
第 2 章 迭代、归纳和递归
计算机的威力源自其反复执行同一任务或同一任务不同版本的能力。在计算领域,迭代这一主题会以多种形式出现。数据模型中的很多概念(比如表)都是某种形式的重复,比如“表要么为空,要么由一个元素接一个元素,再接一个元素,如此往复而成”。使用迭代,程序和算法可以在不需要单独指定大量相似步骤的情况下,执行重复性的任务,如“执行下一步骤1000次”。编程语言使用像C语言中的while语句和for语句那样的循环结构,来实现迭代算法。
与重复密切相关的是递归,在递归技术中,概念是直接或间接由其自身定义的。例如,我们可以通过“表要么为空,要么是一个元素后面再跟上一个表”这样的描述来定义表。很多编程语言都支持递归。在C语言中,函数F是可以调用自身的,既可以从F的函数体中直接调用自己,也可以通过一连串的函数调用,最终间接调用F。另一个重要思想——归纳,是与“递归”密切相关的,而且常用于数学证明中。
迭代、归纳和递归都是基本概念,会以多种形式出现在数据模型、数据结构和算法中。下面介绍了一些使用这些概念的例子,每项内容都会在本书中详细介绍。
1. 迭代技术。反复执行一系列操作的最简单方法就是使用迭代结构,比如C语言中的for语句。
2. 递归程序设计。C语言及其他众多语言都允许函数递归,即函数可以直接或间接地调用自己。对新手程序员来说,编写迭代程序通常比写递归程序更安全,不过本书的一个重要目标就是让读者习惯在适当的时候用递归的方式来思考和编程。递归程序更易于编写、分析和理解。
符号:求和符号和求积符号
加大字号的大写希腊字母∑通常用来表示求和,如
。这个特殊的表达式表示从1到n 这n个整数的和,也就是1+2+3+ … +n。更加一般化的情况是,我们可以对任何具有求和指标(summation index)i 的函数f (i )求和。(当然,这个指标也可能是i 以外的一些符号。)表达式
就表示
f (a) + f (a + 1) + f (a + 2) + … + f (b)
例如,
就表示4 + 9 + 16 + … + m2 的和,这里的函数f 就是“求平方”,而我们用了指标j 来代替i。
作为特例,如果b< a,那么表达式
不含任何项,当然,其值也就是0了。如果b=a,那么表达式只有i=a 时的那一项。因此,
的值就是f (a)。
用于求积的类似符号是个大号的大写希腊字母 Π。表达式
就表示
f (a) × f (a + 1) × f (a + 2) × … × f (b)
的积,如果b<a,那么该表达式的值为1。
3. 归纳证明。“归纳证明”是用来表明命题为真的一项重要技术。从2.3节开始,我们将广泛介绍归纳证明。下面是归纳证明最简单的一种形式。我们有与变量n相关的命题S(n),希望证明S(n)为真。要证明S(n),首先要提供依据,也就是n为某个值时的命题S(n)。例如,我们可以令n=0,并证明命题S(0)。接着,我们必须对归纳步骤加以证明,我们要证明,对应参数某个值的命题S,是由对应参数前一个值的相同命题S得出的,也就是说,对所有的n≥0,可从S(n)得到S(n+1)。例如,S(n)可能是常见的求和公式
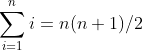 (2.1)
(2.1)
这是说1到n这n个整数的和等于n(n+1)/2。特例可以是S(1),即等式(2.1)在n为1时的情况,也就是1=1×2/2。归纳步骤就是要表明,由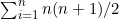 可以得出
可以得出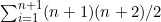 ,前者就是S(n),是等式(2.1)本身,而后者则是S(n+1),就是用n+1替换了等式(2.1)中的n。2.3节将会为大家展示如何进行这样的证明。
,前者就是S(n),是等式(2.1)本身,而后者则是S(n+1),就是用n+1替换了等式(2.1)中的n。2.3节将会为大家展示如何进行这样的证明。
4. 程序正确性证明。在计算机科学中,我们常希望能够证明与程序有关的命题S(n)为真,不管是采用正式的还是非正式的方式。例如,命题S(n)可能描述了某个循环的第n次迭代中什么为真,或是对某个函数的第n次递归调用来说什么为真。对这类命题的证明一般都使用归纳证明。
5. 归纳定义。计算机科学的很多重要概念,特别是那些涉及数据模型的,最好用归纳的形式来定义,也就是我们给出定义该概念最简单形式的基本规则,以及可用来从该概念较小实例构建更大实例的归纳规则。举例来说,我们提到过的表就可由基本规则(空表是表)加上归纳规则(一个元素后面跟上一个表也是表)来定义。
6. 运行时间的分析。算法处理不同大小的输入所花的时长(算法的“运行时间”)是衡量其“优良性”的一项重要指标。当算法涉及递归时,我们会使用名为递推方程的公式,它是种归纳定义,可以预测算法处理不同大小的输入所花的时间。
本章会介绍前5项主题,程序的运行时间将在第3章中介绍。
2.1 本章主要内容
在本章中,我们将介绍以下主要概念。
迭代程序设计(2.2节)。
归纳证明(2.3节和2.4节)。
归纳定义(2.6节)。
递归程序设计(2.7节和2.8节)。
证明程序的正确性(2.5节和2.9节)。
除此之外,通过这些概念的例子,我们还会着重介绍计算机科学中一些有趣的重要思想。其中包括:
排序算法,包括选择排序(2.2节)和归并排序(2.8节)。
奇偶校验及数据错误的检测(2.3节)。
算术表达式及其代数变形(2.4节和2.6节)。
平衡圆括号(2.6节)。
2.2 迭代
新手程序员都会学习使用迭代,采用某种循环结构(如C语言中的for语句和while语句)。在本节中,我们将展示一个迭代算法的例子——“选择排序”。在2.5节中,我们还将通过归纳法证明这种算法确实能排序,并会在3.6节中分析它的运行时间。在2.8节中,我们要展示如何利用递归设计一种更加高效的排序算法,这种算法使用了一种称作“分而治之”的技巧。
常见主题:自定义和依据-归纳
在学习本章时,大家应该注意到有两个主题贯穿多个概念。第一个是自定义(self-definition),就是指概念是依据其自身定义或构建的。例如,我们提到过,表可以定义为空,或一个元素后跟一个表。
第二个主题是依据-归纳(basis-induction)。递归函数通常都含有某种针对不需要递归调用的“依据”实例,以及需要一次或多次递归调用的“归纳”实例进行测试。众所周知,归纳证明包括依据和归纳步骤,归纳定义也一样。依据-归纳这一对非常重要,在后文中每次出现依据情况或归纳步骤时,都会突出标记这些词语。
运用恰当的自定义不会出现悖论或循环性,因为自定义的子部分总是比被定义的对象“更小”。此外,在经过有限个通向更小部分的步骤后,就能到达依据情况,也就是自定义终止的地方。例如,表L 是由一个元素和比L 少一个元素的表构成的。当我们遇到没有元素的表,就有了表定义的依据情况:“空表是表”。
再举个例子,如果某递归函数是有效的,那么从某种意义上讲,某一函数调用的参数必须要比调用该函数的函数副本的参数“更小”。还有,在经过若干次递归调用后,我们必须要让参数“小到”函数不再进行递归调用为止。
2.2.1 排序
要排序具有n个元素的表,我们需要重新排表中的元素,使它们按照非递减顺序排列。
示例 2.1
假设有整数表{3,1,4,1,5,9,2,6,5}。我们要将其重新排列成序列{1,1,2,3,4,5,5,6,9},实现对该表的排序。请注意,排序不仅会整理好各值的顺序,使每个元素的值小于等于接下来那个元素的值,而且不会改变每个值出现的次数。因此,排序好的表中有两个1和两个5,而原表中只出现一次的数字都只有一个。
只要表的元素有“小于”的顺序可言,也就是具备我们通常用符号<表示的关系,就可对这些元素排序。例如,如果这些值是实数或整数,那么符号<就表示实数或整数的小于关系;如果这些值是字符串,就按字符串的词典顺序来排列(“词典顺序”的介绍详见下文附注栏)。有时候,当元素比较复杂,比如当元素是结构体时,就可能使用每个元素的一部分(比如某个特定字段)来进行比较。
词典顺序
要比较两个字符串,通常是依据它们的词典顺序进行比较的。假设c1c2…ck和d1d2…dm是两个字符串,其中每个c 和每个d 都只代表一个字符。字符串的长度k 和m 不一定是相同的。我们假设对字符而言也有<顺序,例如,在C语言中,字符就是小的整数,所以字符常量和字符变量可以在算术表达式中作为整数使用。因此,我们可以使用整数间惯有的<关系,区分两个字符中哪个字符“小于”另一个字符。这种顺序包含这样一个自然的概念,出现在字母表靠前位置的小写字母,要“小于”出现在字母表中靠后位置的小写字母,同样的道理对大写字母也成立。
这样我们可以将字符串的这种顺序称为字典、词典或字母表顺序,如下所示。如果以下任意一条成立的话,我们就说c1c2…ck< d1d2…dm 。
1. 第一个字符串是第二个字符串的真前缀(proper prefix),这表示k< m,而且对i =1,2,…,k而言,都有ci =di。根据这条规则,就有
bat<batter。作为这条规则的特例,可能有k=0,这样第一个字符串就不含任何字符。我们用希腊字母ε 表示空字符串这种不含字符的字符串。当k=0时,规则(1)表示对任何非空字符串s 而言,都有ε<s。2. 对某个i>0的值,两个字符串的前i-1个字符都相同,但第一个字符串的第i 个字符要小于第二个字符串的第i 个字符。也就是说,对j=1, 2, …, i-1,都有cj =dj,而且cj < dj。根据这条规则,
ball<base,因为这两个单词是从第3个字母起开始不同的,而ball的第三个字母是l, 要比base的第三个字母s更小。
a≤b这一比较关系总是表示,要么a< b,要么a 和b 具有相同的值。如果a1≤a2≤…≤an,也就是说,如果这些值有着非递减顺序,那么我们就说表(a1, a2, …, an)是已排序的。排序是这样一种操作,它接受任意表(a1, a2, …, an),并生成满足如下条件的表(b1, b2, …, bn)。
1. 表(b1, b2, …, bn)是已排序的;
2. 表(b1, b2, …, bn)是原表的排列。也就是说,表(a1, a2, …, an)中的每个值出现的次数,和那些值出现在(b1, b2, …, bn)中的次数是一模一样的。
排序算法接受任意的表作为输入,并生成对输入进行过排列的已排序表作为输出。
示例 2.2
考虑base,ball,mound,bat,glove,batter这列单词。有了该输入,排序算法会按照词典顺序生成输出:ball,base,bat,batter,glove,mound。
2.2.2 选择排序:一种迭代排序算法
假设要对一个具有n 个整数的数组A按照非递减顺序排序。我们可以通过对这个步骤的迭代来完成该工作:找出尚不在数组已排序部分的一个最小元素1,将其交换到数组未排序部分的第一个位置。在第一次迭代中,我们在整个数组A[0..n-1]中找出(“选取”)一个最小元素,并将其与A[0]互换位置。2在第二次迭代中,我们从A[1..n-1]中找出一个最小元素,并将其与A[1]互换位置。继续进行这种迭代。在开始第i+1次迭代时,A[0..i-1]已经是将A中较小的i 个元素按照非递减顺序排序了,而数组中余下的元素则没有特定的顺序。在第i+1次迭代开始前数组A的状态如图2-1所示。
1这里说“一个”最小元素是因为最小值可能出现多次。如果是这样,找到任何一个最小值就行了。
2为了描述数组中某个范围内的元素,我们采用了Pascal语言中的约定。如果A是数组,那么A[i..j]就表示数组A中下标从i 到j 这个范围内的那些元素。

图 2-1 在进行选择排序的第i+1次迭代前数组的示意图
对名字与值的约定
我们可以将变量视为具有名字和值的框。在提到变量时,比如
abc,我们会使用等宽字体来表示其名字;在提到变量abc的值时,我们会使用斜体字,如abc。总之,abc表示框的名字,而abc则表示它的内容。
在第i+1次迭代中,要找出A[i..n-1]中的一个最小元素,并将其与A[i]互换位置。因此,在经过第i+1次迭代之后,A[0..i]已经是将A中较小的i+1个元素按照非递减顺序排序了。在经过第n+1次迭代之后,就完成了对整个数组的排序。
图2-2展示了用C语言编写的选择排序函数。这个名为SelectionSort的函数接受数组A作为其第一个参数。第二个参数n表示的是数组A的长度。
void SelectionSort(int A[], int n)
{
int i, j, small, temp;
(1) for (i = 0; i < n-1; i++) {
/* 将small 置为剩余最小元素第一次出现时
的下标*/
(2) small = i;
(3) for (j = i+1; j < n; j++)
(4) if (A[j] < A[small])
(5) small = j;
/* 到达这里时,small 是A[i..n-1]
/* 中第一个最小元素的下标, */
/* 现在交换A[small]与A[i]。 */
(6) temp = A[small];
(7) A[small] = A[i];
(8) A[i] = temp;
}
}
图 2-2 迭代的选择排序
第(2)到(5)这几行程序从数组未排序的部分A[i..n-1]中选取一个最小元素。我们首先在第(2)行中将下标small的值设为i。第(3)到(5)这几行的for循环会依次考量所有更高的下标j,如果A[j]的值小于A[i..j-1]这个范围内的任何数组元素的值,那么就将small 置为j。这样一来,我们就将变量small的值置为A[i..n-1]中最先出现的那个最小元素的下标了。
在为下标small选好值后,在第(6)到(8)行中,我们要将处于该位置的元素与A[i]处的元素互换位置。如果small=i,交换还是会进行,只是对数组没有任何影响。请注意,要交换两个元素的位置,还需要一个临时的位置来存储二者之一。因此,我们在第(6)行将A[small]里的值移到temp中,并在第(7)行将A[i]里的值移到A[small]中,最终在第(8)行将原来A[small]里的值从temp移到A[i]中。
示例 2.3
我们来研究一下SelectionSort针对各种输入的行为。首先看看运行SelectionSort处理没有元素的数组时会发生什么。当n=0时,第(1)行中的for循环的主体不会执行,所以SelectionSort很从容地“什么事都没做”。
现在考虑一下数组只有一个元素的情况。这次第(1)行中的for循环的主体还是不会执行,这种反应是令人满意的,因为由一个元素组成的数组始终是已排序的。当n为0或1时的情况是重要的边界条件,检测这些条件下算法或程序的性能是很重要的。
最后,我们要运行SelectionSort,处理一个具有4个元素的较小数组,其中A[0]到A[3]分别是

我们从i=0起开始外层的循环,并在第(2)行将small置为0。第(3)到(5)行构成了内层的循环,在该循环中,j 依次被置为1、2和3。对于j=1,第(4)行的条件是成立的,因为A[1],也就是30,要小于A[small ],即A[0],或者说是40。因此,在第(5)行我们会将small置为1。在(3)至(5)行第二次迭代时,有j=2,第(4)行的条件还是成立,因为A[2]<A[1],所以我们在第(5)行将small置为2。在第(3)到(5)行的最后一次迭代中,有j=3,第(4)行的条件依旧成立,因为A[3]<A[2],所以在第(5)行将small置为3。
现在我们跳出内层循环,到达第(6)行。将A[small](即10)赋给temp,接着在第(7)行,将A[0](也就是40)赋给A[3],然后在第(8)行将10赋给A[0]。现在,外层循环的第一次迭代已经完成,而此时的数组A就变成下面这样了

外层循环进行第二次迭代时,有i=1,在第(2)行将small置为1。内层循环起初会将j置为2,而因为A[2]<A[1],第(5)行会将small置为2。对j=3,第(4)行的条件不成立,因为A[3]≥A[2]。因此,在到达第(6)行时,就有small=2。第(6)到(8)行会交换A[1]和A[2],让数组变成

虽然数组现在正好已排序了,但我们还是要迭代一次外层循环,这时i=2。我们在第(2)行将small置为2,内层循环此时按照j=3的情况来执行。因为第(4)行的条件不成立,small依旧为2,而在第(6)到(8)行中,我们会将A[2]与其自身“进行交换”。大家应该确认,当small=i时,这种交换是没有效果的。
键排序
在排序时,我们会对要排序的值进行比较操作。通常只对值的特定部分进行比较,而用于比较的这个部分就称为键。
例如,课表可能是具有如下形式的C语言结构体数组
Astruct STUDENT { int studentID; char *name; char grade; } A[MAX];我们可能希望通过学号、学生姓名或所在年级来排序,每项内容都可以作为键。例如,如果我们希望通过学号为结构体排序,就可以在
SelectionSort的第(4)行进行如下比较:A[j].studentID < A[small].studentID数组
A和交换中使用的临时变量temp都是struct STUDENT类型,而不是integer类型的。请注意,整个结构体都要进行交换,而不仅仅是交换键字段。交换整个结构体是很费时的,所以产生了一种更有效率的方法,即使用的另一个元素是指向
STUDENT结构体的指针的数组,并且只为第二个数组中的指针排序,结构体本身在第一个数组中保持不变。我们将这种方式的选择排序留作本节的习题。
图2-3展示了SelectionSort函数如何应用到完整的程序中,来给含有n(这里约定n≤100)个整数的序列排序。第(1)行会读取并存储数组A中的n 个整数。如果输入超过MAX,只有前MAX个整数被装入数组A。提供一条消息警告用户输入的数字过大在这里可能很实用,不过我们先不考虑这一点。
#include <stdio.h>
#define MAX 100
int A[MAX];
void SelectionSort(int A[], int n);
main()
{
int i, n;
/* 在A 中读取和存储输入 */
(1) for (n = 0; n < MAX && scanf("%d", &A[n]) != EOF; n++)
(2) ;
(3) SelectionSort(A,n); /* 排序A */
(4) for (i = 0; i < n; i++)
(5) printf("%d\n", A[i]); /* 打印A */
}
void SelectionSort(int A[], int n)
{
int i, j, small, temp;
for (i = 0; i < n-1; i++) {
small = i;
for (j = i+1; j < n; j++)
if (A[j] < A[small])
small = j;
temp = A[small];
A[small] = A[i];
A[i] = temp;
}
}
图 2-3 使用选择排序的排序程序
第(3)行调用SelectionSort来为数组排序。第(4)行和第(5)行会按照排好的顺序将这些整数打印出来。
2.2.3 习题
1. 假设用SelectionSort函数来处理包含如下几组元素的数组:
(a) 6,8,14,17,23
(b) 17,23,14,6,8
(c) 23,17,14,8,6
在每种情况下,分别会发生多少次元素的比较和交换?
2. ** 在为具有n个元素的序列排序时,SelectionSort进行(a)比较和(b)交换的最少次数及最多次数分别是多少?
3. 编写C语言函数,接受两个字符链表作为参数,如果第一个字符串在词典顺序上先于第二个字符串,就返回TRUE。提示:实现本节中描述的字符串比较算法。当两个字符串前面的字符相同时,通过在字符串尾部让该函数调用自身进行递归。除此之外,大家还可以设计迭代算法完成同样的工作。
4. * 修改习题3中的程序,使其在比较过程中忽略字母的大小写。
5. 如果所有元素都相同,选择排序会做些什么?
6. 修改图2-3中的程序,使其在数组元素不是整数而是类型为struct STUDENT的结构体时执行选择排序,就像前文附注栏“键排序”中所定义的那样。假设键字段是studentID。
7. * 进一步修改图2-3,使其能为任意类型T 的元素排序。不过,大家可以假设某个函数key可以接受某个类型为T 的元素作为参数,并为该元素返回某个任意类型K 的键。还假设有函数lt 接受类型为K 的两个元素作为参数,且若第一个元素“小于”第二个元素,就返回TRUE,否则返回FALSE。
8. 除了在数组A中使用整数下标,还可以使用指向整数的指针表示数组中的位置。使用指针重写图2-3中的选择排序算法。
9. * 正如在前文附注栏“键排序”中提到的,如果要排序的元素是诸如类型STUDENT这样的大型结构体,我们可以将它们留在原数组中保持原样,并在第二个数组中对指向这些结构体的指针排序。写下选择排序的这种变形。
10. 写一个迭代程序,打印一个整数数组中的不同元素。
11. 使用本章开始部分所描述的符号Σ和Π来表示以下内容。
(a) 1到377中所有奇数的和。
(b) 2到n(假设n 是偶数)中所有偶数的平方的和。
(c) 8到2k中所有2的n 次幂的积。
12. 证明当small = i时,图2-2中的第(6)到(8)行(进行交换的步骤)对数组A没有任何影响。
2.3 归纳证明
数学归纳法是种实用的技巧,可用来证明命题S(n)对所有非负整数n都为真,或者更一般地说,对所有不小于某个下限的整数都成立。例如,在本章开头,我们提到过可以通过对n的归纳,证明对于所有的n≥1,命题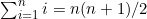 都为真。
都为真。
现在,假设S(n)是有关整数n的任意命题。在对命题S(n)最简单的归纳证明形式中,要证明以下两个事实。
1. 依据情况。多为S(0),不过,依据可以是对应任意整数k的S(k),这样就是证明只有在n≥k 时命题S(n)成立。
2. 归纳步骤。我们要证明对所有的n≥0(或者如果依据为S(k),则是对所有的n≥k),都可由S(n)推出S(n+1)。在证明过程中的这个部分,我们假设命题S(n)为真。S(n)称为归纳假设,而且要假设它为真,接着我们必须证明S(n+1)为真。
命名归纳参数
我们可以通过为要证明的命题S(n)中的变量n 指定直观含义,对归纳作出解释,这种做法通常很有用。如果n 如示例2-4中那样没有特殊含义,就可以说“对n 进行归纳证明”。在其他例子中,n 可能具有实际意义,比如示例2.6中,n 表示码字中的比特数,于是就可以说,“对码字中的比特数进行归纳证明”。
图2-4展示了从0开始的归纳。对每个整数n,都有命题S(n)要证明。对S(1)的证明用到了S(0),对S(2)的证明用到了S(1),以此类推,就如图中箭头所表示的。每个命题依赖前一个命题的方式是统一的。也就是说,通过对归纳步骤的一次证明,我们可以证明图2-4中箭头表示的每个步骤。

图 2-4 在归纳证明中,命题S(n)的每个实例都是用比n 的值小1的命题实例证明的
示例 2.4
作为数学归纳法的示例,我们来证明如下命题S(n)
命题。对任意的n≥0,都有S(n):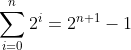
这就是说,从2的0次幂到2的n次幂,2的整数指数幂之和要比2的n-1次幂小13。例如,1+2+4+8=16-1,证明过程如下。
3证明S(n)也可以不使用归纳法,只需要利用几何级数的求和公式即可。不过,该示例可以作为介绍数学归纳法的简单例子。此外,利用我们在高中可能见过的几何级数或算术级数求和公式来证明该命题是相当不严谨的,而且严格地讲,证明这些求和公式也要用到数学归纳法。
依据。要证明该依据,我们将等式S(n)中的n 替换为0,这样S(n)就成了
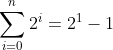 (2.2)
(2.2)
对i=0,等式(2.2)左边的和式中只有一项,这样(2.2)左边的和为20,也就是1。而等式(2.2)右边是21-1,也就是2-1,其值同样是1。因此我们证明了S(n)的依据,也就是说,我们证明了对于n=0,该等式成立。
归纳。现在必须要证明归纳步骤。我们假设S(n)为真,并证明将该等式中的n 替换为n+1后等式也成立。要证明的等式S(n+1)如下
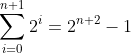 (2.3)
(2.3)
要证明等式(2.3)成立,我们先要考虑等式左侧的和
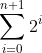
这个和几乎与S(n)左侧的和一模一样,S(n)左侧的和为
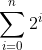
只不过等式(2.3)左侧多了i=n+1时的项,也就是2n+1这一项。
因为可以假定归纳假设S(n)在等式(2.3)的证明过程中为真,所以应该将S(n)利用起来。可以将等式(2.3)中的和分为两个部分,其中之一是S(n)中的和。也就是说,要将i=n+1时的最后一项分离出来,将其写为
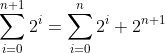 (2.4)
(2.4)
现在可以利用S(n)了,可以用S(n)的右边2n+1-1来替换等式(2.4)中的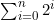 ,于是有
,于是有
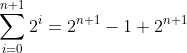 (2.5)
(2.5)
将等式(2.5)的右边简化后,它就成了2×2n+1-1,也就是2n+2-1。现在可以看到,等式(2.5)左侧的和值,与等式(2.3)的左边相同,而等式(2.5)的右边也与等式(2.3)的右边相同。因此,就利用等式S(n)证明了等式(2.3)的正确性,这段证明过程就是归纳步骤。由此得出的结论是,S(n)对每个非负整数n都成立。
2.3.1 归纳证明为何有效
变量的替换
在需要替换变量,比如涉及同一变量的表达式,如S(n)中的n 时,常会产生混淆。例如,我们要用n+1替换S(n)中的n,以得出等式(2.3)。要进行这种替换,必须先标记出S 中每个出现n的地方。有个很实用的办法,就是先用某个未在S 中出现过的新变量(比如m)来代替n。例如,S(n)就成了
接着在每个出现m 的地方将其替换成所需的表达式,即本例中的n+1,就得到
若将(n+1)+1简化为n+2,就得到了等式(2.3)。
请注意,我们应该给用来替换的表达式加上括号,以避免意外改变运算顺序。例如,假设用n+1替换表达式2×m 中的m,但没有给n+1加上括号,那么就会得到2×n+1,而不是正确的表达式2×(n+1)(也就是2×n+2)。
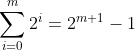
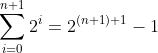
在归纳证明中,我们先证明了S(0)为真。接下来要证明,如果S(n)为真,那么S(n+1)是成立的。不过为什么接着能得出S(n)对所有n≥0都为真呢?我们会提供两个“证据”。某位数学家曾指出,我们证实归纳法有效的每个“证据”,都需要归纳证据本身,因此就根本没有证据。从技术上讲,归纳肯定能作为公理,然而很多人会发现以下直觉认识也是有用的。
在接下来的内容中,我们假设作为依据的值是n=0。也就是说,我们知道S(0)为真,而且对于所有大于0的n,如果S(n)为真,那么S(n+1)为真。如果作为依据的值是其他整数,也可以做出类似的论证。
第一个“证据”:归纳步骤的迭代。假设要证明对某个特定的非负整数a 有S(a)为真。如果a=0,只要援引归纳依据S(0)的真实性即可。如果a>0,那么就要进行如下论证。从归纳依据可知S(0)为真。对于命题“S(n)可推出S(n+1)”,若将n 替换为0,就成了“S(0)可推出S(1)”。因为我们知道S(0)为真,现在就知道S(1)为真。类似地,如果用1替换n,就有“S(1)可推出S(2)”,这样一来就知道S(2)也为真。用2来替换n,则有“S(2)可推出S(3)”,所以S(3)也为真,以此类推。不管a取什么值,最终都能得到S(a),这样就完成了归纳。
第二个“证据”:最少反例。假设至少有一个n 的值可以使S(n)不为真。设a是令S(a)为假的最小非负整数。如果a=0,就与我们的归纳依据S(0)相互矛盾,所以a 一定是大于0的。不过如果a>0,而且a是令S(a)为假的最小非负整数,那么S(a)肯定为真。现在,在归纳步骤中,如果用a-1代替n,就会有S(a-1)可推出S(a)。因为S(a-1)为真,那么S(a)肯定为真,又相互矛盾了。因为我们假设存在非负整数n 使S(n)为假,并引出了矛盾,所以S(n)对任何n≥0都一定为真。
2.3.2 检错码
现在我们要介绍“检错码”的例子。检错码本身就是个有意思的概念,而且引出了一段有趣的归纳证明。当我们通过数据网络传输信息时,会将字符(字母、数字、标点符号,等等)编码成位串,即0和1组成的序列。此时假设字符是由7位表示的。不过通常每个字符要传输不止7位,而第8位可以用来检测一些简单的传输错误。也就是说,偶尔有那么一个0或1会因为传输噪声发生改变,结果接收到的就是相反的位,进入传输线路的0成了1,而1成了0。如果通信系统能在8位中的一位发生变化时发出通知,从而发出重传信号,将会很有用。
要检测某一位的改变,必须保证任意两个表示不同字符的位序列不只有一个位置不同。不然的话,如果那个位置发生变化,结果就成了代表另一个字符的代码,可能将没法检测到错误的发生。例如,如果一个字符使用位序列01010101表示,而另一个由01000101表示,那么如果左起第4个位置发生改变,就会将前者变成后者。
要确保不同字符的代码不只有一个位置不同,方法之一是在惯用于表示字符的7位码前加上一个奇偶校验位。如果位序列中有奇数个1,则称其具有奇校验。如果位序列中有偶数个1,则其具有偶校验。我们选择的编码方式是以具有偶校验的8位码来表示字符,也可以选用带奇校验的代码。通过明智地选择校验位,我们可使奇偶校验成为偶校验。
示例 2.5
用来表示字符A的传统的ASCII(音“ask-ee”,表示American Standard Code for Information Exchange,即“美国信息交换标准码”)7位码是1000001。该序列的7位中已经有偶数个1,所以我们为其加上前缀0,得到01000001。用来表示C的传统代码是1000011,这和表示A的7位码只在第6位是不同的。不过,这个代码具有奇校验,所以我们给它加上前缀1,从而产生具有偶校验的8位码11000011。请注意,在给表示A和C的代码前加上校验位后,就有了01000001和11000011这两个位序列,它们的第1位和第7位这两位是不同的,如图2-5所示。

图 2-5 可以选择初始奇偶校验位,使得8位码总是具有偶校验
我们总是能选择一个奇偶校验位加到7位码上,从而让得到的8位码中有偶数个1。如果表示字符的7位码本来就有偶校验,就选择0作为其奇偶校验位,而对本具有奇校验的7位码,则是选择奇偶校验位1。不管哪种情况,8位码中都是包含偶数个1。
两个具有偶校验的位序列不可能只有一个位置不同。如果两个这样的位序列只有一个位置不同,那么其中一个肯定要比另一个多一个1。因此,一个序列必然具有奇校验,而另一个则是偶校验,与我们都具有偶校验的假设是矛盾的。因此可得,通过加上奇偶校验位使1的数量为偶,可为字符创建检错码。
奇偶校验位模式是相当“高效”的,从某种意义上讲,它让我们可以传输很多不同的字符。请注意,n 位的位序列有2n个,因为我们可以为第一位选择二值(0或1)之一,可以为第二位选择二值之一,等等,总共可形成2×2×…×2(n 个2相乘)个位串,所以,最多有望能用8位来表示28=256个字符。
然而,在奇偶校验模式中,只能选择其中7位,第8位是无从选择的。因此最多可以表示27,即128个字符,而且能检测某一位上的错误。这样也不错,我们可以用256个中的128个,也就是8位码所有可能组合的一半,来作为字符的合法代码,还能检测某一位中出现的错误。
类似地,如果我们使用n 位的位序列,选择其中一位作为奇偶校验位,那么就能用n-1位的位序列加上合适的奇偶校验位前缀(其值由另外那n-1位确定)来表示2n-1个字符。n 位的位序列有2n个,我们可以表示2n中的2n-1个,或者说是可能字符数的一半,而且可以检测位序列中任意一位的错误。
有没有可能检测多个错误,并使用超过位序列多于一半的可能组合作为合法代码呢?下一个例子将告诉你这是不可能的。这里的归纳证明使用的命题对0来说不为真,所以我们必须选用一个更大的归纳依据,也就是1。
示例 2.6
我们要对n 进行归纳,以证明以下命题。
命题S(n)。如果C 是长度为n 的位串的检错(即两个不同的位串不会刚好只有一个位置不同)集合,那么C 最多含有2n-1个位串。
这个命题对n=0来说不为真。S(0)表示长度为0的位串的检错集合最多只有2-1个,也就是半个位串。从技术上讲,只由空位串(不含任何位置的位串)组成的集合C,是长度为0的位串的检错集合,因为C 中任意两个位串不会只有一个位置不同。集合C 中不只是有半个位串,它其实有一个位串。因此,S(0)为假。不过,对于所有的n≥1,S(n)都为真,正如我们在下文将会看到的。
依据。依据为S(1),也就是,任何检错的长度为1的位串的集合最多只有21-1=20=1个位串。长度为1的位串只有两个,一个是位串0,一个是位串1。然而,在检错的集合中,我们不能同时拥有这两者,因为它们正好只有一个位置不同。因此,每个n=1的检错集合肯定最多只有一个位串。
归纳。设n≥1,假定归纳假设——长度为n的位串的检错集合最多只有2n-1个位串——为真。我们必须用这一假设证明,任何长度为n+1的位串的检错集合C 最多只有2n个位串。因此,将C 分为两个集合:C0,即C 中0开头的位串组成的集合,以及C1,即C 中1开头的位串组成的集合。例如,假设n=2,C 就是长度为n+1=3,而且有一个奇偶校验位的位串的集合。那么,如图2-6所示,C 由位串000、101、110和011组成,C0由位串000和011组成,C1则由位串101和110组成。
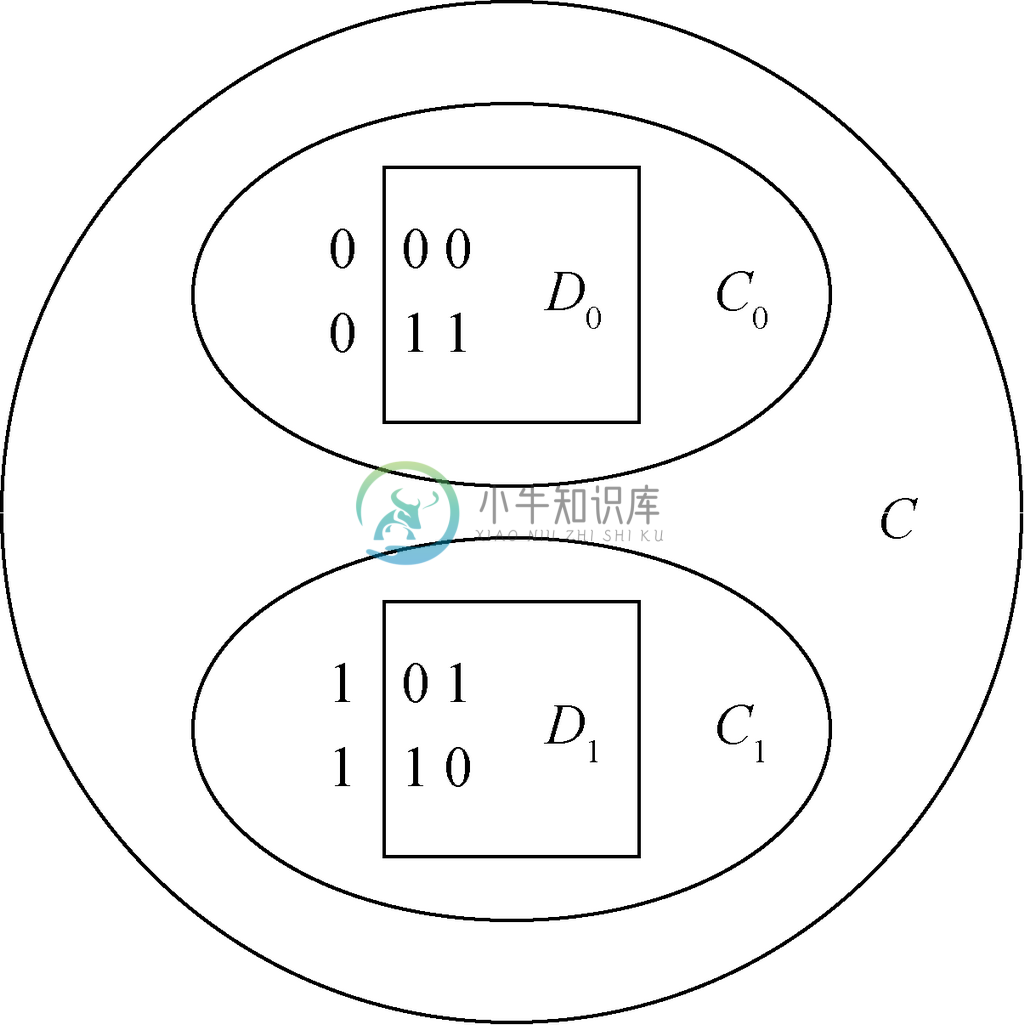
图 2-6 集合C 被分为0开头位串的集合C0和1开头位串的集合C1,D0和D1则分别由删除了开头的0和1的位串组成
考虑一下集合D0,它含有删除了C0中那些位串开头的0后形成的位串。在上面的例子中,D0含有位串00和11。我们要求D0不能含有两个只有一位不同的位串。原因在于,如果有这样两个位串,比方说a1a2…an和b1b2…bn,然后恢复它们开头的0,就会给出两个C0中的位串,0a1a2…an和0b1b2…bn,而这两个位串也只有一位是不同的。不过C0中的位串也是C 中的元素,而且我们知道C 中不能有两个位串只有一个位置不同。因此,D0也不行,所以D0是检错集合。
现在可以应用该归纳假设得出,D0作为一个长度为n的位串的检错集合,最多有2n-1个位串。因此,C0最多有2n-1个位串。
同样,可以对C1集合作出类似推论。设D1集合内的元素是删除C1中位串开头的1形成的位串。D1是长度为n的位串的检错集合,而根据归纳假设,D1最多只有2n-1个位串。因此,C1也最多只有2n-1个位串。然而,C中的每个位串不是在C0中就是在C1中。因此,C中最多有2n-1+2n-1,也就是2n个位串。
我们已经证明了S(n)可推出S(n+1),所以可以得出结论,S(n)对所有的n≥1都为真。我们在声明中排除了n=0的情况,因为归纳依据是n=1,而不是n=0。现在看到带奇偶校验检查的检错集合是尽可能大的,因为它们在使用n个位来构成位串时能有2n-1个位串。
如何构造归纳证明
没有什么可以保证给出任意(真)命题S(n)的归纳证明。找到归纳证明,就像找到任意类型的证明那样,或者就像写出能正常运行的程序那样,是项挑战智力的任务,而且我们只有几句话的意见可提。如果大家研究了示例2.4和示例2.6中的归纳步骤,就会注意到,每种情况下,都必须对试图证明的命题S(n+1)加以处理,使其由归纳假设S(n)和某些额外内容组成。在示例2.4中,我们将和
1+2+4+…+2n+2n+1
表示为归纳假设告诉我们的和
1+2+4+…+2n
加上2n+1这一项。
在示例2.6中,我们用两个长度为n的位串集合(称为D0和D1)表示长度为n+1的位串集合C,这样一来,就可以将归纳假设应用到这些集合上,并推断出这两个集合都是大小有限的。
当然,对命题S(n+1)加以处理,从而使我们能应用归纳假设,只是更普遍的解题箴言“运用给定条件”的一个特例。当必须处理S(n+1)的“额外”部分,并利用S(n)完成对S(n+1)的证明时,才是最让人头疼的。不过,以下规则是普遍适用的。
- 归纳证明必须在某个地方表述“……而且通过归纳假设我们可知……”。如果没有的话,就不算是归纳证明。
2.3.3 习题
1. 通过对n从n=1起进行归纳,证明以下公式。
(a) 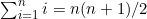
(b) 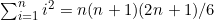
(c) 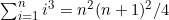
(d) 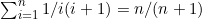
2. 形如 tn=n(n+1)/2的数字称为三角形数,因为将弹珠排列成等边三角形,每条边上排n个,那么弹珠的总数就是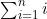 ,而从我们在习题(1)中证明的结论可知这是tn个弹珠。例如,保龄球瓶排列成每条边上有4个球瓶的等边三角形,共有t4=4×5/2=10个保龄球瓶。用归纳法证明
,而从我们在习题(1)中证明的结论可知这是tn个弹珠。例如,保龄球瓶排列成每条边上有4个球瓶的等边三角形,共有t4=4×5/2=10个保龄球瓶。用归纳法证明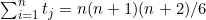
3. 判断以下位序列的奇偶校验是偶校验还是奇校验。
(a) 01101
(b) 111000111
(c) 010101
4. 假设我们用3个数字,比如0、1和2,来为符号编码。由0、1和2组成的位串集合C 中,如果任意两个位串不只有一个位置不同,那么这个集合就是检错的。例如,{00,11,22}就是长度为2的位串的检错集合。证明对任意的n≥1,使用数字0、1和2组成的长度为n 的位串的检错集合最多只有3n-1个位串。
5. * 证明:对任意的n≥1,存在使用0、1和2三个数字组成的长度为n 的位串的检错集合,其中含有3n-1个位串。
6. * 证明:如果使用k 个符号,对任意的k≥2,都有使用k个不同符号作为“数字”并且长度为n 的位串的检错集合,其中具有kn-1个位串,但这样的位串集合肯定不可能含有超过kn-1个位串。
7. * 如果n≥1,则使用0、1和2这三个数字组成的位串中,连续位置完全不具相同数字的位串共有3×2n-1个。例如,长度为3的此类位串共有:010、012、020、021、101、102、120、121、201、202、210和212。通过对位串的长度进行归纳来证明该结论。这个公式对n=0来说是否为真?
8. * 证明:1.3节中讨论过的行波进位加法算法能产生正确的答案。提示:通过对i 的归纳证明,考虑从右端起的i 位,两个加数后i 位的和,其二进制形式为进位位后跟上目前为止所生成的i 位结果。
9. * 含n个项的几何级数a, ar2, ar3,…, arn-1的和公式是
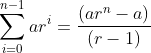
通过对n 的归纳来证明该公式。请注意,要让公式成立,必须假设r ≠1。在证明过程中会在哪里用到这一假设呢?
10. 第一项为a,公差为b的算术级数a, (a+b), (a+2b), …, (a+(n-1)b)的求和公式为
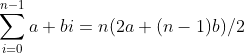
(a) 通过对n 的归纳证明该公式。
(b) 证明习题1中的(a)也是该公式的一例。
11. 给出两段非正式的证明,表明虽然命题S(0)为假,但归纳可以从1开始“起效”。
12. 通过对位串长度的归纳证明,由奇校验位串构成的代码也可以检错。
13. ** 如果某种编码中任意两个位串不同的位置不少于3位,那么我们就可以通过找出该编码中与接收到的位串仅有一位不同的唯一位串,纠正单个错误。事实证明,有一种针对7位位串的编码,它可以纠正单个错误并含有16个位串。试着找出这种编码。提示:推理出来可能是最佳方法,不过如果推理失败,可以写程序来搜索这样的编码。
14. * 偶校验码可否检出“双重错误”,也就是两个不同位上的改变?它能否纠正单个错误?
算术和与几何和
高中代数中的两个公式我们会经常用到。它们都有着有趣的归纳证明,也就是我们在习题(9)和习题(10)中让读者证明的。
算术级数(即等差数列)是一列具有以下形式的n个数字。
a, (a+b), (a+2b), …, (a+(n-1)b)
第一项为a,而每一项都要比前一项大b。这n个数字的和,就是第一项和最后一项的平均数的n 倍,也就是
例如,考虑一下3+5+7+9+11的和。总共有n=5项,第一项为3,最后一项为11。因此,这个和就是5×(3+11)/2=5×7=35。可以把这5个数加起来,来证明这个和是正确的。
几何级数(即等比数列)是一列具有如下形式的n个数字。
a,ar,ar2,ar3,…,arn-1
也就是说,第一项为a,而每一项都是前一项的r倍。n项几何级数的和公式是
在这里,r可以大于1,也可以小于1。如果r=1的话,以上公式就不可用了,不过所有项都是a,其和也很明显,就是an。
作为几何级数求和的例子,考虑一下1+2+4+8+16。这时n=5,第一项a就是1,而公比r=2,因此这个和就是
(1×25-1)/(2-1)=(32-1)/1=31
再举一个大家可以验证的例子,考虑1+1/2+1/4+1/8+1/16。还是n=5而且a=1,不过r=1/2,这个和就是
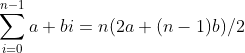
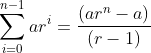
简单归纳的模板
我们对2.3节进行总结,给出适用于该节中归纳证明过程的简单模板。2.4节中将介绍更为通用的模板。
1. 指定待证明的命题S(n)。表明自己要通过对n的归纳,对所有n≥i0,证明S(n)。这里的i 0是作为归纳依据的常数,通常i 0是0或1,不过它也可以是任意整数。直观地解释n 的含义,比如,n 是码字的长度。
2. 陈述依据情况,S(i0)。
3. 证明依据情况,也就是解释S(i0)为何为真。
4. 陈述对某些n≥i0,假设有S(n),也就是陈述“归纳假设”,建立归纳步骤。用n+1替换命题S(n)中的n来表示S(n+1)。
5. 假定归纳假设S(n)为真,证明S(n+1)。
6. 得出S(n)对所有n≥i0都(但对更小的n不一定)为真结论。
2.4 完全归纳
目前为止所看到的例子,在证明S(n+1)为真时,都只用到了S(n)作为归纳假设。不过,由于要对参数从归纳依据开始增加的值证明命题S,我们可以对从归纳依据到n 的所有i 的值使用S(i ),这种形式的归纳叫作完全归纳(有时也称为完美归纳或强归纳)。而2.3节所示的简单归纳形式,也就是只用S(n)来证明S(n+1),有时被称为弱归纳。
先来考虑一下如何进行从归纳依据n=0开始的完全归纳。要通过以下两个步骤来证明S(n)对所有n≥0为真。
1. 先证明归纳依据,S(0)。
2. 假设S(0),S(1),…,S(n)全为真,作为归纳假设。从这些命题来证明S(n+1)成立。
至于在2.3节中描述的弱归纳,也可以在选择0之外再选择某个值a作为归纳依据,然后证明S(a)归纳依据。而且在归纳步骤中,可以只假定S(a),S(a+1),…S(n)为真。请注意,弱归纳是完全归纳的一个特例,应用弱归纳,我们在之前的命题中只选择S(n)来证明S(n+1)。
图2-7表示了完全归纳的原理。命题S(n)的每个实例在其证明过程中都可以使用下标比其小的任意实例。
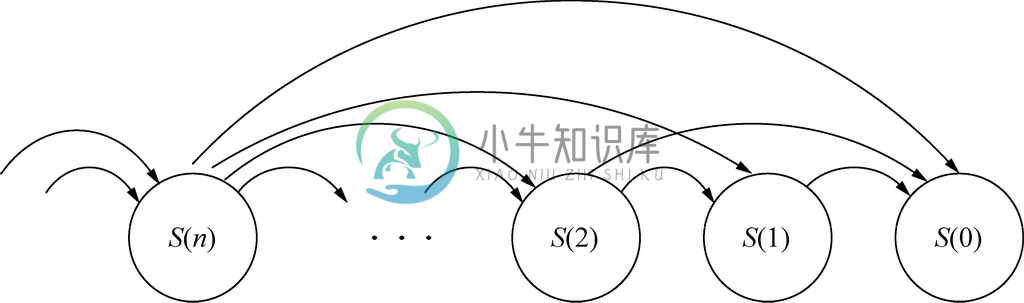
图 2-7 完全归纳允许每个实例在其证明过程中使用在它之前的一个、一些或是所有实例
2.4.1 使用多个依据情况进行归纳
在进行完全归纳时,拥有多个依据情况往往是很实用的。如果希望证明命题S(n)对所有n≥i0都为真,那么不仅可以用i0作为依据情况,而且能用一些大于i0的连续整数(假设是i0,i0+1,i0+2,…,j0 )作为依据情况。然后我们必须完成以下两步。
1. 证明每个依据情况,即命题S(i0),S(i0+1),…,S(j0)。
2. 假设对于某个n≥j0,S(i0),S(i0+1),…,S(n)全成立,作为归纳假设,并证明S(n+1)为真。
示例 2.7
第一个完全归纳的例子是使用多个依据情况的简单例子。正如我们将要看到的,它只是有限程度的“完全”。为了证明S(n+1),我们没有使用S(n),而只使用了S(n-1)。在更普遍的完全归纳推理中,我们要使用S(n)、S(n-1)以及命题S的很多其他实例。
下面通过对n 的归纳来对所有的 n ≥ 0 证明以下命题。4
4其实,这个命题对所有的n,不论n是正整数还是负整数,都是成立的,不过n为负整数的情况需要另外进行归纳推理,我们将这个证明过程留给大家作为习题。
命题 S(n)。总是存在整数a和b(正整数、负整数或0),使n=2a+3b。
依据。我们同时采用0和1作为依据情况。
1. 对于n=0,可以选用a=0和b=0。显然0=2×0+3×0。
2. 对于n=1,可以选用a=-1和b=1。然后有1=2×(-1)+3×1。
归纳。现在,可对任意的n≥0,假设S(n)为真,并证明S(n+1)为真。请注意,可假设n至少是从我们已证明的依据(这里n≥1)起的连续值中最大的那个。而命题S(n+1)就是说存在某些整数a 和b,使得n+1=2a+3b。
归纳假设表明S(0),S(1),…,S(n)全部为真。请注意,序列从0开始是因为它是连续依据情况的下限。因为可以假设n≥1,我们知道n-1≥1,因此S(n-1)为真。该命题就是说,存在整数a 和b,使得n+1=2a+3b。
由于命题S(n+1)中需要用到a,因此这里重新声明S(n-1)使用不同名称的整数,比方说存在整数a'和b',使得
n-1=2a'+3b' (2.6)
如果给(2.6)的两边都加上2,就得到n+1=1(a'+1)+3b'。如果接着令a=a'+1,b=b',那么就存在整数a 和b,使得命题n+1=2a+3b为真。该命题就是S(n+1),所以我们已经证明了该归纳推理。请注意,在证明过程中,没有用到S(n),但用到了S(n-1)。
2.4.2 验证完全归纳
就像2.3节中讨论的普通归纳(或“弱”归纳)那样,通过“最少反例”论证,完全归纳也可以被直观地证实为一种证明技巧。令依据情况为S(i0),S(i0+1),…,S(j0),并假设已经证明了对任意的n≥j0,S(i0),S(i0+1),…,S(n)能一起推出S(n+1)。现在,假设至少存在一个不小于i0的n值使S(n)不成立,并设b是令S(b)为假的最小的不小于i0的整数。那么b就不能是i0和j0之间的整数,否则与归纳依据矛盾。此外,b也不能大于j0。不然,S(i0),S(i0+1),…,S(b-1)全为真。而归纳步骤接着就会告诉我们S(b)也为真,这样就产生了矛盾。
2.4.3 算术表达式的规范形式
现在探讨将算术表达式变形为等价形式的例子。它表明完全归纳利用了可假设待证明的命题S 对所有n 以下(包含n)的参数都为真这一事实。
作为一种激励形式,编程语言的编译器可以利用算术运算符的代数形式,重新排列所计算的算术表达式中操作数的顺序。这种重排的目标是为计算机找出一种比表达式原有计算顺序耗时更少的方式来计算该表达式。
在本节中,只考虑含有一种结合和交换运算符(比如+)的算术表达式,并看看可以对操作数进行怎样的重新排列。我们将证明,如果有任意只含“+”运算符的表达式,那么该表达式的值,要与其他任何只对同样操作数使用“+”的表达式的值相等,不管以何种顺序排列及(或)以何种形式组合。例如
(a3+(a4+a1))+(a2+a5)=a1+(a2+(a3+(a4+a5)))
我们将进行两段单独的归纳推理,以证明这一说法,其中第一段归纳推理是完全归纳。
结合性和交换性
回想一下加法结合律,就是说在求三个数的和时,既可以将前两个数相加,然后加上第三个数得到结果,也可以用第一个数,加上第二个数与第三个数相加的结果,两种情况下结果是相同的。形如:
(E1+E2)+E3=E1+(E2+E3)
其中,E1、E2和E3都是算术表达式。例如,
(1+2)+3=1+(2+3)
这里有E1=1、E2=2,以及E3=3。还比如
((xy)+(3z-2))+(y+z)=xy+((3z-2)+(y+z))
这里有E1=xy,E2=3z-2,以及E3=y+z。
接着回想一下加法交换律,就是说可以将两个表达式按照任意顺序相加。形如:
E1+E2=E2+E1
例如,1+2=2+1,以及xy+(3z-2)=(3z-2)+xy。
示例 2.8
我们要对n(表达式中操作数的数目)进行完全归纳,以证明命题S(n)成立。
命题 S(n)。如果E 是含有“+”运算符和n 个操作数的表达式,而a是其中一个操作数,那么可以通过使用结合律和交换律,将E 变形成a+F 的形式,其中表达式F 含有E 中除a之外的所有操作数,而且这些操作数是使用“+”运算符以某种顺序组合在一起的。
命题S(n)只对n≥2成立,因为表达式E 中至少要出现一次“+”运算符。因此,我们要使用n=2作为归纳依据。
依据。令n=2。那么E 只可能是a+b或b+a,如果说a之外的那个操作数是b 的话。在a+b 中,令F 为表达式b,那么命题就成立了。而在b+a 的情况下,注意到通过使用加法交换律,b+a 可以变形为a+b,因此我们就可以再次令F=b。
归纳。设E 有n+1个操作数,并假设S(i )对i=2,3,…,n 都为真。我们需要为n≥2证明该归纳步骤,所以可假设E 最少有3个操作数,也就是至少出现两次“+”运算符。可以将E 写为E1+E2,其中E1和E2是某些表达式。因为E 中正好有n+1个操作数,而且E1和E2都一定至少含有这些操作数中的一个,这样一来E1和E2中的操作数都不能超过n 个。因此,归纳假设适用于E1和E2,只要它们都不止有一个操作数(因为我们开始时将n=2作为依据)。有4种情况必须考虑:a是在E1中还是在E2中,以及a是否为E1或E2中唯一的操作数。
(a) E1就是a本身。当E为a+(b+c)时,就是这种情况。这里E1就是a,而E2就是b+c。在这种情况下,E2就是F,也就是说,E 本身就已经是a+F 的形式。
(b) E1含有多个操作数,a 是其中一个。比如
E=(c+(d+a))+(b+e)
其中E1=c+(d+a),E2=b+e。这里,因为E1的操作数不超过n个,但至少达到了两个,所以可以应用归纳假设,使用交换律和结合律,将E1变形为a+E3。因此,E可以变形为(a+E3)+E2。对该式应用结合律,就能将E进一步变形为a+(E3+E2)。这样,我们就可以选择F为E3+E2,这就证明了这种情况下的归纳步骤。对本例中的E,也可以假设将E1=c+(d+a)变形为a+(c+d)。那么E就可以重新分组为a+((c+d)+(b+e))。
(c) E2就是a。例如,E=b+(a+c)。这种情况下,可以用交换律将E 变形为a+E1,如果令F 为E1,这就是我们想要的形式。
(d) E2含有包括a 在内的多个操作数。比方说,E=b+(a+c),这时可以用交换律将E 变形成E2+E1,这样就成了情况(b)。如果E=b+(a+c),可将E 先变形为(a+c)+b。通过归纳假设,a+c可以转换成所需的形式,事实上,结果已经出来了。然后结合律就将E 变形为a+(c+b)。
在这4种情况中,都是将E 变形为所需的形式。因此,归纳步骤得到了证明,可以得出S(n)对所有的n≥2都为真的结论。
示例 2.9
示例2.8中的归纳证明直接引出了一种将表达式转换成所需形式的算法。考虑如下表达式作为例子:
E=(x+(z+v))+(w+y)
假设v 是我们希望“拉出来”的那个操作数,也就是扮演示例2.8的变形中a的那个角色。一开始,我们介绍一个符合情况(b)的例子,其中E1=x+(z+v ),而E2=w+y。
接着,必须对表达式E1进行处理,从而将v“拉出来”。E1符合情况(d),因此我们先用交换律将其变形为(z+v )+x。作为情况(b)的实例,必须对表达式z+v(情况(c)的实例)加以处理,因此要通过交换律将其变形为v+z。
现在E1被变形为(v+z)+x,接着使用结合律将其变形成v+(z+x),也就是将E 变形成了(v+(z+x))+(w+y)。通过结合律,可把E 变形为(v+(z+x))+(w+y)。因此,E+v+F,其中F 就是表达式(z+x)+(w+y)。图2-8总结了整个变形过程。
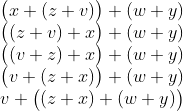
图 2-8 使用交换律和结合律,可以将任意操作数(比如v)“拉出来”
现在,可以使用示例2.8中证明过的命题来证明我们的原始论点,也就是说任意两个只涉及+运算符与同一些不同操作数的表达式,都可以通过结合律和交换律相互变形。这里是用2.3节中讨论的弱归纳证明的,没有使用完全归纳。
示例 2.10
让我们通过对表达式中操作数的个数n 的归纳证明以下命题。
命题T(n)。如果E 和F 是只含+运算符以及同一组n个不同操作数的表达式,那么可以通过多次应用结合律和交换律将E 变形为F。
依据。如果n=1,那么两个表达式肯定都只有一个操作数a。因为E 和F 是相同的表达式,所以E 确实“可变形为”F。
归纳。假设T(n)对某些n≥1为真,现在要证明T(n+1)为真。设E 和F 是具有同一组n+1个操作数的表达式,由于n+1≥2,那么示例2.8中的命题S(n+1)必然成立。因此,我们可将E 变形为a+E1,其中E1是含有E 中其他n个操作数的表达式。类似地,可以将F 变形为a+F1,其中F1与E1含有相同的n个操作数。更重要的是,在这种情况下,我们还可以进行逆向的变形,使用结合律和交换律将a+F1变形为F。
现在可以对E1和F1援引归纳假设T(n)。这两个表达式具有相同的n个操作数,因此归纳假设可以应用。这就是说我们可将E1变形为F1,所以可将a+E1变形为a+F1。因此我们可以通过如下变形
E → … →a + E1 使用 S(n)
→ … →a + F1 使用 T(n)
→ … →F 逆向使用 S(n+1)
将E 变形为F。
示例 2.11
让我们将E=(x+y)+(w+z)变形为F=((w+z)+y)+x。先选择一个要“拉出来”的操作数,比如说是w。如果审视示例2.8中的情况,就会发现我们对E进行了一系列变形
(x+y)+(w+z)→(w+z)+(x+y)→w+(z+(x+y)) (2.7)
而对F 进行了如下变形
((w+z)+y)+x→(w+(z+y))+x→w+((z+y)+x) (2.8)
现在有了将z+(x+y)变形为(z+y)+x 的子问题。我们要通过将x“拉出来”来解决这一问题,需要进行的变形是
z+(x+y)→(x+y)+z→x+(y+z) (2.9)
和
(z+y)+x→x+(z+y) (2.10)
这又带来了将y+z 变形为z+y 的子问题,只要应用交换律便可解决该问题。严格地说,我们使用了示例2.8的技术,“拉出”了每个表达式中的y,为每个表达式留下y+z。然后示例2.10中的依据情况告诉我们,表达式z可以“变形为”它本身。
通过行(2.9)中的步骤,可以将z+(x+y)变形为(z+y)+x,接着对子表达式y+z 应用交换律,最后再反向使用行(2.10)中的变形。我们把这些变形当作将(x+y)+(w+z) 变形为((w+z)+y)+x 的中间过程。首先要应用行(2.7)中的变形,接着用刚讨论的变形将z+(x+y)变形为(z+y)+x,最后再反向使用行(2.8)中的变形。整个变形过程可概括为图2-9所示的情况。
(x y) (w z) 表达式E
(w+z)+(x+y) (2.7)的中间形式
w+(z+(x+y)) (2.7)的最终形式
w+((x+y)+z) (2.9)的中间形式
w+(x+(y+z)) (2.9)的最终形式
w+(x+(z+y)) 交换律
w+((z+y)+x) 反向使用(2.10)
(w+(z+y))+x 反向使用(2.8)的中间形式
((w+z)+y)+x 表达式F,反向使用(2.8)的最终形式
图 2-9 使用交换律和结合律将一个表达式变形为另一个表达式
2.4.4 习题
所有归纳推理的模板
以下形式的归纳证明,涵盖了具有多个依据情况的完全归纳。它还将2.3节中介绍的弱归纳作为一种特例包含其中,并包含了只有一个依据情况的一般情况。
1. 指定要证明的命题S(n)。声明要通过对n 的归纳,证明S(n)对n≥i0为真。指定i0的值,通常是0或1,但也可以是其他整数。直观地解释n 表示什么。
2. 陈述依据情况(一个或多个)。这些将是从i0起到某个整数j0的所有整数。通常j0=i0,不过j0也可以是其他整数。
3. 证明各个依据情况S(i0),S(i0+1),…,S(j0)。
4. 声明假设S(i0),S(i0+1),…,S(n)为真(就是“归纳假设”),并要证明S(n+1),以此来建立归纳步骤。声明自己在假设n≥j0,也就是n至少要跟最大的依据情况一样大。通过用n+1替换S(n)中的n 来表示S(n+1) 。
5. 在(4)中提到的假设下证明S(n+1)。如果归纳为弱归纳而不是完全归纳,那么证明中只需要用到S(n),不过用归纳假设中的任一或全部命题都是可以的。
6. 得出S(n)对所有的n≥i0(但不一定对更小的n)都为真。
1. 从表达式E=(u+v)+((w+(x+y))+z)中依次“拉出”每个操作数。也就是说,从E 的每个部分开始,并使用示例2.8中的技巧将E 变形为u+E1这样的表达式。接着再将E1变形为v+E2这样的表达式,以此类推。
2. 使用示例2.10中的技巧完成以下变形。
(a) 将w+(x+(y+z))变形为((w+x)+y)+z
(b) 将(v+w)+((x+y)+z)变形为((y+w)+(v+z))+x
3. * 设E 是含+、-、*和/这几种运算符的表达式,其中每种运算符都是二元的,也就是说,这些运算符都接受两个操作数。对运算符在E 中出现的次数进行完全归纳,证明如果E 中出现n 个运算符,那么E 具有n+1个操作数。
4. 给出一个具有交换性但不具结合性的二元运算符。
5. 给出一个具有结合性但不具交换性的二元运算符。
6. * 考虑运算符全为二元运算符的表达式E。E 的长度是指E 中符号的数目,将一个运算符或左边括号或右边括号记作一个符号,并将任一操作数(比如123或abc)记作一个符号。证明E 的长度肯定为奇数。提示:通过对表达式E 的长度进行完全归纳来证明该声明。
7. 证明:每个负整数都可以写成2a+3b的形式,其中a 和b 都是整数(不一定是正整数)。
8. * 证明:每个整数(正整数或负整数)都可以写为5a+7b的形式,其中a 和b 都是整数(不一定是正整数)。
9. * 弱归纳证明(如2.3节中那些)是否也是完全归纳证明?完全归纳证明是否也是弱归纳证明?
10. * 在本节中我们展示了如何通过最少反例论证来验证完全归纳。这表明了完全归纳也可通过迭代来验证。
真相大揭露
在证明程序正确的过程中,存在很多理论上和实践上的困难。一个很明显的问题是:“程序‘正确’表示什么意思?”正如我们在第1章中提到过的,多数在练习中编写的程序只满足某些非正式的规范,这些规范本身可能是不完整或不一致的。即便是存在确切的正式规范,我们也可以证明,并不存在可以证明任意的程序等同于给定规范的某个算法。
尽管存在这些困难,但陈述并证明与程序有关的断言还是有好处的。程序的循环不变式(loop invariant)通常是人们可以给出的最实用的程序工作原理的简短解释。此外,程序员在编写一段代码时,应该将循环不变式谨记心头。也就是说,程序能正常工作一定是存在某些原因的,而这个原因通常必须与程序每次进行循环或每次执行递归调用时都成立的归纳假设相关。程序员应该能设想出一个证明过程,即使行逐行把证明过程写下来可能并不现实。
2.5 证明程序的属性
在本节中,我们将深入到这样一个领域:证明程序能完成它声称能做的工作。在这个领域中,归纳证明起着举足轻重的作用。我们将看到一项技术,它可以解释迭代程序在进行循环的过程中在做些什么。如果理解循环在做什么,基本上就能明白需要对迭代程序有哪些了解。在2.9节中,我们会介绍证明递归程序的属性需要些什么。
2.5.1 循环不变式
要证明程序中循环的属性,关键是要选择循环不变式(或称归纳断言),也就是每次进入循环中某个特定点时都为真的命题S。然后通过对以某种方式衡量循环次数的参数进行归纳,证明该命题S。例如,该参数可以是我们到达某while循环测试的次数,也可以是for循环中循环下标的值,还可以是某个涉及每次循环时都递增1的程序变量的表达式。
示例 2.12
举个例子,我们考虑一下2.2节中SelectionSort的内层循环。以下这几行代码带着与图2-2中相同的编号:
(2) small = i;
(3) for (j = i+1; j < n; j++)
(4) if (A[j] < A[small])
(5) small = j;
回想一下,这几行代码的目的是使small等于A[i..n-1]中值最小的元素的下标。要证实该声明为何为真,考虑一下如图2-10所示的该循环的流程图。该流程图展示了执行该程序必需的5个步骤。
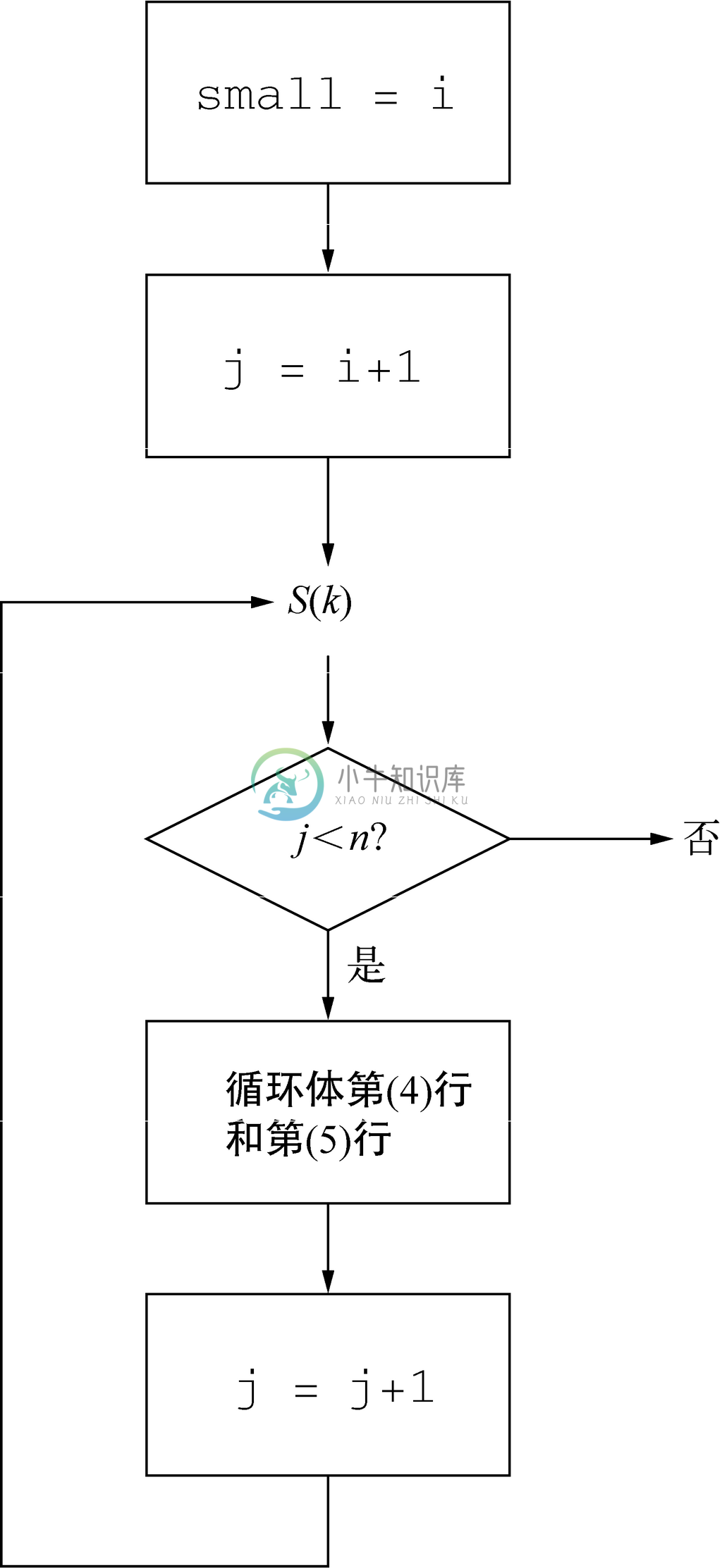
图 2-10 SelectionSort内层循环的流程图
1. 首先,需要将small初始化为i,如同在第(2)行中所做的那样。
2. 在第(3)行的for循环开始的时候,要将j初始化为i+1。
3. 接着,需要测试是否有j<n。
4. 如果是,就执行有第(4)行和第(5)行组成的循环体。
5. 在循环体结束的位置,需要递增j,并返回测试的位置。
在图2-10中看到,在测试之前有一点被标记为循环不变式命题S(k),我们很快就会发现这是个什么样的命题。第一次到达该测试时,j的值为i+1,而small的值为i。第二次到达该测试时,j的值是i+2,因为j已经递增了一次。因为循环体(第4行和第5两行)会在A[i+1]比A[i ]小的条件下将small置为i+1,所以我们看到small总是A[i ]和A[i+1]中较小的那个的下标。5
5为防止出现持平的情况,small应该是i。不过一般情况下我们会假设不会出现持平的情况,并将“最小元素第一次出现”说成“最小的元素”。
类似地,当第三次到达测试时,j的值是i+3,而small则是A[i..i+2]中最小那个的下标。因此我们将试着证明看似一般规则的如下命题。
命题S(k)。在k 为循环下标j的值的情况下,如果到达第(3)行的for声明中对j<n的测试,那么small的值就是A[i..k-1]中最小元素的下标。
请注意,我们在这里使用字母k 来表示变量j在循环进行时可能具有的值。这不像用j来表示j的值那样烦琐,因为有时候需要保持k不变,而同时j的值又在变化。还要注意,S(k)的表述中有“如果到达……”,这是因为某些k 的值比循环下标j的值更小而使循环中断,所以可能根本没法到达循环测试。如果k 是这些值之一,那么S(k)一定为真,因为任何“若A则B”形式的命题在A为假时都为真。
依据。依据情况是k=i+1,其中i为第(3)行中变量i的值。6在循环开始时,有j=i+1。也就是说,我们刚执行完第(2)行,把i赋值给small,并且将j初始化为i+1,以开始该循环。S(i+1)表示,small是A[i..i]中最小元素的下标,也就是说small的值一定是i。从技术上讲,我们还必须证明,除了第一次到达测试时之外,j的值从不可能是i+1。从直观上说,其原因就是每次进行循环时,j都会递增,所以它再也不会有i+1这么小了。(为了精益求精,我们应该在除了第一次通过测试外都有j>i+1的假设下进行归纳证明。)因此,归纳依据S(i+1)被证明为真。
6就行(3)到行(5)的循环而言,i是不会改变的。因此i+1是可用作根据值的合适常数。
归纳。现在假定我们的归纳假设S(k)对某些k≥i+1成立,并证明S(k+1)为真。首先,如果k≥n,那么在j的值为k,或更早之前,循环就中断了,所以肯定不会在j的值等于k+1时到达该循环测试。在这种情况下,S(k+1)一定为真。
因此,我们假设k<n,如此一来,实际上已经进行了j等于k+1时的测试。S(k)说的是small表示A[i..k-1]中最小元素的下标,而S(k+1)则是说small表示A[i..k]中最小元素的下标。如果考虑当j的值为k 时循环体(第4行和第5行)中会发生的事情,就会出现如下两种情况,具体取决于第(4)行的测试是否为真。
1. 如果A[k]不小于A[i..k-1]中的最小值,那么small的值不会改变。不过,在这种情况下,small还要表示A[i..k]中最小元素的下标,因为A[k]不是最小的。因此,在这种情况下S(k+1)表述的结论为真。
2. 如果A[k]小于A[i ]到A[k-1]这些值的最小值,那么就要将small置为k。S(k+1)表述的结论还是成立,因为k 是A[i..k]中最小元素的下标。
因此,不管哪种情况,small都是A[i..k]中最小元素的下标。我们通过递增变量j来进行for循环。因此,在循环测试之前,当j的值为k+1时,S(k+1)表述的结论成立。现在就证明了由S(k)可以得到S(k+1)。我们已经完成了归纳,并得到S(k)对所有k≥i+1的值都为真这样的结论。
接下来,应用S(k)来声明第(3)行到第(5)行的内层循环。当j的值达到n 时,程序会退出循环。因为S(n)表示small是A[i..n-1]中最小元素的下标,所以可以得出一个有关内层循环工作方式的重要结论。我们会在下一个示例中看看如何利用这个结论。
示例 2.13
现在,考虑整个SelectionSort函数,我们在图2-11中重现了其核心部分。表示这段代码的流程图如图2-12所示,其中“循环体”是指图2-11中的第(2)到(8)这几行。归纳断言T(m)还是关于在循环终止的测试开始前什么一定为真的命题。通俗地说,就是当i的值为m 时,我们选中较小的m 个元素,并将它们排序在数组开头的位置。更具体地讲就是,我们要通过对m 的归纳证明以下命题T(m)为真。
(1) for (i = 0; i < n-1; i++) {
(2) small = i;
(3) for (j = i+1; j < n; j++)
(4) if (A[j] < A[small])
(5) small = j;
(6) temp = A[small];
(7) A[small] = A[i];
(8) A[i] = temp;
}
图 2-11 SelectionSort函数的主体

图 2-12 整个选择排序函数的流程图
命题T(m)。如果到达第(1)行中i<n-1的循环测试时变量i的值等于m,那么有:
(a) A[0..m-1]是有序排列的,也就是说,A[0]≤A[1]≤…≤A[m-1]。
(b) A[m..n-1]的所有元素不小于A[0..m-1]中任一元素。
依据。依据情况是m=0。依据为真的原因微不足道。如果考虑命题T(0),那么(a)部分就是说A[0..-1]是已排序的。不过在A[0]、…、A[-1]的范围内没有元素,所以(a)一定为真。类似地,T(0)的(b)部分是说,A[0..n-1]的所有元素都至少与A[0..-1]中任一元素一样大。由于后者描述的范围内没有元素,所以(b)部分也为真。
归纳。在归纳步骤中,假设T(m)对所有的m≥0都为真,并要证明T(m+1)成立。就像在示例2.12中那样,我们又要试着证明形如“若A则B ”的命题,而只要A为假,那么这样的命题肯定为真。因此,如果“到达for循环测试时i等于m+1”这一假设为假,那么T(m+1)就为真。因而可以假设我们确实在i的值为m+1时到达了该测试,也就是说,可以假设m<n-1。
当i的值为m 时,循环体会找出A[m..n-1]中的最小元素(如示例2.12中命题S(m)所证明的)。在第(6)行至第(8)行中,该元素会与A[m]互换。归纳假设T(m)的(b)部分告诉我们,被选中的这个元素不小于A[0..m-1]中任一元素。此外,那些元素还是已排序的,所以现在A[i..m]中所有元素也是已排序的。这也就证明了命题T(m+1)的(a)部分。
要证明T(m+1)的(b)部分,我们看到所选择的A[m]不大于A[m+1..n-1]中的任一元素。T(m)的(a)部分告诉我们,A[0..m-1]已经不大于A[m+1..n-1]中任一元素了。因此,在执行函数的第(2)行到第(8)行并递增i后,可知A[m+1..n-1]中所有元素都不小于A[0..m]中任一元素。由于现在i的值为m+1,我们证明了命题T(m+1)的真实性,所以就证明了该归纳步骤。
现在,令m=n-1。我们知道,当i的值为n-1时,会退出外层循环,所以T(n-1)将会在完成这次循环后成立。T(n-1)的(a)部分表示,A[0..n-2]中所有元素都是已排序的,而其(b)部分则是说A[n-1]不小于其他任何元素。因此,在该程序终止后,A中的元素是以非递减顺序排列的,也就是说,它们是已排序的。
2.5.2 while循环的循环不变式
在讲到形如
while (<condition>)
<body>
的while循环时,通常都可以为循环条件测试前的那一点找出合适的循环不变式。一般来说,我们会试着通过对循环次数的归纳来证明循环不变式成立。然后,当条件为假时,可以利用循环不变式以及条件为假的事实,得出一些关于while循环终止后什么为真的有用信息。
不过,与for循环不同的是,可能不存在为while循环计数的变量。更糟的是,尽管for循环可以保证最多只会迭代到循环的限制(例如,SelectionSort程序的内层循环最多循环n-1次),我们却没理由相信while循环的条件可能会变为假。因此,证明while循环正确性的部分工作就是要证明while循环最终会终止。一般要通过涉及程序中变量的某个表达式E,按照如下方式一起来证明循环的终止。
1. 每进行一次循环,E 的值至少会减少1。
2. 如果E 的值小到某个指定的常数(比如0),循环条件就为假。
示例 2.14
阶乘函数,写作n!,表示的是整数1×2×…×n 的积。例如,1!=1,2!=1×2=2,5!=1×2×3×4×5=120。图2-13所示的简单程序片段就是用来计算n≥1时的n!的。
(1) scanf("%d", &n);
(2) i = 2;
(3) fact = 1;
(4) while (i <= n) {
(5) fact = fact*i;
(6) i++;
}
(7) printf("%d\n", fact);
图 2-13 阶乘程序片段
首先,要证明图2-13中第(4)行至第(6)行的while循环一定会终止。这里我们选择的表达式E 是n-i。请注意,每进行一次while循环,i的值在第(6)行会增加1,而n的值则保持不变。因此,每进行一次循环,E 的值就会减少1。此外,当E 的值为-1或更小时,有n-i≤-1,或者说是i≥n+1。因此,当E 变为负值时,循环条件i≤n 就不再成立,循环就将终止。一开始并不知道E 有多大,因为不知道要读入的n值为多少。不过,不管该值为多少,E 最终都能小到-1,而循环将会终止。
现在必须证明图2-13中的程序能够完成它应该做的工作。合适的循环不变式命题如下,我们要通过对变量i的值的归纳来证明该命题。
命题 S(j )。如果在到达循环测试i≤n 时变量i的值为j,那么变量fact的值就是(j-1)!。
依据。归纳依据是S(2)。只有当从外部进入该循环时,在到达该测试时i的值才为2。在循环开始前,图2-13中的第(2)行和第(3)行会将fact的值置为1,并将i的值置为2。由于1=(2-1)!,所以归纳依据得到证明。
归纳。假设S(j )为真,并证明S(j+1)为真。如果j>n,那么当i的值为j 或更早之时,该while循环就中断了,因此当i的值为j+1时,我们根本无法到达该循环测试。在这种情况下,S(j+1)为平凡真(trivially true),因为它具有“如果我们到达……”这种形式。
因此,假设j≤n,并考虑一下在i的值为j时,执行while循环的循环体会发生什么。通过归纳假设,在第(5)行被执行之前,fact的值为(j-1)!,而i的值为j。因此,在第(5)行执行完之后,fact的值为j×(j-1)!,也就是j !。
在第(6)行,i增加了1,其值就达到了j+1。因此,当i带着值j+1到达该循环测试时,fact的值是j !。命题S(j+1)就是说,当i等于j+1时,fact等于((j+1)-1)!,也就是j !。因此,我们证明了命题S(j+1),并完成了归纳步骤。
之前已经证明了while循环将终止。由此可见,它将在i第一次具有大于n 的值时终止。因为i是整数,而且每进行一次循环就会增加1,所以i在循环终止时的值一定是n+1。因此,当到达第(7)行时,命题S(n+1)一定成立。不过该命题表示fact的值为n!。因此,程序会打印出n!,正如我们想要证明的。
作为一个实际问题,应该指出,图2-13中的阶乘程序在任何计算机上都只能打印出少量几个n 的阶乘值n!作为答案。因为阶乘函数增长得特别快,答案的大小很快就超过了现实中任何一台计算机上整数的最大大小。
2.5.3 习题
1. 以下程序片段会让sum的值等于从1到n 的整数之和,为其找出合适的循环不变式。
scanf("%d",&n);
sum = 0;
for (i = 1; i <= n; i++)
sum = sum + i;
通过对i 的归纳证明找出的循环不变式成立,并利用它证明程序可按照预期工作。
2. 以下程序片段可计算数组A[0..n-1]中各整数之和:
sum = 0;
for (i = 0; i < n; i++)
sum = sum + A[i];
为其找出合适的循环不变式,利用该循环不变式证明程序可按照预期工作。
3. * 考虑如下片段:
scanf("%d", &n);
x = 2;
for (i = 1; i <= n; i++)
x = x * x;
对应i≤n 的测试之前那点的合适循环不变式会满足如下条件:如果我们到达该点时变量i的值为k,那么有x=22k-1。通过对k 的归纳,证明该不变式成立。在循环终止后,x的值是多少?
4. * 图2-14中的程序片段会持续读入整数,直到读到负整数为止,然后会打印出这些整数的和。为循环测试之前的那点找出合适的循环不变式,利用该不变式证明该程序片段可按照预期工作。
sum = 0;
scanf("%d", &x);
while (x >= 0) {
sum = sum + x;
scanf("%d", &x);
}
图 2-14 为一列整数求和,通过负整数来终止循环
5. 考虑图2-13所示程序中的n,找出自己的计算机能处理的n 的最大值。定长整数对证明程序的正确有什么影响?
6. 通过对图2-10中程序循环的次数进行归纳,证明在第一次循环后j>i+1。
2.6 递归定义
在递归定义(或归纳定义)中,我们用一类或多类紧密相关的对象或事实本身来对它们进行定义。这种定义一定不能是无意义的,比如“某个部件是某个有某种颜色的部件”,也不能是似是而非的,比如“当且仅当某事物不是glotz时它才是glotz”。归纳定义涉及:
1. 一条或多条依据规则,在这些规则中,要定义一些简单的对象;
2. 一条或多条归纳规则,利用这些规则,通过集合中较小的对象来定义较大的对象。
示例 2.15
在2.5节中我们通过迭代算法定义了阶乘函数:将1×2×…×n 相乘得到n!。其实,还可以按照以下方式递归地定义n!的值。
依据。1!=1。
归纳。n!=n×(n-1)!。
例如,依据告诉我们1!=1。这样就可以在归纳步骤中使用该事实,得到n=2时
2!=2×1!=2×1=2
对n=3、4和5,有
1!=3×2!=3×2=6
4!=4×3!=4×6=24
5!=5×4!=5×24=120
等等。请注意,虽然术语“阶乘”看起来就是用自身来定义的,但在实践中,可以只通过值较小的n 的阶乘,得到值逐步增大的n 对应的n!的值。因此,我们具备了有意义的“阶乘”定义。
严格地讲,应该证明,n!的递归定义可以得出与原来的定义相同的结果,
n!=1×2×…×n
要证明这一点,就要证明如下命题。
命题S(n)。按照上述方式递归地定义的n!,等于1×2×…×n。
通过对n的归纳来完成证明。
依据。S(1)显然成立。递归定义的依据告诉我们1!=1,而且1×…×1(即“从1到1”这些整数的积)的积显然也等于1。
归纳。假设S(n)成立,也就是说,由递归定义给出的n!等于1×2×…×n。而递归定义告诉我们
(n+1)!=(n+1)×n!
如果应用乘法交换律,就有
(n+1)!=n!×(n+1) (2.11)
由归纳假设可知
n!=1×2×…×n
因此,可以用1×2×…×n替换等式(2.11)中的n!,就可以得到
(n+1)!=1×2×…×n×(n+1)
这也就是命题S(n+1)。这样就证明了归纳假设,并证明了对n!的递归定义与迭代定义是相同的。
图2-15显示了递归定义的一般本质。它在结构上与完全归纳类似,都含有无限的实例序列,每个实例都依赖于之前的任一或所有实例。我们通过应用一个或多个依据规则开始。接下来的一轮归纳,要对已经得到的内容应用一条或多条归纳规则,从而建立新的事实或对象。再接下来的一轮归纳,再次对已经掌握的内容应用归纳规则,获得新的事实或对象,以此类推。
图 2-15 在归纳定义中,要一轮一轮地建立对象,在某一轮建立的对象可能会依赖于之前所有轮次建立的对象
在定义阶乘的示例2.15中,我们从依据情况得到了1!的值,应用一次归纳步骤得到2!,应用两次归纳步骤得到3!,等等。这里的归纳具有“普通”归纳的形式,在每一轮的归纳中,都只用到在前一轮归纳中得到的内容。
示例 2.16
在2.2节中,定义了词典顺序的概念,当时的定义是具有迭代性质的。粗略地讲,通过从左起比较对应符号ci 和di,测试字符串c1…cn是否先于字符串d1…dm,直到找到某个值i 令ci ≠di,或者到达其中一个字符串的结尾。以下的递归定义定义了字符串对w 和x,其中w 在词典顺序上要先于x。从直观上讲,要对两个字符串从开头起相同字符对的数目进行归纳。
依据。该依据涵盖了那些我们能立即分出字符顺序先后的字符串对。依据包含如下两个部分。
1. 对任何不为ε 的字符串w,都有ε<w。回想一下,ε 表示空字符串,也就是不含字符的字符串。
2. 如果c<d,其中c 和d 都是字符,那么对任何字符串w 和x,都有cw<dx。
归纳。如果字符串w 和x具有w<x 的关系,那么对任意字符c,都有cw<cx。
例如,可以使用以上定义表明base<batter。根据依据的规则(2),有c=s,d=t,w=e,x=tter,因此有se<tter。如果应用递归规则一次,有c=a,w=e,以及x=tter。最后,第二次应用递归规则,有c=b,w=ase,以及x=atter。也就是说,依据和归纳步骤是如下这样的:
se < tter
ase < atter
base < batter
还可以按照以下方式证明bat<tter。依据的部分(1)告诉我们,ε<ter。如果应用递归规则3次,其中c依次等于t、a和b,就可以进行如下推理:
ε < ter t < tter at < atter bat < batter
现在应该对两个字符串从左端起相同的字符数进行归纳,证明当且仅当字符串按照刚给出的递归定义排在前面之时,才能按照2.2节中的定义得出它也排在前面的结论。我们还留了两个归纳证明的习题。
在示例2.16中,如图2-15所示的事实组是很大的。依据情况给出了所有w<x 的事实,不管是w=ε,还是w 和x 以不同字符开头。使用归纳步骤一次,就给出当w 和x 只有第一个字母相同时,所有w<x 的情况;第二次使用,就给出了那些当w 和x 只有前两个字母相同时的所有情况,以此类推。
2.6.1 表达式
各种算术表达式是递归定义的,我们为这种定义的依据指定了原子操作数可以是什么。例如,在C语言中,原子操作数既可以是变量,也可以是常量。然后,归纳过程告诉我们可应用哪些运算符,以及每个运算符可以应用到多少个操作数上。例如,在C语言中,运算符<可以应用到两个操作数上,运算符符号-可以应用于一至两个操作数,而由一对圆括号加上括号内必要数量的逗号表示的函数应用运算符,则可以应用于一个或多个操作数,比如f(a1,…,an) 。
示例 2.17
通常将如下的表达式称作“算术表达式”。
依据。以下类型的原子操作数是算术表达式:
1. 变量;
2. 整数;
3. 实数。
归纳。如果E1和E2是算术表达式,那么以下表达式也是算术表达式:
1. (E1+E2)
2. (E1-E2)
3. (E1×E2)
4. (E1/E2)
运算符+、-、×和/都是二元运算符,因为它们都接受两个参数。它们也叫作中缀(插入)运算符(infix operator),因为它们出现在两个参数之间。
此外,我们允许减号在表示减法之外,还可以表示否定(符号改变)。这种可能性反映在了第5条,也是最后一条递归规则中:
5. 如果E 是算术表达式,那么 (-E )也是。
像规则(5)中的-这样只接受一个操作数的运算符,称为一元运算符。它也称为前缀运算符,因为它出现在参数之前。
图2-16展示了一些算术表达式,并解释了为什么它们都是表达式。请注意,有时候括号是不必要的,可以忽略。比如图2-16中最后的表达式(vi),外层括号和表达式-(x+10)两侧的括号都是可以忽略的,而我们可以将其写为y-(x+10)。然而,剩下的括号是必不可少的,因为y×-x+10按照约定会被解释为(y×-x)+10,这就不是与y×-(x+10)等价的表达式了(例如,试试y=1和x=1)。7
7如果运算符约定俗成的优先级(一元的减号优先级最高,接着是乘号和除号,再接着是加号和减号),以及“左结合性”的传统约定(即优先级相同的运算符——比如一串加号和减号——从左边开始结合)已经暗示了括号的存在,那么括号就是多余的。不管是C语言还是普通的算术,都遵守这些约定。
(i) x 依据规则(1)
(ii) 10 依据规则(2)
(iii) (x+10) 对(i)和(ii)应用递归规则(1)
(iv) (-(x+10)) 对(iii)应用递归规则(5)
(v) y 依据规则(1)
(vi) (y×(-(x+10))) 对(v)和(iv)应用递归规则(5)
图 2-16 一些算术表达式示例
更多运算符术语
出现在其参数之后的一元运算符,比如表达式n!中的阶乘运算符!,称为后缀运算符。如果接受多个操作数的运算符重复地出现在其所有参数之前或之后,那么它们也可以是前缀或后缀运算符。在C语言或普通算术中没有这类运算符的例子,不过我们在5.4节中将要讨论一些所有运算符都是前缀或后缀运算符的表示法。
接受3个参数的运算符就是三元运算符。举例来说,在C语言中,表示“若c 则x,否则y ”的表达式
c?x:y中,运算符?:就是三元运算符。如果运算符接受k 个参数,就称其是k 元的。
2.6.2 平衡圆括号
可以出现在表达式中的圆括号串称为平衡圆括号。例如,在图2-16的表达式(vi)中出现的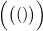 模式,以及如下表达式
模式,以及如下表达式
((a+b)×((c+d)-e))
具有的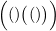 模式。空字符串ε 也是平衡圆括号串,例如,它的模式是表达式x。一般来说,判定圆括号串平衡的条件是,每个左圆括号都能与其右侧的某个右圆括号配对。因此,“平衡圆括号串”的一般定义由以下两个规则组成:
模式。空字符串ε 也是平衡圆括号串,例如,它的模式是表达式x。一般来说,判定圆括号串平衡的条件是,每个左圆括号都能与其右侧的某个右圆括号配对。因此,“平衡圆括号串”的一般定义由以下两个规则组成:
1. 平衡圆括号串中左圆括号和右圆括号的数量相等;
2. 在沿着括号串从左向右行进的过程中,该串的量变从不为负值,其中量变(profile)是对行进过程中已达到左括号数目减去已到达右括号数目的累计值。
请注意,统计值必须从0开始,以0结束。例如,图2-17a表示的是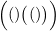 的量变,而图2-17b表示的是
的量变,而图2-17b表示的是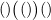 的量变。
的量变。
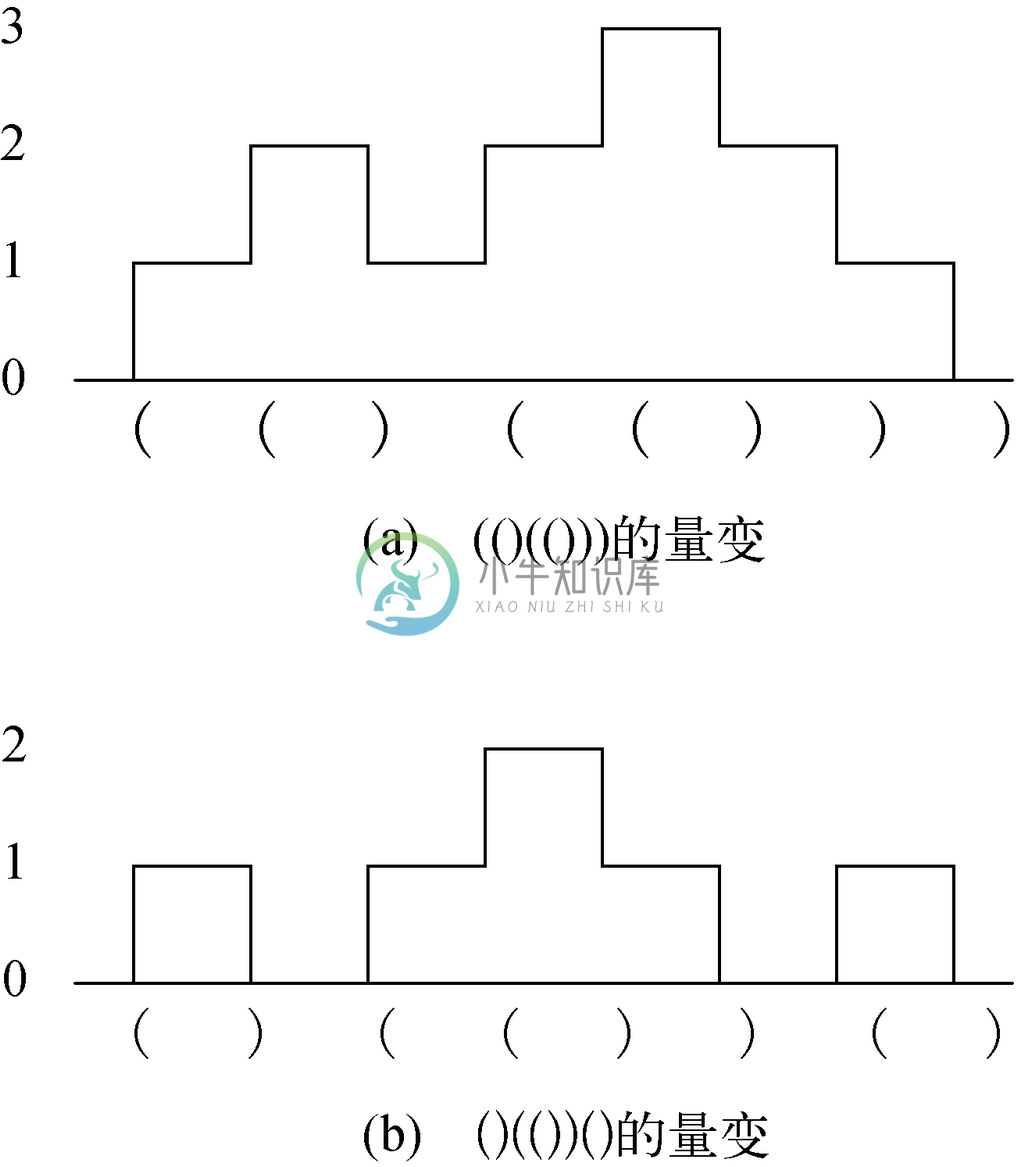
图 2-17 两个括号串的量变
“平衡圆括号”的概念有着多种递归定义。下面的定义比较巧妙,不过我们将证明,该定义相当于之前提到的涉及统计值的非递归定义。
依据。空字符串是平衡圆括号串。
归纳。如果x 和y 是平衡圆括号串,那么(x )y 也是平衡圆括号串。
示例 2.18
由依据可知,ε 是平衡圆括号串。如果应用递归规则,其中x 和y 都等于ε,就可以得出()是平衡的。请注意,在将空字符串提交给变量(如x 或y)时,该变量就“消失”了。然后可以按以下方法应用递归规则。
1. x=()且y=ε,得出(())是平衡的。
2. x=ε且y=(),得出()()是平衡的。
3. x=y=(),得出(())()是平衡的。
最后,因为已知(())和()()是平衡的,所以可以令递归规则中的x和y为这两者,就证明了((()))()()是平衡的。
可以证明两种“平衡”定义指定的是同一组括号串。为了让表述更清楚,我们将根据递归定义定义的平衡括号串直接称为平衡括号串,而将根据非递归定义定义的平衡括号串称为量变平衡括号串。量变平衡括号串就是那些量变最终为0而且从不为负值的括号串。需要证明以下两点。
1. 每个平衡括号串都是量变平衡的。
2. 每个量变平衡括号串都是平衡的。
这就是下面两个示例中归纳证明的目标。
示例 2.19
首先,我们来证明(1)部分,也就是每个平衡括号串都是量变平衡的。这段证明复制了定义平衡括号串所使用的完全归纳。也就是说,我们要证明如下命题。
命题 S(n)。如果括号串w 是通过n 次应用递归规则被定义为平衡的,w 就是量变平衡的。
依据。依据为n=0。不需要通过应用任何递归规则便可证明其平衡的括号串就是ε,它的平衡是由依据规则得出的。由此可见,空字符串的量变最终为0,而且从不为负值,所以ε 是量变平衡的。
归纳。假设S(i )对i=0,1,…,n为真,并考虑S(n+1)的实例,也就是说证明w 为平衡括号串需要n+1次使用递归规则。考虑最后那次递归规则的使用,就是拿两个已知为平衡的括号串x 和y,组成形为(x )y 的w。我们使用了n+1次递归规则来形成w,而且最后一次利用递归规则既不是用来形成x,也不是用来形成y。因此,形成x 和y 都不需要利用递归规则n次以上。所以,归纳假设可以应用于x 和y,而且可以得出x 和y 都是量变平衡的。
w 的量变如图2-18所示。它首先会上升一级,作为对第一个左圆括号的回应。接着是x 的量变,由虚线所示,w 的量变在这里会再上升一级。我们使用归纳假设得出x 是量变平衡的,因此,它的量变始于第0级且终于第0级,而且从不为负。如图2-18所示,由于w 的量变中x 的部分已经上升了一级,该部分从第1级开始,在第1级结束,而且从来不低于第1级。
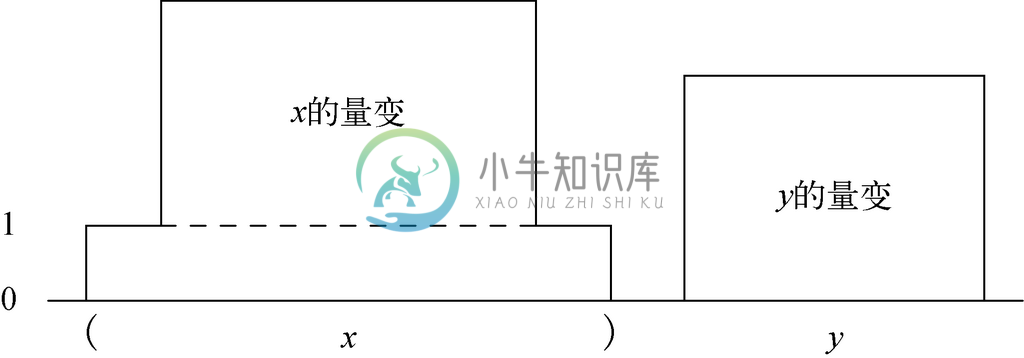
图 2-18 构造w=(x )y 的量变
显式出现在x 和y 之间的右圆括号将w 的量变降为0。接着就到了y 的量变。根据归纳假设,y 是量变平衡的,因此在w 的量变中,y 的部分不会低于0,而且它让w 的量变最终归于0。
我们现在已经构造了w 的量变,并发现它满足量变平衡括号串的条件。也就是说,w 的量变从0开始,以0结束,并且从不为负值。这样就证明了,如果括号串是平衡的,那么它就是量变平衡的。
现在介绍“平衡圆括号”两种定义等价性的第二个方向。在示例2.20中,将要证明量变平衡的括号串是平衡的。
对递归定义的证明
请注意,在示例2.19中,通过对递归规则(用来证实某对象在定义的类中)的使用次数进行归纳,证明了与一类递归定义的对象(平衡圆括号串)有关的断言。这是处理递归定义概念的一种常见方法,其实也是递归定义很实用的原因之一。在示例2.15中,通过对n 的归纳,证明了递归定义的阶乘值的属性(即n!就是1到n 这n 个整数的积)。而在对n!的定义中,使用了n-1次递归规则,所以该证明过程也可视作对递归规则应用次数进行归纳。
示例 2.20
现在来证明(2)部分,通过对圆括号串的长度进行完全归纳,由“量变平衡”得出“平衡”。正式的命题如下。
命题 S(n)。如果长度为n 的圆括号串w 是量变平衡的,那么它也是平衡的。
依据。如果n=0,那么该括号串一定是ε。由递归定义的依据可知ε 是平衡的。
归纳。假设长度小于等于n 的量变平衡括号串是平衡的。必须证明S(n+1)为真,也就是要证明长度为n+1的量变平衡括号串也是平衡的。8考虑这样一个括号串w:因为w 是量变平衡的,它不可能以右圆括号开头,否则它的量变会立刻变为负值。因此,w 是以左圆括号开始的。
8请注意,所有的量变平衡括号串都刚好是偶长度的,所以,如果n+1为奇数,就不作说明了。不过,在证明中不需要n为偶数。
将w 分为两部分。第一部分从w 的开头开始,到w 的量变第一次变为0截止。第二部分就是w 中其余的部分。例如,图2-17a所示的量变第一次变为0是在其末尾处,所以如果w=(()(())),那么第一部分就是整个括号串,而第二部分就是ε。在图2-17b中,w=()(())(),那么第一部分就是(),而第二部分是(())()。
第一部分永远不可能以左圆括号结尾,因为如果那样,那么在结尾之前的那个位置,量变就为负值了。因此,第一部分以左圆括号开始,并以右圆括号结尾。这样就可以将w 写为(x )y 的形式,其中(x )是第一部分,而y 是第二部分。x 和y 都要比w 短,所以如果可以证明它们是量变平衡的,就可以利用归纳假设推出它们是平衡的。然后可以使用“括号串平衡”定义中的递归规则来证明w=(x )y 是平衡的。
很容易看出,y 是量变平衡的。图2-18还说明了w、x 和y 的量变之间的关系。也就是说,y 的量变是w 的量变的尾部,开始和结束的高度都是0。因为w 是量变平衡的,所以可以得出结论:y 也是量变平衡的。证明x 是量变平衡括号串的过程也几近相同。x 的量变是w 的量变的一部分,它的起止高度都是第1级,而且x 的量变也从未低于第1级。可以知道w 的量变在x 这一段从未到过0,因为我们选取(x )作为w 的最短前缀,而在它结尾处w 的量变才回到0。这样,w 内的x 的量变从未到过0,所以x 本身的量变从未变为负值。
现在已经证明了x 和y 都是量变平衡的。因为它们都比w 短,所以归纳假设适用于它们,它们都是平衡的。定义“括号串平衡”的递归规则告诉我们,如果x 和y 都是平衡的,那么(x )y 也是平衡的。而w=(x )y,所以w 也是平衡的。我们现在完成了归纳步骤,并证明了命题S(n )对所有的n≥0都成立。
2.6.3 习题
1. * 证明:示例2.16中给出的词典顺序的定义和2.2节中给出的定义是相同的。提示:证明由两部分组成,每个部分都要通过归纳法进行证明。对第一个部分,假设根据示例2.16的定义有w<x。通过对i 的归纳证明如下命题S(i )为真:“如果证明w<x 需要应用i 次递归规则,那么根据2.2节中‘词典顺序’的定义有,w 先于x。”依据情况为i=0。该习题的第二部分是要证明,如果根据2.2节中词典顺序的定义有,w 先于x,那么根据示例2.16中的定义有,w<x,这里要对w 和x 从开头起不间断的相同字母数进行归纳。
2. 画出以下圆括号串的量变曲线。
(a) (()(())
(b) ()())(()
(c) ((()())()())
(d) (()(()(())))
哪些是量变平衡的?对那些量变平衡的圆括号串,使用2.6节中的递归定义证明它们是平衡的。
3. * 证明:每个平衡圆括号串(按照2.6节中的递归定义)都是某个算术表达式中的圆括号串(见介绍算术表达式定义的示例2.17)。提示:对“平衡圆括号”定义中的递归规则在构建某给定平衡圆括号串的过程中被使用的次数进行归纳,以证明该命题。
4. 说出以下C语言运算符是前缀、后缀还是中缀运算符,以及它们是一元、二元还是k 元(k>2)运算符。
(a) <
(b) &
(c) %
5. 如果熟悉UNIX的文件系统或类似的系统,请对可能的目录/文件结构给出递归定义。
6. * 某整数集合S 可通过以下规则递归地定义。
依据。0在S 中。
归纳。如果i在S 中,那么i+5和i+7也在S 中。
(a) 不在S 中的最大整数是多少?
(b) 设j 是(a)小题的答案。证明:不小于j+7的整数都在S中。提示:要注意到这一题与2.4节习题中第8小题的相似性(虽然在这里我们只处理非负整数)。
7. * 通过对位串长度的归纳,递归地定义偶校验位串集合。提示:最好同时定义偶校验位串和奇校验位串这两个概念。
8. * 可以按照以下规则定义已排序整数表。
依据。由一个整数组成的表是已排序的。
归纳。如果已排序表L的最后一个元素是a,而且b≥a,那么L 后加上b 也是已排序表。
证明:如上所述的对“已排序表”的递归定义与之前对已排序表的非递归定义(即由整数a1≤a2≤…≤an组成的表是已排序表)是等价的。
请记住,这里需要证明(a)、(b)两个部分。(a)如果由递归定义得出表是已排序的,那么根据非递归定义它也是已排序的;(b)如果表由非递归定义可知是已排序的,那么根据递归定义它也是已排序的。(a)部分可以对递归规则的使用次数进行归纳,而(b)部分则可以对表的长度进行归纳。
9. ** 如图2-15所示,每当我们给出递归定义,就可以按照生成对象的“轮次”(也就是为得到对象而应用归纳步骤的次数)为已定义的对象分类。在示例2.15和示例2.16中,描述每一轮生成的结果是相当简单的。有时这项工作却更具挑战性。请问该如何刻画以下两种情况中第n轮生成的对象?
(a) 如示例2.17中描述的算术表达式。提示:如果熟悉第5章要介绍的树,可以考虑表达式的树表示。
(b) 平衡圆括号串。请注意,示例2.19中所描述的“递归规则应用次数”与找出圆括号串的轮次是不同的。例如,(())()使用了3次递归规则,但是在第二轮被找出的。
2.7 递归函数
递归函数是那些在自己的函数体中被调用的函数。这种调用通常是直接的,例如,函数F在它自己中包含对F的调用。不过,有时候这种调用也会是间接的,比如,某函数F1直接调用函数F2,F2又直接调用F3,等等,直到该调用链中的函数Fk调用F1。
人们通常有这样一种看法,就是学习迭代编程,或者说使用非递归的函数调用,要比学习递归编程更容易。诚然,我们不能完全否定这种观点,但我们相信,只要大家有机会对递归编程加以练习,那么它其实也是很简单的。递归程序往往比等效的的迭代程序更简洁且更易于理解。更重要的是,比起迭代程序,某些问题更容易被递归程序击破。9
9这样的问题往往涉及某种查找。例如,在第5章中我们会看到一些查找树的递归算法,这些算法没有方便的迭代模拟(虽然也存在使用栈的等价迭代算法)。
说几句实在话
使用递归存在潜在的缺点,即在某些计算机上对函数的调用会非常费时,因而与解决同样问题的迭代程序相比,递归程序可能会耗时更多。不过,在很多现代化的计算机上,函数调用是非常高效的,所以反对使用递归程序的这一理由已变得不那么重要。
即便是在函数调用机制较慢的计算机上,人们也可以对程序进行剖析,看看程序的各个部分分别花了多少时间。然后就可以重新编写程序中占用大部分运行时间的部分,如有必要就用迭代替代递归。这样一来,除了速度是最关键因素的一小部分代码之外,程序的大半部分都能利用递归。
通常可以通过模仿待实现程序的规范中的递归定义,来设计递归算法。实现递归定义的递归函数将含有一个依据部分与一个归案部分。依据部分一般会检查可由定义的依据解决的简单输入(不需要递归调用)。函数的归纳部分则需要一次或多次对其本身进行递归调用,并实现定义的归纳部分。下面的例子应该能说明这几点。
示例 2.21
图2-19给出了计算某个非负整数n 的阶乘值n!的递归函数。该函数直接转换了示例2.15中对n!的递归定义。也就是说,图2-19的第(1)行依据情况与归纳情况进行了区分。我们假设n≥1,所以第(1)行的测试其实就是在问是否有n=1。如果是,我们就在第(2)行应用依据规则,得到1!=1。如果n>1,就在第(3)行应用归纳规则n!=n×(n-1)!。
int fact(int n)
{
(1) if (n <= 1)
(2) return 1; /* 依据 */
else
(3) return n*fact(n-1); /* 归纳 */
}
图 2-19 计算n≥1时n!的递归函数
例如,如果我们调用fact(4),结果就会调用fact(3),然后调用fact(2),再调用fact(1)。至此,fact(1)会应用依据规则,因为这里有n≤1,并为fact(2)返回值1。这次对fact的调用在第(3)行完成,返回2给fact(3)。接着,fact(3)返回6给fact(4),而fact(4)最后会在第(3)行返回24作为答案。图2-20表示了这些调用和返回的模式。
调用 ↓ ↑ 返回 24
fact(4) fact(4)
调用 ↓ ↑ 返回 6
fact(3) fact(3)
调用 ↓ ↑ 返回 2
fact(2) fact(2)
调用 ↓ ↑ 返回 1
fact(1)
图 2-20 调用fact(4)所带来的调用和返回
防御性程序设计
图2-19中的程序说明了很重要的一点,即编写递归程序时要注意不让它们陷入无限的调用。我们可能暗自假设不会以小于1的参数来调用
fact。当然,最好的做法是在调用fact之前测试是否有n≥1,如果n不满足这个条件就打印错误消息并返回某个特定的值(比如0)。不过,即便我们坚信不会以小于1的n来调用fact,也还是要明智一些,在依据情况中包含所有的“错误情况”。这样一来,以错误的输入调用函数fact会直接返回值1,虽然这是不对的,但不至于造成程序出错(其实,对n=0来说,结果为1也是对的,因为0的阶乘等于1)。然而,假如忽略掉错误情况,并将图2-19的第(1)行写成
if(n == 1)那么如果调用了
fact(0),它就会被看作递归情况的实例,并会接着调用fact(-1)、fact(-2),等等,直到计算机用尽记录递归调用的空间才会出错终止。
我们可以像绘制归纳证明和归纳定义的图那样绘出递归图。在图2-21中,假设存在递归函数的参数“大小”这样一个概念。例如,对示例2.21中的fact函数而言,参数n 的值就具有合适的大小。我们将在2.9节中介绍更多与这种大小有关的内容。不过,在这里要注意的是,递归调用只会调用大小更小的参数。还有,在到达某特定大小时(比如在图2-21中就是大小为0),就必须达到依据情况,也就是必须终止递归。
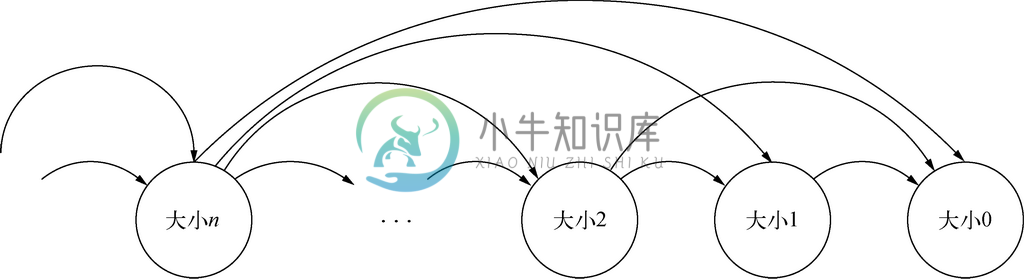
图 2-21 递归函数只调用具有更小的参数的本身
在fact函数的例子中,调用过程不像图2-21所示那样具有一般性。调用fact(n)会导致对fact(n-1)的直接调用,但fact(n)不会直接调用其他具有更小参数的fact。
示例 2.22
如果将底层算法表示为如下形式,就可以将图2-2中的SelectionSort函数变成递归函数recSS。此处假设要排序的数据是在数组A[0..n-1]中。
1. 从数组A的尾部,也就是从A[i..n-1]中,选出最小的元素。
2. 将步骤(1)中选出的元素与A[i]互换。
3. 将剩下的数组A[i+1..n-1]进行排序。
我们可用如下递归算法表示选择排序。
依据。如果i=n-1,那么数组中只有一个元素需要排序。因为任意一个元素都是已排序的,所以我们什么都不用做。
归纳。如果i<n-1,那么要找出A[i..n-1]中最小的元素,将其与A[i]互换,并递归地将A[i+1..n-1]进行排序。
整个算法是从i=0开始执行以上递归的。
如果将i 视作上述归纳中的归纳参数,那么它就是逆向归纳(backward induction)的例子。我们从参数最大的依据开始,通过归纳规则,用较大参数的实例去解决较小参数的实例,这是种特别好的归纳风格,虽然我们之前并未提及它的可能性。不过,还可以将上述归纳视为普通的,或是说“正向”归纳,只要将数组尾部待排序元素的数目k=n-i 作为归纳参数即可。
在图2-22中,我们看到了recSS(A,i,n)程序。其第二个参数i是数组A未排序部分第一个元素的下标,第三个参数n是数组A中待排序元素的总数。不难看出,n是小于等于数组A的最大大小的。因此,调用recSS(A,0,n)会为整个数组A[0..n-1]排序。
void recSS(int A[], int i, int n)
{
int j, small, temp;
(1) if (i < n-1) {/* 依据是i = n-1,在这种情况下,
该函数会返回而不改变 */
/* 归纳如下 */
(2) small = i;
(3) for (j = i+1; j < n; j++)
(4) if (A[j] < A[small])
(5) small = j;
(6) temp = A[small];
(7) A[small] = A[i];
(8) A[i] = temp;
(9) recSS(A, i+1, n);
}
}
图 2-22 递归的选择排序
就图2-21而言,s=n-i对recSS函数的参数来说是合适的“大小”概念。依据情况是s=1,也就是为一个元素排序,不需要发生递归调用。归纳步骤就讲述了如何通过选出最小元素并排序剩下的s-1个元素来为s 个元素排序。
在第(1)行,我们会测试依据情况,就是只有一个元素需要排序的情况(这里我们再次进行了防御性编程,这样一来,就算在调用时有i ≥n,也不会造成无限的调用)。在该依据情况中,我们无事可做,所以直接返回。
函数其余部分是归纳情况。第(2)至(8)行直接照搬了递归选择排序程序中的内容。就像那个程序那样,这几行会将数组A[i..n-1]最小元素的下标赋值给small,并将该元素与A[i]互换。最后,第(9)行是递归调用,会排序数组其余部分。
习题
1. 我们可以按下以下方式递归地定义 n2。
依据。对n=1,有12=1
归纳。如果n2=m,那么(n+1)2=m+2n+1。
(a) 编写C语言递归函数实现该递归。
(b) 通过对n 的归纳证明该定义能正确地计算n2。
2. 假设有数组A[0..4],其中有按所述顺序排列的元素10、13、4、7、11。在每次调用图2-22所示的递归函数recSS之前,数组A的内容是怎样的?
3. 假设如1.3节所述,使用1.6节给出的DefCell(int,CELL,LIST)宏来定义整数链表的节点。回想一下,该宏会扩展为如下类型定义:
typedef struct CELL *LIST;
struct CELL {
int element;
LIST next;
};
编写递归函数find,接受LIST类型的参数,并在某个链表节点含有整数1698作为其元素时返回TRUE,如果没有则返回FALSE。
4. 编写递归函数add,像习题(3)那样接受LIST类型的参数,并返回表中各元素之和。
5. 使用习题3中提到的节点,编写接受整数链表作为参数的递归选择排序函数。
6. 我们在习题8中提出,可以将选择排序一般化,以使用任意的key和lt函数来比较元素。重新编写递归的选择排序算法以融入这种一般性。
7. * 给出递归算法,接受整数i,并生成i 的二进制表示形式(由0和1组成的序列),其中低位排在前。
8. * 两个整数i 和j 的最大公约数(greatest common divisor,GCD)是指能整除i 和j 的最大整数。例如,gcd(24,30)=6,而gcd(24,35)=1。编写递归函数,接受两个整数i 和j,其中i>j,并返回gcd(i,j )。
提示:大家可以使用如下所述的gcd 的递归定义,它假设i>j。
依据。如果j 能整除i,则j 是i 和j 的最大公约数。
归纳。如果j 不能整除i,设k 是i 除以j 得到的余数。那么gcd(i ,j )就和gcd(j ,k )是相同的。
9. ** 证明:习题8中给出的最大公约数递归定义和它的非递归定义(整除i 和j 的最大整数)能得出相同结果。
10. 通常,递归定义可以相当直接地转化为算法。例如,考虑一下示例2.16中给出的字符串“小于”关系的递归定义。编写递归函数,测试两个给定字符串中的第一个字符串是否“小于”另一个字符串。假设字符串是用字符链表表示的。
11. * 根据2.6节的习题8中给出的已排序表的递归定义,创建一种递归排序算法。该算法与示例2.22中的递归选择排序相比如何?
分治法
有一种攻克问题的方式,是将问题分解成多个子问题,然后解决这些子问题,并将它们的解决方案结合成整个问题的解决方案。术语分治法就是用来描述这种问题解决技术的。如果这些子问题和原问题相似,那么我们也许能使用相同的函数递归地解决这些子问题。
要让这种技术起作用,有两点要求。首先是子问题必须比原问题简单。其次是在有限次细分之后,必须得到能立即解决的子问题。如果达不到这些条件,递归算法就会一直细分问题,而找不出解决方案。
我们注意到图2-22中的递归函数
recSS就满足这两个条件。每当调用该函数,就是对少一个元素的子数列调用该函数,而在对只含一个元素的子数列调用它时,它就会返回而不再继续调用自己。类似地,图2-19中的阶乘程序会在每次调用时调用较小整数,而递归过程会在调用参数到达1时停止。2.8节讨论了分治法更为强大的应用——“归并排序”。在这种排序中,待排序数组的大小减小得非常迅速,因为归并排序在每次递归调用时会将数组大小砍掉一半,而不是减去1。
2.8 归并排序:递归的排序算法
现在要考虑一种名为归并排序的与选择排序有着天壤之别的排序算法。递归的方式能最好地描述归并排序,而归并排序展示了分治法的强大,在这种排序方法中,我们通过将问题“分为”大小减半的两个相似问题来为表(a1,a2,…,an)排序。从原则上讲,可以首先将原表分为两个元素任选的大小相等的表,不过在我们开发的程序中,将会将其分为一个含有奇数编号元素的表(a1,a3,a5,…),以及一个含有偶数编号元素的表(a2,a4,a6,…)。10接着单独为大小减半的两个表排序。要完成原表中n个元素的排序,要使用示例2.23中描述的算法来合并两个大小减半的表。
10请记住,“奇数编号”和“偶数编号”指的是元素在表中的位置,而非这些元素的值。
在第3章中,我们将看到,随着待排序表长度n的增加,归并排序所需时间的增长速度要远慢于选择排序所需时间的增长速度。因此,即便递归调用会额外耗费些时间,当n 很大时,还是应该优先使用归并排序而不是选择排序。在第3章中我们将分析这两种排序算法的相对性能。
2.8.1 合并
“合并”是指用两个已排序表生成一个只包含这两个表中所有元素的已排序表。例如,假设有表(1,2,7,7,9)和(2,4,7,8),合并后的表就是(1,2,2,4,7,7,7,8,9)。请注意,对未排序的表谈“合并”是没有意义的。
有一种合并两个表的简单方式,就是从表开头开始分析它们。在每一步中,我们找出两个表当前开头位置的两个元素中较小的那个,选择该元素作为合并后的表的下一个元素,并将该元素从它原来所在的表中删除,使该表具有一个新的“首位”元素。虽然我们在两个表开头的元素相同时会选取第一个表开头的元素,但是持平关系的打破是具有任意性的。
示例 2.23
考虑合并以下两个表。
L1=(1,2,7,7,9)和L2=(2,4,7,8)
两个表的第一个元素分别为1和2。因为1比较小,所以将其选作合并后的表M 的第一个元素,并将1从L1中删除,因此新的L1就是(2,7,7,9)。现在,L1和L2的第一个元素都是2。可以任选其一。假设采取持平情况下总是从L1中选取元素的策略,那么合并后的表M 就变为(1,2),表L1变为(7,7,9),而L2仍为(2,4,7,8)。图2-23所示的表格展示了直到L1和L2双双耗尽的整个合并步骤。
L1 | L2 | M |
|---|---|---|
1,2,7,7,9 | 2,4,7,8 | 空 |
2,7,7,9 | 2,4,7,8 | 1 |
7,7,9 | 2,4,7,8 | 1,2 |
7,7,9 | 4,7,8 | 1,2,2 |
7,7,9 | 7,8 | 1,2,2,4 |
7,9 | 7,8 | 1,2,2,4,7 |
9 | 7,8 | 1,2,2,4,7,7 |
9 | 8 | 1,2,2,4,7,7,7 |
9 | 空 | 1,2,2,4,7,7,7,8 |
空 | 空 | 1,2,2,4,7,7,7,8,9 |
图 2-23 合并的例子
我们将会发现,如果把表表示为1.3节所介绍的链表,设计归并算法的工作会更简单。链表将会在第6章中得到更为详细的介绍。接着,要假设表的元素都为整数。因此,每个元素都能表示为一个“单元”,或者说是struct CELL类型的结构体,而表则表示为指向CELL的LIST类型的指针。这些定义都是由我们在1.6节中讨论过的DefCell(int, CELL, LIST)宏来定义的。这种对DefCell宏的使用会扩展为:
typedef struct CELL *LIST;
struct CELL {
int element;
LIST next;
};
每个单元的element字段都含有一个整数,而next字段则含有指向表中下一单元的指针。如果当前的元素是表中最后一个元素,next字段就含有表示空指针的值NULL。然后整列整数就会用指向表第一个单元的指针(即一个LIST类型的变量)来表示。而空表会用值为NULL的变量(而不是指向第一个元素的指针)来表示。
图2-24是归并算法的C语言实现。merge函数接受两个表作为参数,并返回合并后的表。也就是说,形式参数list1和list2是指向两个给定表的指针,而返回值是指向合并后的表的指针。递归算法可描述为如下形式。
LIST merge(LIST list1, LIST list2)
{
(1) if (list1 == NULL) return list2;
(2) else if (list2 == NULL) return list1;
(3) else if (list1->element <= list2->element) {
/* 在这里,两个表都不为空,
而且第一个表的首个元素更小。
得到的结果就是第一个表的第一个元素,
后面跟上其余元素的合并。*/
(4) list1->next = merge(list1->next, list2);
(5) return list1;
}
else { /* list2 的首个元素更小 */
(6) list2->next = merge(list1, list2->next);
(7) return list2;
}
}
图 2-24 递归的合并
依据。如果任一表为空,那么另一个表就是所需的结果。这条规则是通过图2-24中的第(1)行和第(2)行实现的。请注意,如果两个表都为空,就将返回list2。不过这是正确的,因为这里list2的值是NULL,而两个空表的结合还是空表。
归纳。如果两个表都不为空,那么每个表都有第一个元素。我们可以将两个表的第一个元素分别称为list1->element和list2->element,即分别由list1和list2指向的单元的element字段。图2-25展示了这种数据结构。返回的表从含有最小元素的单元开始。该返回表其余的部分由两个表中除这个最小元素之外的所有元素组成。
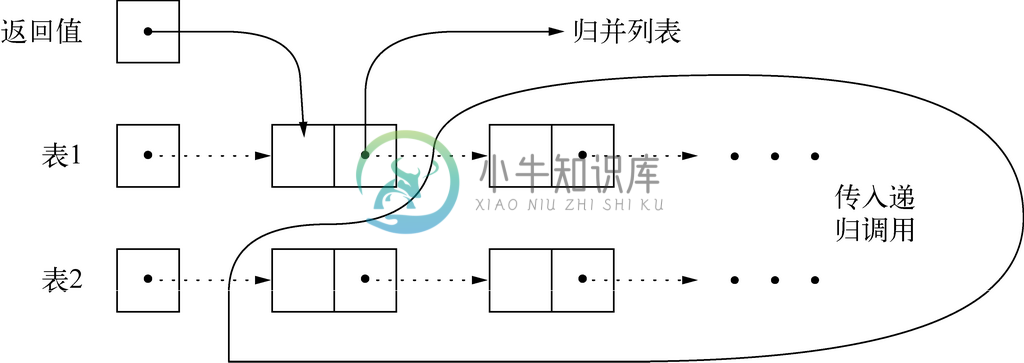
图 2-25 归并算法的归纳步骤
例如,第(4)行和第(5)行处理的是最小元素为表1中第一个元素的情况。第(4)行是对merge函数的递归调用。该调用的第一个参数是list1->next,也就是指向表1中第二个元素的指针(如果表1只有一个元素则为NULL)。因此,传入该递归调用的是由表1中除第一个元素之外的所有元素组成的表。第二个参数是整个表2。因此,第(4)行中对merge函数的递归调用会返回一个指针,指向合并后的表中其余所有元素,并将该指向合并后的表的指针存储在表1第一个单元的next字段中。在第(5)行,我们会返回指向上述单元的指针,该单元现在已经是合并后的表所有元素中的第一个单元。
图2-25展示了这种变化。虚线表示的箭头会在merge被调用时出现。特别要说的是,merge的返回值是指向最小元素所在单元的指针,而且该元素的next字段是指向第(4)行对merge的递归调用所返回的表。
最后,第(6)行和第(7)行会处理最小元素在表2中的情况。该算法的行为与第(4)行和第(5)行中的行为是一样的,只不过两个表的角色互换了而已。
示例 2.24
假设我们对示例2.23中的表(1,2,7,7,9)和(2,4,7,8)调用merge。图2-26展示了进行合并所产生的调用序列,是按照第一列中由上向下的顺序进行调用的。在图中我们省去了分隔表元素的逗号,不过在分隔进行合并的参数时要用到逗号。
调用 | 返回 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
图 2-26 对merge函数的递归调用
例如,因为表1的第一个元素比表2的第一个元素小,所以会执行图2-24的第(4)行,而且我们会归并除表1第一个元素之外的所有元素。也就是说,第一个参数是表1其余的部分,即(2,7,7,9),而第二个参数就是整个表2,即(2,4,7,8)。现在两个表开头的元素是相同的。因为图2-24中第(3)行的测试偏向表1,所以我们从表中移出2,而对merge函数的下一次调用中,第一个参数就是(7,7,9),第二个参数还是(2,4,7,8)。
返回的表在第二行中表示,是按从下向上的顺序看的。请注意,与图2-23中合并的迭代描述不同的是,递归算法会从尾部起组成合并后的表,而迭代算法则是从头开始组成合并后的表。
2.8.2 分割表
归并排序的另一项重要任务是将一个表均分为两个表,或者,如果原表的长度为奇数,就分为长度只相差1的两个表。要完成这一工作,一种方式是数出表中元素的数目,然后除以2,并在表的中点将其拆分。我们将给出一个简单的递归函数split,将这些元素“处理”进两个表,其中一个表由第1个、第3个、第5个等元素组成,而另一个表则由偶数位置的元素组成。更确切地说,split函数会将偶数编号的元素从作为参数给出的表中删除,并返回一个由这些偶数编号元素组成的新表。
split函数的C语言代码如图2-27所示,它的参数是LIST类型的表,这样定义是和merge函数有关的。请注意,局部变量pSecondCell被定义为LIST类型。这里是将pSecondCell用作指向表第二个单元(而不是指向表本身)的指针,不过其实LIST类型当然是指向单元的指针。
LIST split(LIST list)
{
LIST pSecondCell;
(1) if (list == NULL) return NULL;
(2) else if (list->next == NULL) return NULL;
else { /* there are at least two cells */
(3) pSecondCell = list->next;
(4) list->next = pSecondCell->next;
(5) pSecondCell->next = split(pSecondCell->next);
(6) return pSecondCell;
}
}
图 2-27 将表均分为两部分
split是个具有副作用的函数。它会从作为参数给出的表中删除偶数位置的单元,而且它会将这些单元组合成一个作为该函数返回值的新表。
我们能以如下形式,用归纳的方式描述该分割算法。它对表的长度进行了归纳,这段归纳具有多个依据情况。
依据。如果表的长度为0或1,那么我们什么都不用做。这就是说,空表会被“分割成”两个空表,而只有一个元素的表,在分割时会将唯一的元素留在给定的表中,并返回一个空的偶数编号元素表(因为原表没有偶数编号的元素,所以这个表中没有元素)。该依据是由图2-27所示程序的第(1)行和第(2)行处理的。第(1)行处理的是list为空的情况,而第(2)行处理的则是list中只含一个元素的情况。请注意,我们在第(2)行中会避免去检查list->next,除非之前在第(1)行中已经确定list不为NULL。
归纳。归纳步骤适用于list中至少存在两个元素的情况。第(3)行中局部变量pSecondCell中存放了指向表第二个单元的指针;第(4)行则是使第一个单元的next字段跳过第二个单元,直接指向第三个单元,或者,如果表中只有两个单元,就变为NULL;在第(5)行,我们对除前两个元素之外的整个表递归地调用split函数;而split函数会在第(6)行返回一个指向第二个单元的指针,该指针让我们可以访问由原表中所有偶数编号的元素组成的链表。
split带来的变化如图2-28所示。原始指针用虚线表示,而新指针用实线表示。我们还指出了创建每个新指针的代码行编号。
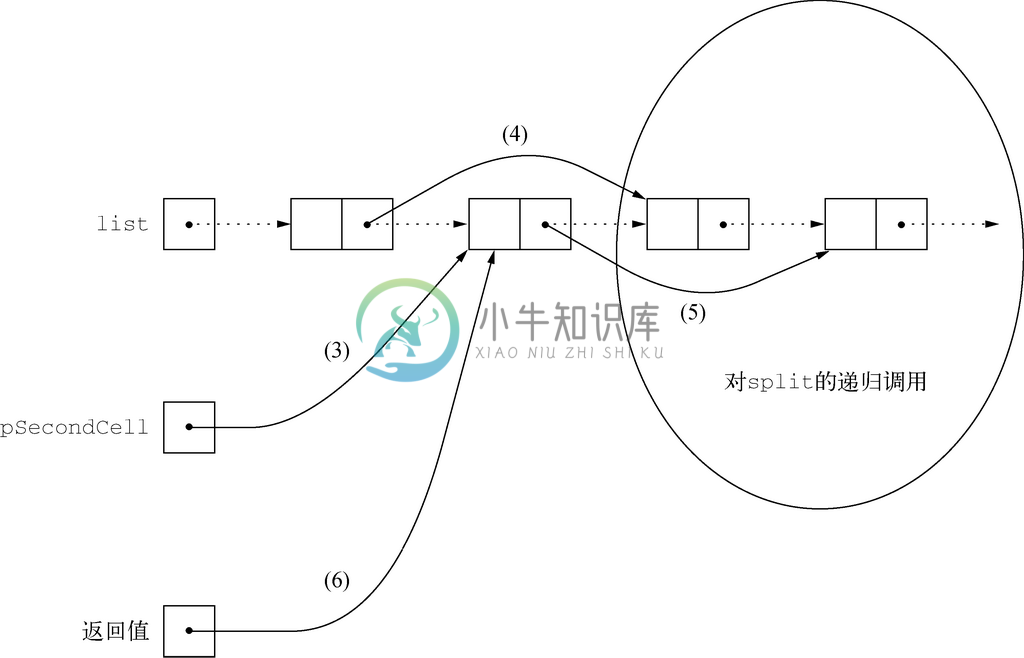
图 2-28 split函数的动作
2.8.3 排序算法
递归的排序算法如图2-29所示,该算法可以通过以下依据与归纳步骤来描述。
LIST MergeSort(LIST list)
{
LIST SecondList;
(1) if (list == NULL) return NULL;
(2) else if (list->next == NULL) return list;
else {
/* 表中至少有两个元素 */
(3) SecondList = split(list);
/* 请注意,这样做的副作用是有一半元素会从表中删除 */
(4) return merge(MergeSort(list), MergeSort(SecondList));
}
}
图 2-29 归并排序算法
依据。如果待排序的表为空或长度为1,那么只要返回该表即可,因为它是已排序的。该依据是由图2-29中的第(1)行和第(2)行处理的。
归纳。如果待排序表的长度至少为2,那么在第(3)行使用split函数,从list中删除偶数编号的元素,并使用这些被删除的元素组成另一个表,该表是由局部变量SecondList指向的。第(4)行会递归地为大小减半的表排序,并返回这两个表的归并结果。
示例 2.25
让我们用归并排序为一列一位数数字742897721排序。为求简洁,我们再次省略了数字之间的逗号。首先,通过MergeSort函数第(3)行中对split的调用,表会被分为两个部分。生成的两个表中有一个是由奇数位置的元素组成,另一个则由偶数位置的元素组成。也就是说,这里有list=72971,而SecondList=4872。在第(4)行,这两个表会被排序,结果就成了表12779和2478,然后就会合并成已排序表122477789。
不过,这两个大小减半的表的排序工作并不是凭空进行的,而是通过对该递归算法的合理应用做到的。一开始,如果作为MergeSort参数的表长度大于1,那么MergeSort就会将其分割。图2-30a展示了对表进行递归分割,直到每个表的长度都成1为止。然后分割的表会成对地合并起来,沿着树结构向上,直到整个表完成排序。这个过程如图2-30b所示。不过,值得注意的是,分割和合并操作是交替进行的,而不是在完成所有分割工作后再进行合并。例如,第一半表72971会在开始处理第二半表4872前被完全分割及合并。
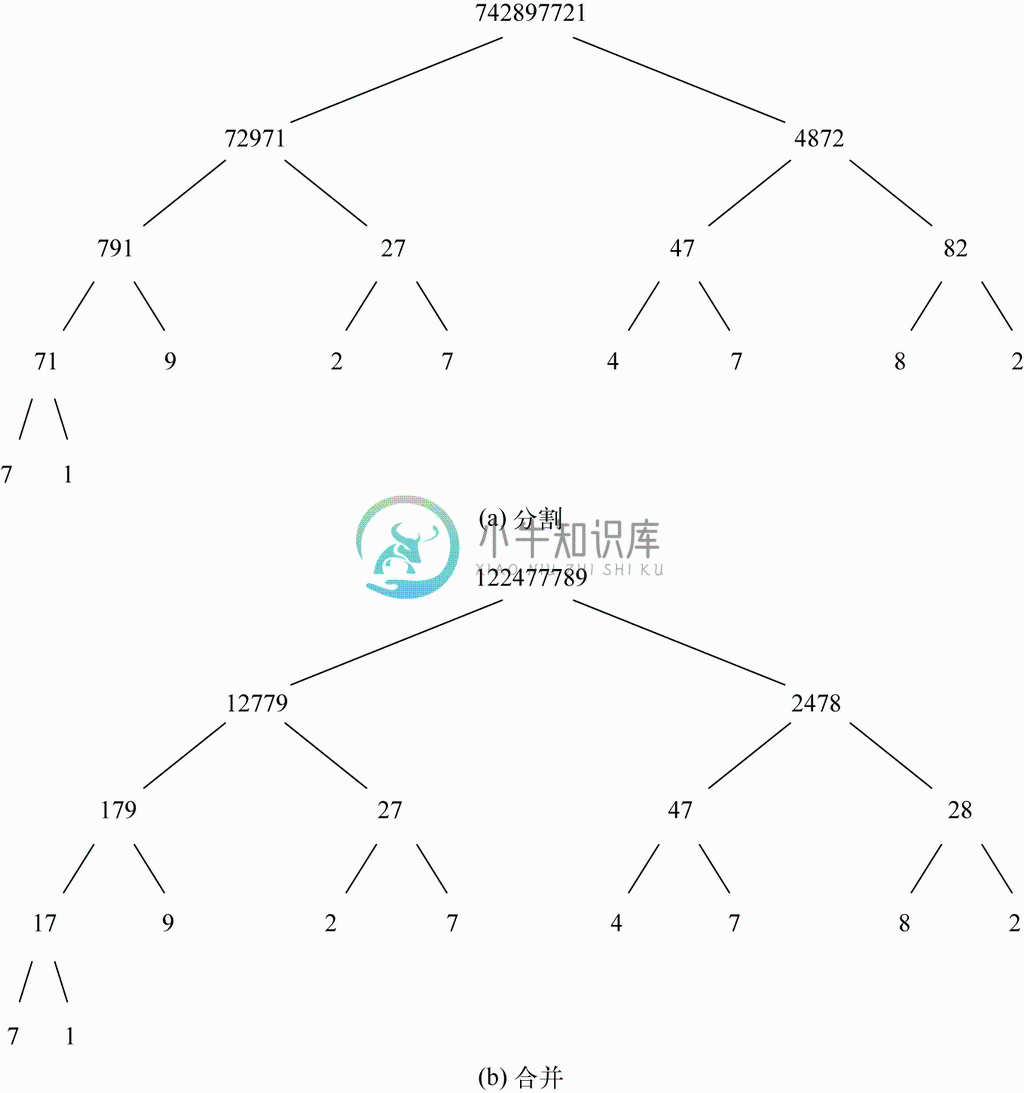
图 2-30 递归的分割和合并
2.8.4 完整的程序
图2-31包含了完整的归并排序程序。它类似于图2-3中所示的选择排序程序。第(1)行中MakeList函数读取输入的每个整数,并通过一个简单的递归算法将其放入链表中(我们将在下一节中详细描述该递归算法)。主程序的第(2)行含有对MergeSort的调用,会将一个已排序表返回给PrintList。而PrintList函数会向下遍历整个已排序表,打印出每个元素。
#include <stdio.h>
#include <stdlib.h>
typedef struct CELL *LIST;
struct CELL {
int element;
LIST next;
};
LIST merge(LIST list1, LIST list2);
LIST split(LIST list);
LIST MergeSort(LIST list);
LIST MakeList();
void PrintList(LIST list);
main()
{
LIST list;
list = MakeList();
(1) PrintList(MergeSort(list));
(2) }
LIST MakeList()
{
int x;
LIST pNewCell;
(3) if (scanf("%d", &x) == EOF) return NULL;
else {
(4) pNewCell = (LIST) malloc(sizeof(struct CELL));
(5) pNewCell->next = MakeList();
(6) pNewCell->element = x;
(7) return pNewCell;
}
}
void PrintList(LIST list)
{
(8) while (list != NULL) {
(9) printf("%d\n", list->element);
(10) list = list->next;
}
}
图 2-31(a) 使用归并排序的排序程序(开头)
LIST MergeSort(LIST list)
{
LIST SecondList;
if (list == NULL) return NULL;
else if (list->next == NULL) return list;
else {
SecondList = split(list);
return merge(MergeSort(list), MergeSort(SecondList));
}
}
LIST merge(LIST list1, LIST list2)
{
if (list1 == NULL) return list2;
else if (list2 == NULL) return list1;
else if (list1->element <= list2->element) {
list1->next = merge(list1->next, list2);
return list1;
}
else {
list2->next = merge(list1, list2->next);
return list2;
}
}
LIST split(LIST list)
{
LIST pSecondCell;
if (list == NULL) return NULL;
else if (list->next == NULL) return NULL;
else {
pSecondCell = list->next;
list->next = pSecondCell->next;
pSecondCell->next = split(pSecondCell->next);
return pSecondCell;
}
}
图 2-31(b) 使用归并排序的排序程序(结尾)
2.8.5 习题
1. 给出对表(1,2,3,4,5)和(2,4,6,8,10)应用merge函数的结果。
2. 假设一开始有表(8,7,6,5,4,3,2,1),给出产生的merge、split和Mergesort的调用序列。
3. * 多路归并排序会将一个表均分为k 个部分(或分为接近均等的k 个部分),并分别为这些表排序,然后,通过比较这k 个表中第一个元素的大小并选出最小的那个,将这些表合并起来。本节中描述的归并算法就是k=2时的情况。修改图2-31中的程序,使其成为k=3情况下的多路归并排序程序。
4. * 重写归并排序程序,使用2.2节习题7中的lt和key函数,以比较任意类型的元素。
5. 将函数merge、split和MakeList分别与图2-21联系起来。这些函数合适的大小各为多少?
2.9 证明递归程序的属性
如果想证明某个递归函数的某个特定属性,通常需要证明关于调用一次该函数的效果的命题。例如,这种效果可能是参数和返回值之间的关系,比如“调用函数,参数为i,返回i !”。我们经常要为函数的参数定义“大小”的概念,并通过对这个大小的归纳进行证明。可以用很多方式定义参数大小,其中包括如下内容。
1. 某个参数的值。比如,在图2-19的阶乘递归程序中,合适的参数大小就是参数n 的值。
2. 某个参数指向的表的长度。图2-27所示的split递归函数就是个例子,合适的参数大小是表的长度。
3. 参数构成的某些函数。例如,前面提到过,图2-22中递归的选择排序会对数组中有待排序的元素数目进行归纳。对参数n 和i 来说,该函数就是n-i+1。再比如,图2-24中merge函数合适的参数大小就是两个参数指向的表的长度之和。
不管选择了什么样的参数大小,关键是,在函数被调用时,如果参数的大小为s,那么只能以大小为s-1或更小的参数执行函数调用。这样我们可以对参数大小进行归纳,从而证明程序的属性。此外,当这个大小下降到某个固定的值(例如0)时,该函数一定不会再进行递归调用了,因而我们可以由依据情况开始进行归纳证明了。
示例 2.26
考虑2.7节图2-19中的阶乘程序。通过对i的归纳,证明对i≥1,有如下命题为真。
命题 S(i )。在调用fact时如果参数n的值为i,那么fact会返回i !。
依据。对i=1,图2-19中第(1)行的测试会使作为依据的第(2)行被执行,结果返回值为1,也就是1!。
归纳。假设S(i)为真,也就是说,在调用fact时,如果参数为某个值不小于1的i,那么它会返回i!。现在,考虑在调用fact时,变量n的值为i+1的情况。如果i≥1,那么i+1至少等于2,所以第(3)行的归纳情况是适用的,因此返回值就是n×fact(n-1)。或者有,因为变量n的值为i+1,返回的结果是(i+1)×fact(i )。由归纳假设,fact(i)返回了i !。因为有(i+1)×i !=(i+1)!,所以证明了归纳步骤,也就是参数为i+1的fact函数会返回(i+1)!。
示例 2.27
现在,我们来看看2.8节图2-31a中的辅助例程——MakeList函数。该函数会创建一个用来存放输入元素的链表,并返回指向该链表的指针。我们要对输入序列中元素的数目n进行归纳,证明对n≥0,有以下命题为真。
命题 S(n)。若输入序列为x1、x2、…、xn则MakeList会创建一个含有x1、x2、…、xn的链表,并返回指向该链表的指针。
依据。依据为n=0,也就是,当输入序列为空时的情况。第(3)行中MakeList函数对EOF的测试会导致返回值被置为NULL。因此,MakeList正确地返回了空链表。
归纳。假设对n≥0,有S(n)为真,并考虑对有n+1个元素的序列调用MakeList时会发生的情况。假设我们刚读取了第一个元素x1。
MakeList的第(4)行会创建指向新单元c的指针。由归纳假设,第(5)行会递归调用Makelist创建一个指针,指向存放其余n个元素x2、x3、…、xn+1的链表。该指针在第(5)行会被装入c 的next字段。第(6)行则会将x1装入c 的element字段。第(7)行会返回第(4)行所创建的指针。该指针指向存放x1、x2、…、xn+1这n+1个输入元素的链表。
这样就证明了归纳步骤,并得出MakeList能正确处理所有输入的结论。
示例 2.28
在最后一个示例中,要证明图2-29中归并排序程序的正确性,其中假设split和merge函数分别能正确执行它们的任务。我们要对作为MergeSort函数的参数的表的长度进行归纳。要通过对不小于0的n进行完全归纳来证明的命题如下。
命题 S(n)。如果list是MergeSort被调用时长度为n 的表,那么MergeSort将返回具有相同元素的已排序表。
依据。要使用S(0)和S(1)作为依据。当list的长度为0时,它的值为NULL,因此图2-29中第(1)行的测试会成功,而整个函数会直接返回NULL。同样,如果list的长度是1,第(2)行的测试会成功,函数就会直接返回list。因此,MergeSort函数在n 等于0或1时会返回list。这一结果证明了S(0)和S(1),因为长度为0或1的表本来就是已排序的。
归纳。假设n≥1,而且对所有的i=0、1、…n,都有S(i )为真。我们必须要证明S(n+1)为真。因此,要考虑长度为n+1的表。因为n≥1,所以表的长度至少为2,这样就到达了图2-29中的第(3)行。在那里,如果表的长度n+1为偶数,split就会把该表分为两个长度都为(n+1)/2的表,否则如果n+1为奇数,就分为长度分别为(n/2)+1和n/2的两个表。因为n≥1,所以这些表的长度不可能达到n+1。这样的话,归纳假设适用于它们,我们就可以由此得出结论,通过对第(4)行的递归调用,正确地对长度减半的表进行了排序。我们已假设merge是能正确工作的,所以返回的表也是已排序的。
习题
1. 证明:图2-31b中的PrintList函数会打印出作为参数传入的表中的元素。需要递归证明的命题S(i )是什么?作为依据的i 值是多少?
2. 图2-32中的sum函数可以计算给定表中各元素之和,该表中的单元具有1.6节中的DefCell宏所定义的常见类型,这些类型在2.8节中的归并排序程序中使用过。它是通过将第一个元素加在剩余元素的和上计算所有元素之和的,而这里提到的剩余元素之和,是通过对表剩余部分递归调用该函数计算的。证明:sum函数可以正确地计算表元素之和。需要归纳证明的命题S(i )是什么?作为依据的i 值是多少?
DefCell(int, CELL, LIST);
int sum(LIST L)
{
if (L == NULL) return 0;
else return(L->element + sum(L->next));
}
int find0(LIST L)
{
if (L == NULL) return FALSE;
else if (L->element == 0) return TRUE;
else return find0(L->next);
}
图 2-32 递归函数sum和find0
3. 如果表中的元素至少有一个为0,那么图2-32中的find0函数会返回TRUE,否则就返回FALSE。如果表为空,它就返回FALSE,而如果第一个元素是0,就返回TRUE,不然的话,就对表其余部分执行递归调用,并返回为剩余部分生成的任何答案。证明:find0可以正确地确定表中是否出现元素0。需要归纳证明的命题S(i )是什么?作为依据的i 值是多少?
4. * 证明:图2-24中的merge函数和图2-27中的split函数会按2.8节中所说的那样执行。
5. 用“最少反例”直观地证明从以0和1两个值为依据开始的归纳证明是有效的。
6. ** 证明2.7节习题8中用C语言实现的递归的最大公约数算法的正确性。
2.10 小结
我们从本章学习到了以下知识。
归纳证明、递归定义和递归程序是紧密相关的概念。它们要想“起作用”,都依赖于依据和归纳步骤。
在“普通归纳”或者说是“弱归纳”中,成功的那一步骤只依靠它的前一个步骤。我们经常需要进行完全归纳证明,而完全归纳中每个步骤都取决于之前的所有步骤。
进行排序的方法有很多。选择排序是一种简单但速度很慢的排序算法,而归并排序是一种速度比较快但比较复杂的算法。
归纳是证明程序或程序段能正确运转的关键。
分治法是一种用来设计某些优秀算法(比如归并排序)的实用技术。它的工作原理是将问题分为独立的子部分,然后将得到的结果结合起来。
表达式天生是由它们的操作数和运算符按照递归方式定义的。运算符可以按照它们接受参数的数量来分类:一元运算符(一个参数)、二元运算符(两个参数)以及k 元运算符(k 个参数)。还有,出现在两个操作数之间的二元运算符是中缀运算符,而出现在操作数之前的是前缀运算符,出现在操作数之后的则是后缀运算符。
2.11 参考文献
Roberts [1986]对递归进行了极佳的介绍。要了解更多与排序算法有关的内容,Knuth [1973] 是标准的参考之作。Berlekamp [1968]讲述了从比特流中检测和收集错误的技术(2.3节介绍的是最简单的检错模式)。
Berlekamp, E. R. [1968]. Algebraic Coding Theory, McGraw-Hill, New York.
Knuth, D. E. [1973]. The Art of Computer Programming, Vol. III: Sorting and Searching, Addison-Wesley, Reading, Mass.
Roberts, E. [1986]. Thinking Recursively, Wiley, New York.