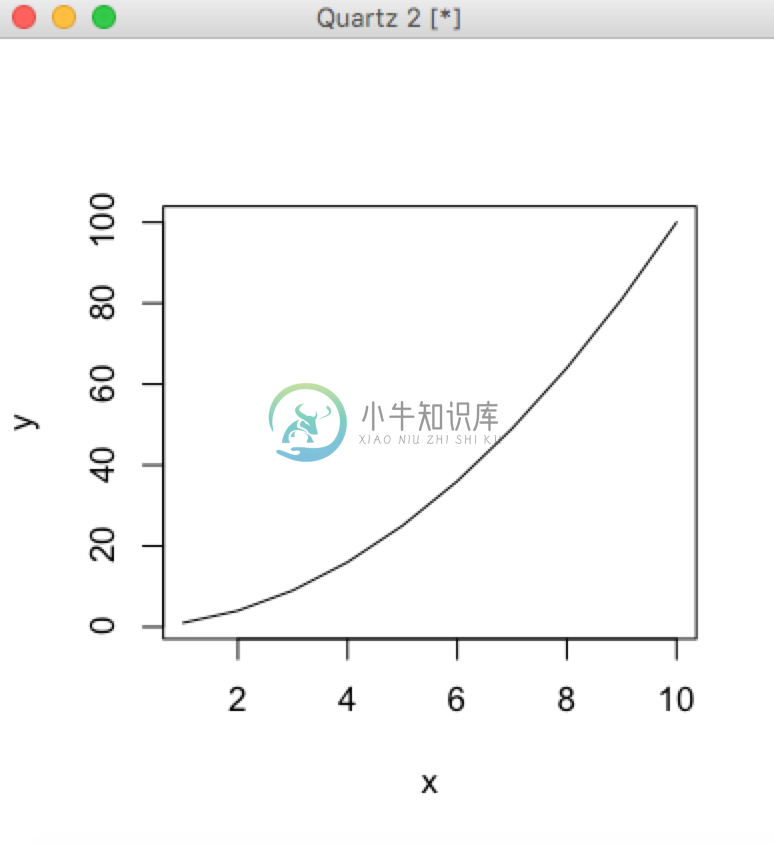
以上看得出我们画了y = x^2的曲线
R语言的语法和C类似,但是稍有不同,R语言里向量和矩阵的操作和python的sci-learn类似,但是稍有不同:
1. R的赋值语句的符号是"<-"而不是"="
2. R里的向量用c()函数定义,R里没有真正的矩阵类型,矩阵就是一系列向量组成的list结构
有时候如果我们想要加载一个库发现没有安装,就像这样:
> library(xgboost)
Error in library(xgboost) : 不存在叫‘xgboost’这个名字的程辑包那么就这样来安装:
> install.packages("xgboost")输入后会提示选择下载镜像,选择好后点ok就能自动安装完成,这时就可以正常加载了:
> library(xgboost)
>想了解R语言的全部用法,推荐《权威的R语言入门教程《R导论》-丁国徽译.pdf》,请自行下载阅读,也可以继续看我下面的内容边用边学
特征工程
按我的经验,特征工程就是选择和使用特征的过程和方法,这个说起来容易,做起来真的不易,想要对实际问题设计一套机器学习方法,几乎大部分时间都花在了特征工程上,相反最后的模型开发花不了多长时间(因为都是拿来就用了),再有需要花一点时间的就是最后的模型参数调优了。花费时间排序一般是:特征工程>模型调参>模型开发
Titanic数据集特征工程实战
Titanic数据集是这样的数据:Titanic(泰坦尼克号)沉船灾难死亡了很多人也有部分人成功得救,数据集里包括了这些字段:乘客级别、姓名、性别、年龄、船上的兄弟姐妹数、船上的父母子女数、船票编号、票价、客舱编号、登船港口、是否得救。
我们要做的事情就是把Titanic数据集中部分数据作为训练数据,然后用来根据测试数据中的字段值来预测这位乘客是否得救
数据加载
训练数据可以在https://www.kaggle.com/c/titanic/download/train.csv下载,测试数据可以在https://www.kaggle.com/c/titanic/download/test.csv下载
下面开始我们的R语言特征工程,创建一个工作目录r_work,下载train.csv和test.csv到这个目录,看下里面的内容:
[root@centos:~/Developer/r_work $] head train.csv
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",female,27,0,2,347742,11.1333,,S我们看到文件内容是用逗号分隔的多个字段,第一行是schema,第二行开始是数据部分,其中还有很多空值,事实上csv就是Comma-Separated Values,也就是用“逗号分隔的数值”,它也可以用excel直接打开成表格形式
R语言为我们提供了加载csv文件的函数,如下:
> train <- read.csv('train.csv', stringsAsFactors = F)
> test <- read.csv('test.csv', stringsAsFactors = F)如果想看train和test变量的类型,可以执行:
> mode(train)
[1] "list"我们看到类型是列表类型
如果想预览数据内容,可以执行:
> str(train)
'data.frame': 891 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ...
$ Sex : chr "male" "female" "female" "female" ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : chr "" "C85" "" "C123" ...
$ Embarked : chr "S" "C" "S" "S" ...可以看到其实train和test变量把原始的csv文件解析成了特定的数据结构,train里有891行、12列,每一列的字段名、类型以及可能的值都能预览到
因为test数据集也是真实数据的一部分,所以在做特征工程的时候可以把test和train合并到一起,生成full这个变量,后面我们都分析full:
> library('dplyr')
> full <- bind_rows(train, test)头衔特征的提取
因为并不是所有的字段都应该用来作为训练的特征,也不是只有给定的字段才能作为特征,下面我们开始我们的特征选择工作,首先我们从乘客的姓名入手,我们看到每一个姓名都是这样的结构:"名字, Mr/Mrs/Capt等. 姓",这里面的"Mr/Mrs/Capt等"其实是一种称谓(Title),虽然人物的姓名想必和是否得救无关,但是称谓也许和是否得救有关,我们把所有的Title都筛出来:
> table(gsub('(.*, )|(\\..*)', '', full$Name))
Capt Col Don Dona Dr Jonkheer
1 4 1 1 8 1
Lady Major Master Miss Mlle Mme
1 2 61 260 2 1
Mr Mrs Ms Rev Sir the Countess
757 197 2 8 1 1解释一下,这里面的full$Name表示取full里的Name字段的内容,gsub是做字符串替换,table是把结果做一个分类统计(相当于group by title),得出数目
通过结果我们看到不同Title的人数目差别比较大
我们把这个Title加到full的属性里:
> full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)这时我们可以按性别和title分两级统计(相当于group by sex, title):
> table(full$Sex, full$Title)
Capt Col Don Dona Dr Jonkheer Lady Major Master Miss Mlle Mme Mr Mrs
female 0 0 0 1 1 0 1 0 0 260 2 1 0 197
male 1 4 1 0 7 1 0 2 61 0 0 0 757 0
Ms Rev Sir the Countess
female 2 0 0 1
male 0 8 1 0为了让这个特征更具有辨别性,我们想办法去掉那些稀有的值,比如总次数小于10的,我们都把title改成“Rare Title”
> rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')
> full$Title[full$Title %in% rare_title] <- 'Rare Title'同时把具有相近含义的title做个归一化
> full$Title[full$Title == 'Mlle'] <- 'Miss'
> full$Title[full$Title == 'Ms'] <- 'Miss'
> full$Title[full$Title == 'Mme'] <- 'Mrs'这回我们看下title和是否得救的关系情况
> table(full$Title, full$Survived)
0 1
Master 17 23
Miss 55 130
Mr 436 81
Mrs 26 100
Rare Title 15 8还不够直观,我们可以通过马赛克图来形象的看:
> mosaicplot(table(full$Sex, full$Title), shade=TRUE)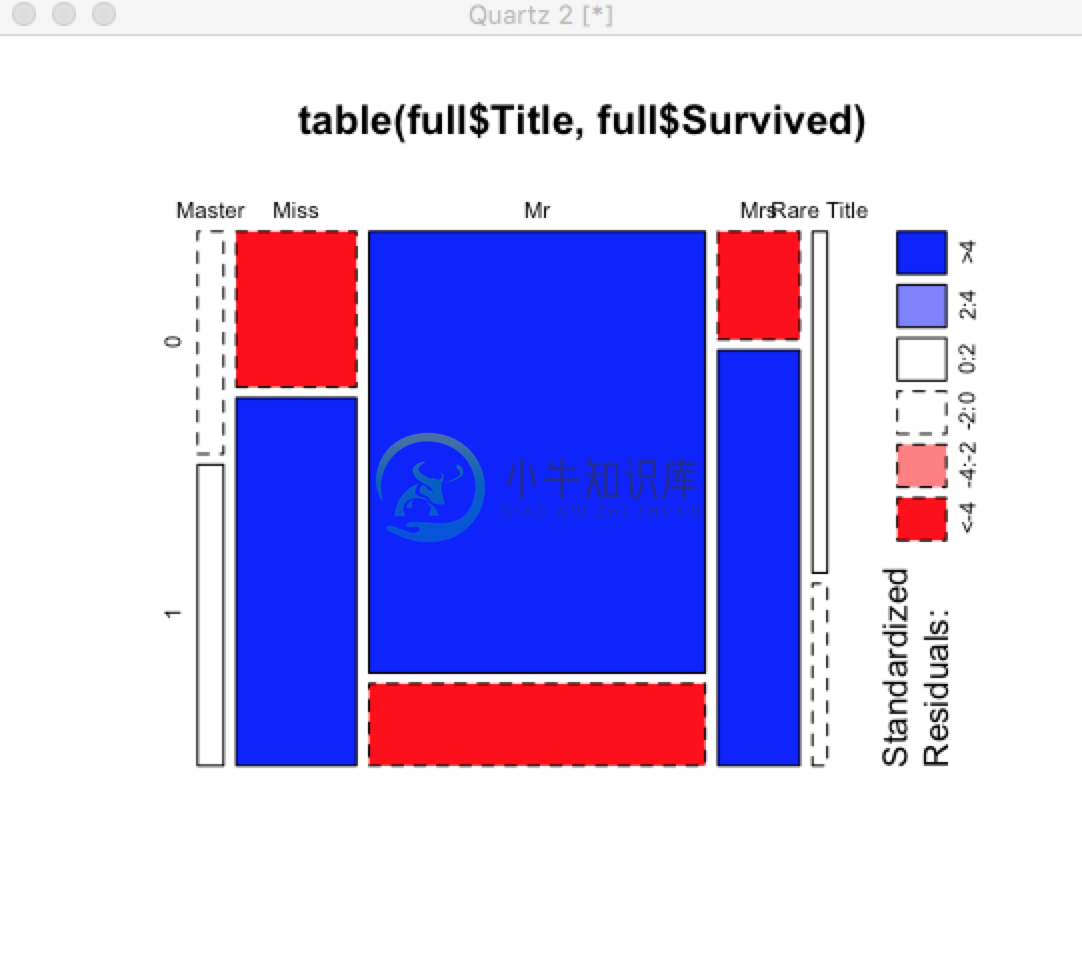
这回看出比例情况的差异了,比如title为Mr的死亡和得救的比例比较明显,说明这和是否得救关系密切,title作为一个特征是非常有意义的
这样第一个具有代表意义的特征就提取完了
家庭成员数特征的提取
看过电影的应该了解当时的场景,大家是按照一定秩序逃生的,所以很有可能上有老下有小的家庭会被优先救援,所以我们统计一下一个家庭成员的数目和是否得救有没有关系。
为了计算家庭成员数目,我们只要计算父母子女兄弟姐妹的数目加上自己就可以,所以:
> full$Fsize <- full$SibSp + full$Parch + 1下面我们做一个Fsize和是否得救的图像
> library("ggplot2")
> library('ggthemes')
> ggplot(full[1:891,], aes(x = Fsize, fill = factor(Survived))) + geom_bar(stat='count', position='dodge') + scale_x_continuous(breaks=c(1:11)) + labs(x = 'Family Size') + theme_few()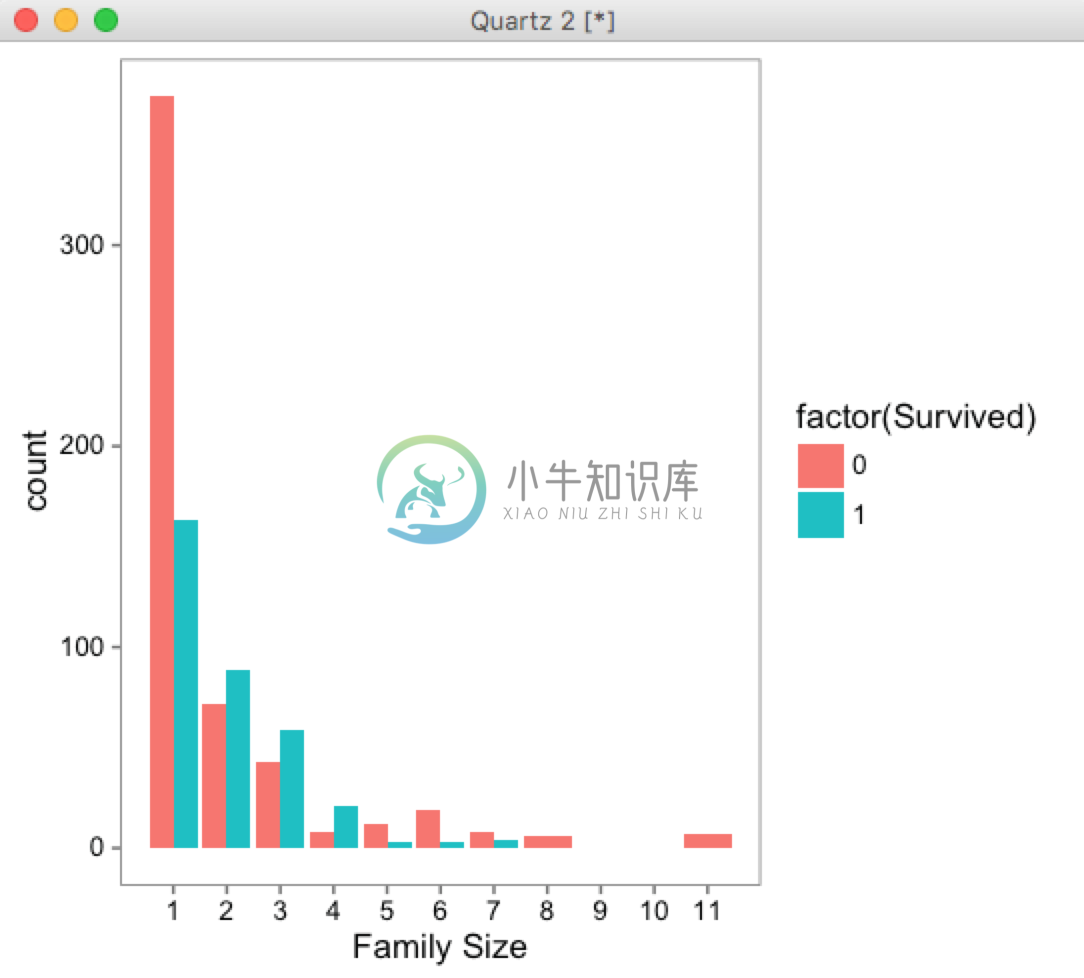
我们先解释一下上面的ggplot语句
第一个参数full[1:891,]表示我们取全部数据的前891行的所有列,取891是因为train数据一共有891行
aes(x = Fsize, fill = factor(Survived))表示坐标轴的x轴我们取Fsize的值,这里的fill是指用什么变量填充统计值,factor(Survived)表示把Survived当做一种因子,也就是只有0或1两种“情况”而不是数值0和1,这样才能分成红绿两部分统计,不然如果去掉factor()函数包裹就会像这个样子(相当于把0和1加了起来):
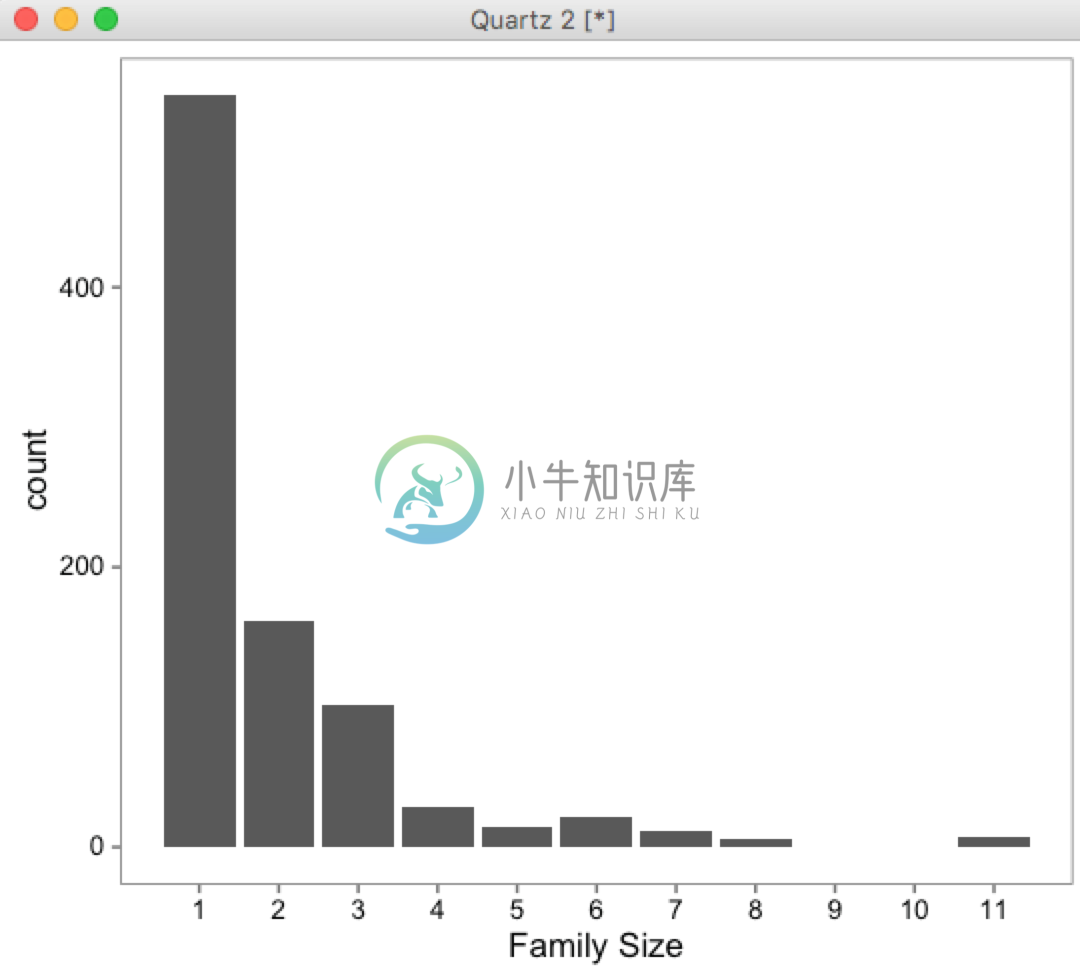
这里的“+”表示多个图层,是ggplot的用法
geom_bar就是画柱状图,其中stat='count'表示统计总数目,也就是相当于count(*) group by factor(Survived),position表示重叠的点放到什么位置,这里设置的是“dodge”表示规避开的展示方式,如果设置为"fill"就会是这样的效果:
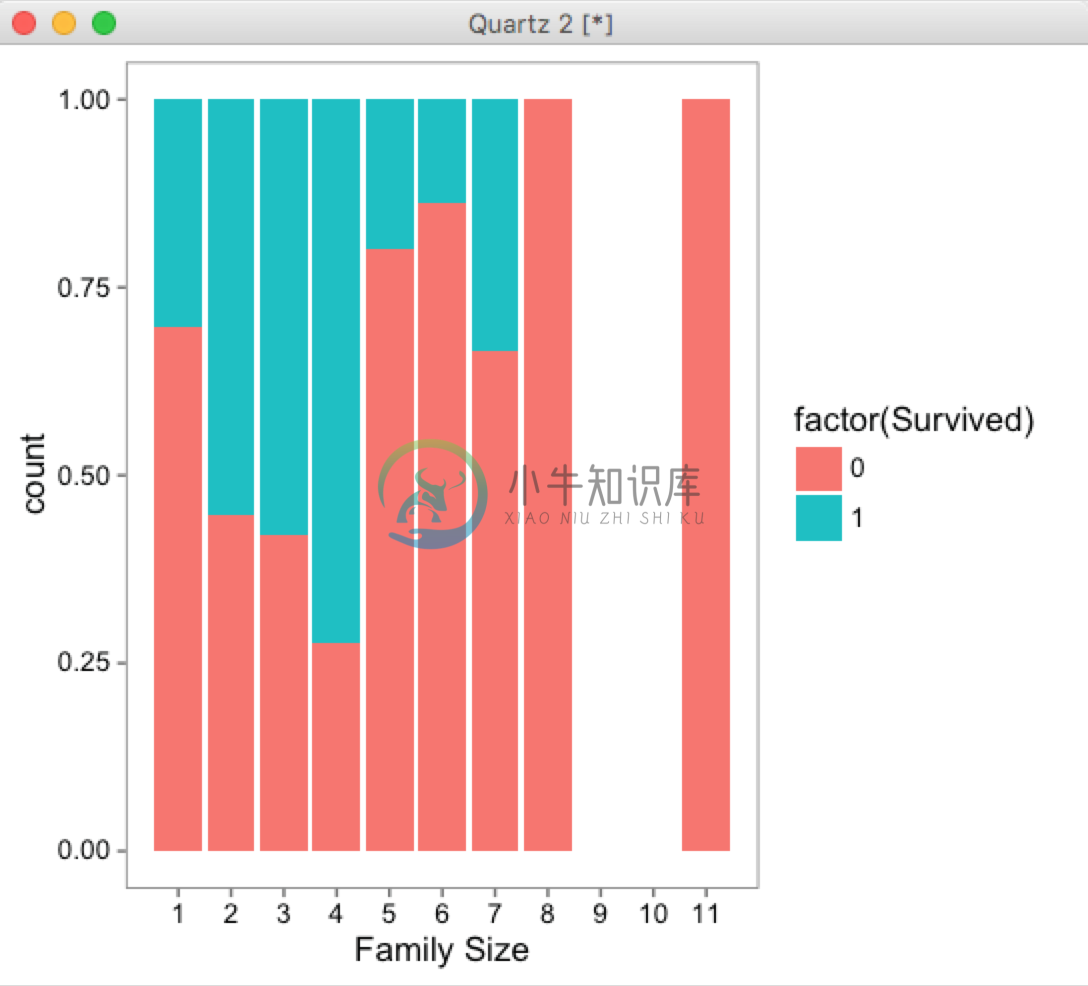
scale_x_continuous(breaks=c(1:11))就是说x轴取值范围是1到11,labs(x = 'Family Size')是说x轴的label是'Family Size',theme_few()就是简要主题
下面我们详细分析一下这个图说明了什么事情。我们来比较不同家庭成员数目里面成功逃生的和死亡的总数的比例情况可以看出来:家庭人数是1或者大于4的情况下红色比例较大,也就是死亡的多,而人数为2、3、4的情况下逃生的多,因此家庭成员数是一个有意义的特征,那么把这个特征总结成singleton、small、large三种情况,即:
> full$FsizeD[full$Fsize == 1] <- 'singleton'
> full$FsizeD[full$Fsize < 5 & full$Fsize > 1] <- 'small'
> full$FsizeD[full$Fsize > 4] <- 'large'再看下马赛克图:
> mosaicplot(table(full$FsizeD, full$Survived), main='Family Size by Survival', shade=TRUE)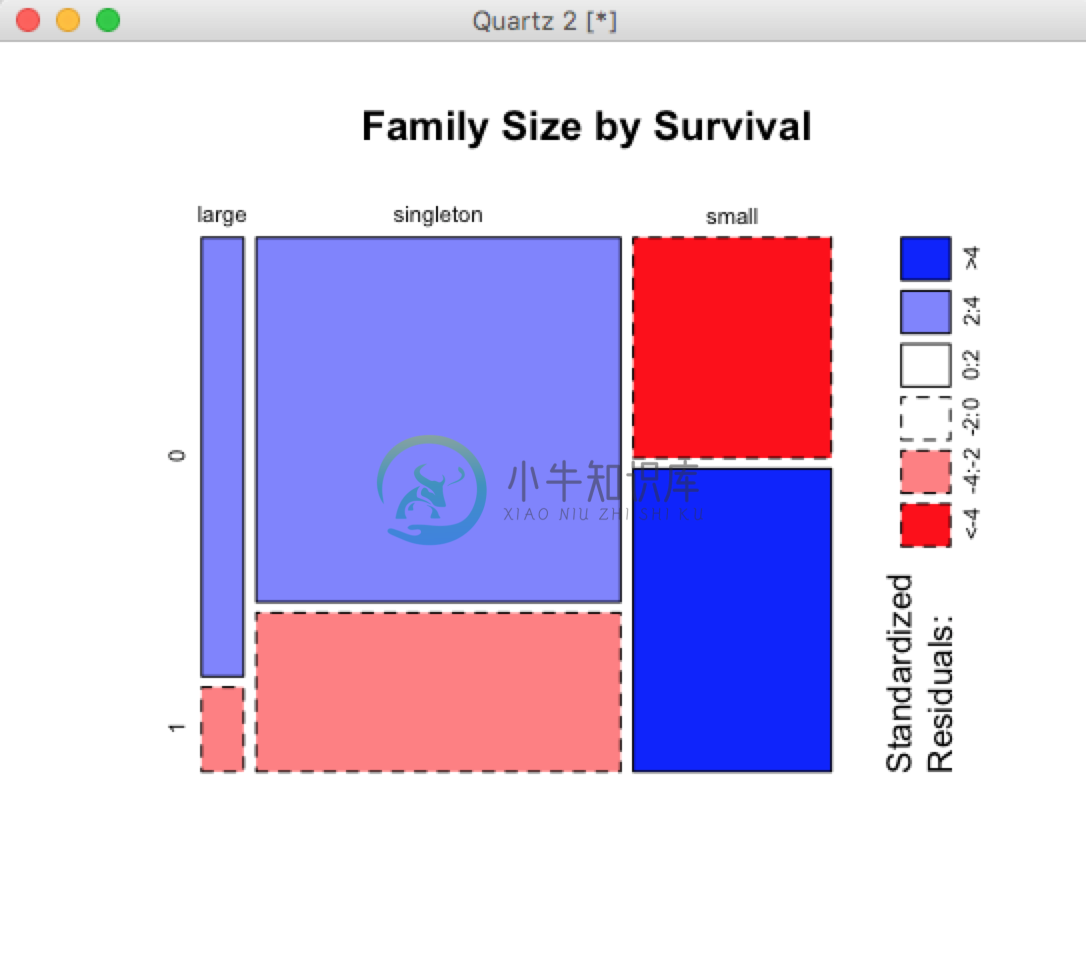
从图中可以看出差异明显,特征有意义
模型训练
处理好特征我们就可以开始建立模型和训练模型了,我们选择随机森林作为模型训练。首先我们要把要作为factor的变量转成factor:
> factor_vars <- c('PassengerId','Pclass','Sex','Embarked','Title','FsizeD')
> full[factor_vars] <- lapply(full[factor_vars], function(x) as.factor(x))然后我们重新提取出train数据和test数据
> train <- full[1:891,]
> test <- full[892:1309,]接下来开始训练我们的模型
> library('randomForest')
> set.seed(754)
> rf_model <- randomForest(factor(Survived) ~ Pclass + Sex + Embarked + Title + FsizeD, data = train)下面画出我们的模型误差变化:
> plot(rf_model, ylim=c(0,0.36))
> legend('topright', colnames(rf_model$err.rate), col=1:3, fill=1:3)
图像表达的是不同树个数情况下的误差率,黑色是整体情况,绿色是成功获救的情况,红色是死亡的情况,可以看出通过我们给定的几个特征,对死亡的预测误差更小更准确
我们还可以利用importance函数计算特征重要度:
> importance(rf_model)
MeanDecreaseGini
Pclass 40.273719
Sex 53.240211
Embarked 8.566492
Title 85.214085
FsizeD 23.543209可以看出特征按重要程度从高到底排序是:Title > Sex > Pclass > FsizeD > Embarked
数据预测
有了训练好的模型,我们可以进行数据预测了
> prediction <- predict(rf_model, test)这样prediction中就存储了预测好的结果,以0、1表示
为了能输出我们的结果,我们把test数据中的PassengerId和prediction组合成csv数据输出
> solution <- data.frame(PassengerID = test$PassengerId, Survived = prediction)
> write.csv(solution, file = 'solution.csv', row.names = F)最终的solution.csv的内容如下:
[root@centos:~/Developer/r_work $] head solution.csv
"PassengerID","Survived"
"892","0"
"893","1"
"894","0"
"895","0"
"896","1"
"897","0"
"898","1"
"899","0"
"900","1"本文部分内容参考:https://www.kaggle.com/mrisdal/titanic/exploring-survival-on-the-titanic/comments