
C++中的左值与右值
说明
- 这一部分内容只是帮助理解 C++(11) 中左值与右值的概念。
- 在编程实践中,因为编译器优化的存在,特别是其中的返回值优化(Return Value Optimization, RVO)使你不需要额外关注左值与右值的区别,像 C++(03) 一样编程即可。
C++11 rvalues and move semantics confusion (return statement) - Stack Overflow
- 除非你在进行库的开发,特别是涉及模板元编程等内容时,需要实现移动构造函数(move constructor),或者完美转发
小结
左值引用类型 与 右值引用类型
T t1; // 类型 T
T& t2 = t1; // T& 表示 T 的左值引用类型,t2 是左值引用类型的变量,它引用的是一个左值
T&& t3 = T(); // T&& 表示 T 的右值引用类型,t3 是右值引用类型的变量,它引用的是一个右值
T& t4 = T(); // err: 左值引用 不能绑定一个 右值
T&& t5 = t1; // err: 右值引用 不能绑定一个 左值
const T& t6 = t1; // const T& 表示 T 的常量(左值)引用
const T& t7 = T(); // 常量引用类型是“万能”的引用类型
// 不能把 常量类型 绑定到 非常量引用类型 上
T&& t8 = t6; // err: 不能把常量类型绑定到 右值引用类型
T& t9 = t6; // err: 也不能把常量类型绑定到 左值引用类型这里的变量 t1~t9 都是左值,因为它们都有名字
当发生自动类型推断时,T&& 也能绑定左值
template<typename T> // 模板元编程
void foo(T&& t) { } // 此时 T&& 不是右值引用类型,而是未定引用类型
void bar(int&& v) { } // 非模板编程,int&& 是明确的右值引用类型
foo(10); // OK: 未定引用类型 t 绑定了一个右值
bar(10); // OK: 右值引用类型 v 绑定了一个右值
int x = 10;
foo(x); // OK: 未定引用类型 t 绑定了一个左值
bar(x); // err: 右值引用类型 v 不能绑定一个左值
int&& p = x; // err
auto&& t = x; // OK- 此时,
T&&就不再是右值引用类型,而是未定引用类型
如何快速判断左值与右值
- 能被
&取地址的就是左值int foo; // foo 是一个左值 cout << &foo; // 可以被取地址 foo = foo + 5; // foo + 5 是一个左值 cout << &(foo+5); // err cout << &1; // err- 多数常数、字符等字面量都是右值,但字符串是左值
- 虽然字符串字面量是左值;但它是 const 左值(只读对象),所以也不能对它赋值
cout << &'a'; // err: lvalue required as unary '&' operand cout << &"abc"; // OK, 可以对字符串取地址 "abc" = "cba"; // err: assignment of read-only location为什么字符串字面量是对象?——节省内存,同一份字符串字面量引用的是同一块内存
- 所有的具名变量或对象都是左值,而匿名变量/临时变量则是右值
- 匿名变量/临时变量的特点是表达式结束后就销毁了
int i = 5; // int 型字面量 auto f = []{return 5;}; // lambda 表达式
- 匿名变量/临时变量的特点是表达式结束后就销毁了
引用折叠规则
- 所有的右值引用叠加到右值引用上仍然还是一个右值引用。(
T&& && 变成 T&&) - 所有的其他引用类型之间的叠加都将变成左值引用。 (
T& &, T& &&, T&& & 都变成 T&) - 对常量引用规则一致
示例
typedef int & lRef; typedef int && rRef; typedef const int & lcRef; typedef const int && rcRef; int main() { int a = 10; // 左值引用 lRef b = a; // T& lRef & c = a; // T& & lRef && d = a; // T& && rRef & e = a; // T&& & // 右值引用 rRef f = 10; // T&& rRef && g = 10; // T&& && // 左值引用 lcRef b2 = a; // const T& lcRef & c2 = a; // const T& & lcRef && d2 = a; // const T& && rcRef & e2 = a; // const T&& & // 右值引用 rcRef f2 = 10; // const T&& rcRef && g2 = 10; // const T&& && return 0; }
move() 与 forward()
move()的主要作用是将一个左值转为 xvalue(右值), 其实现本质上是一个static_cast<T>forward()主要用于实现完美转发,其作用是将一个类型为(左值/右值)引用的左值,转化为它的类型所对应的值类型(左值/右值)觉得难以理解的话,就继续看下去吧
左值与右值的本质
- 左值表示是“对象”(object),右值表示“值”(value)——“对象”内存储着“值”
- 左值
->右值的转换可看做“读取对象的值”(reading the value of an object) - 其他说法:
- 左值是可以作为内存单元地址的值;右值是可以作为内存单元内容的值
- 左值是内存中持续存储数据的一个地址;右值是临时表达式结果
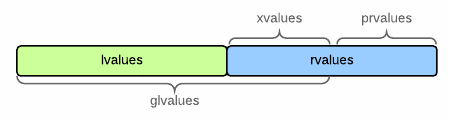
左值、消亡值、纯右值
C++11 开始,表达式一般分为三类:左值(lvalue)、消亡值(xvalue)和纯右值(prvalue);
其中左值和消亡值统称泛左值(glvalue);
消亡值和纯右值统称右值(rvalue)。
右值引用的特点
右值引用延长了临时对象的生命周期
int i = getI(); // getI() 会返回一个 int 型的临时变量
T&& t = getT(); // t 是一个右值引用
// getT() 同样返回一个临时变量,但是该临时变量被“引用”了
// 因此生命周期得到了延长getI()和getT()都返回一个临时变量,但是getT()产生的临时变量不会在表达式结束后就马上销毁,而是会被“续命”——它的声明周期将和它的引用类型变量t一样长。
利用右值引用避免临时对象的拷贝和析构
int g_constructCount=0;
int g_copyConstructCount=0;
int g_destructCount=0;
struct A {
A(){ // 基本构造
cout<<"construct: "<<++g_constructCount<<endl;
}
A(const A& a) { // 拷贝构造
cout<<"copy construct: "<<++g_copyConstructCount <<endl;
}
~A() { // 析构
cout<<"destruct: "<<++g_destructCount<<endl;
}
};
A getA() {
A a; // 第一次构造
return a;
// return A(); // 等价,分开写是为了便于说明
}
int main() {
A a2 = getA(); // 非右值引用
A&& a3 = getA(); // 右值引用
return 0;
}- 非右值引用,关闭返回值优化
construct: 1 // 第一次构造,getA() 中的局部变量 a copy construct: 1 // 第二次构造,将 a 复制给一个临时变量 destruct: 1 // 析构局部变量 a copy construct: 2 // 第三次构造,将临时变量复制给 a2 destruct: 2 // 析构临时变量 destruct: 3 // 程序结束,析构变量 a2 - 右值引用,关闭返回值优化
construct: 1 // 第一次构造,getA() 中的局部变量 a copy construct: 1 // 第二次构造,将 a 复制给一个临时变量 // 右值引用 a3 延长了临时变量的声明周期,使其没有马上被析构 destruct: 1 // 析构局部变量 a destruct: 2 // 程序结束,析构变量 a3利用常量引用也能避免临时对象的拷贝与析构 -> 常量(左值)引用
返回值优化做的更彻底 -> 返回值优化 RVO
右值引用类型绑定的一定是右值,但 T&& 可能不是右值引用类型
int&& v1 = 1; // OK: v1 是右值引用类型,且 1 是右值
int&& v2 = v1; // err: v2 是右值引用类型,但 v1 是左值当发生自动类型推断时,T&& 是未定的引用类型
T&& t在发生自动类型推断时,是未定的引用类型- 比如模板元编程,auto 关键字等
- 如果
t被一个左值初始化,它就是一个左值;如果t被一个右值初始化,它就是一个右值template<typename T> // 模板元编程 void foo(T&& t) { } // 此时 T&& 不是右值引用类型,而是未定引用类型
foo(10); // OK: 未定引用类型 t 绑定了一个右值
int x = 10; foo(x); // OK: 未定引用类型 t 绑定了一个左值
int&& p = x; // err auto&& t = x; // OK
仅当发生自动类型推导时(模板编程,auto 关键字),
T&&才是未定引用类型void bar(int&& v) { } // 非模板编程,int&& 是明确的右值引用类型 bar(10); // OK: 右值引用类型 v 绑定了一个右值 int x = 10; bar(x); // err: 右值引用类型 v 不能绑定一个左值
常量(左值)引用
- 右值引用是 C++11 引入的概念
- 在 C++11 前,是如何避免临时对象的拷贝和析构呢?——利用常量左值引用
const A& a = getA(); // OK: 常量左值引用可以接受右值 - 常量左值引用是一个“万能”的引用类型,可以接受左值、右值、常量左值和常量右值
- 普通的左值引用不能接受右值
A& a = getA(); // err: 非常量左值引用只能接受左值
返回值优化 RVO
利用右值引用可以避免临时对象的拷贝可析构
但编译器的返回值优化(Return Value Optimization, RVO)做得“更绝”,直接回避了所有拷贝构造
int g_constructCount=0; int g_copyConstructCount=0; int g_destructCount=0; struct A { A(){ // 基本构造 cout<<"construct: "<<++g_constructCount<<endl; } A(const A& a) { // 拷贝构造 cout<<"copy construct: "<<++g_copyConstructCount <<endl; } ~A() { // 析构 cout<<"destruct: "<<++g_destructCount<<endl; } }; A getA() { A a; // 第一次构造 return a; // return A(); // 等价,分开写是为了便于说明 } int main() { A aa = getA(); // 第二次构造:把 a 复制给一个临时变量, // 第三次构造:把临时变量复制给 aa // 开启优化后,相当于直接把 a “改名”成 aa 了,所以只有一次构造 return 0; }- 关闭编译器优化的结果
construct: 1 // 第一次构造,getA() 中的局部变量 a copy construct: 1 // 第二次构造,将 a 复制给一个临时变量 destruct: 1 // 析构局部变量 a copy construct: 2 // 第三次构造,将临时变量复制给 aa destruct: 2 // 析构临时变量 destruct: 3 // 程序结束,析构变量 aa - 开启编译器优化
construct: 1 // 构造局部变量 a,在编译的优化下,相当于直接将 a “改名” aa destruct: 1 // 程序结束,析构变量 aa - 返回值优化并不是 C++ 的标准,是各编译器优化的结果,但是这项优化并不复杂,所以基本流行的编译器都提供
- 关闭编译器优化的结果
移动语义
深拷贝带来的问题
带有堆内存的类,必须提供一个深拷贝构造函数,以避免“指针悬挂”问题
所谓指针悬挂,指的是两个对象内部的成员指针变量指向了同一块地址,析构时这块内存会因被删除两次而发生错误
class A { public: A(): m_ptr(new int(0)) { // new 堆内存 cout << "construct" << endl; }A(const A& a):m_ptr(new int(*a.m_ptr)) { // 深拷贝构造函数 cout << "copy construct" << endl; } ~A(){ // cout << "destruct" << endl; delete m_ptr; // 析构函数,释放堆内存的资源 }private: int* m_ptr; // 成员指针变量 };
A getA() { return A(); }
int main() { A a = getA(); return 0; }
- 输出(关闭 RVO) ```Cpp construct copy construct copy construct如果不关闭 RVO,只会输出
construct提供深拷贝能够保证程序的正确性,但会带来额外的性能损耗——临时对象也会申请一块内存,然后又马上被销毁了;如果堆内存很大的话,这个性能损耗是不可忽略的
对于临时对象而言,深拷贝不是必须的
利用右值引用可以避免无谓的深拷贝——移动拷贝构造函数
移动构造函数
相比上面的代码,这里只多了一个移动构造函数——一般会同时提供拷贝构造与移动构造
class A { public: A(): m_ptr(new int(0)) { // new 堆内存 cout << "construct" << endl; } A(const A& a): m_ptr(new int(*a.m_ptr)) { // 深拷贝构造函数 cout << "copy construct" << endl; } A(A&& a): m_ptr(a.m_ptr) { // 移动构造函数 a.m_ptr = nullptr; // 把参数对象的指针指向 nullptr cout << "move construct" << endl; } ~A(){ // cout << "destruct" << endl; delete m_ptr; // 析构函数,释放堆内存的资源 } private: int* m_ptr; // 成员指针变量 }; A getA() { return A(); } int main() { A a = getA(); return 0; }输出(关闭返回值优化)
construct move construct // 没有调用深拷贝,值调用了移动构造函数 move construct如果不关闭 RVO,只会输出
construct这里没有自动类型推断,所以
A&&一定是右值引用类型,因此所有临时对象(右值)会匹配到这个构造函数,而不会调用深拷贝对于临时对象而言,没有必要调用深拷贝
这就是所谓的移动语义——右值引用的一个重要目的就是为了支持移动语义
移动语义 与 move()
移动语义是通过右值引用来匹配临时值,从而避免深拷贝
利用
move()方法,可以将普通的左值转化为右值来达到避免深拷贝的目的class A { public: A(): m_ptr(new int(0)) { // new 堆内存 cout << "construct" << endl; } A(const A& a): m_ptr(new int(*a.m_ptr)) { // 深拷贝构造函数 cout << "copy construct" << endl; } A(A&& a): m_ptr(a.m_ptr) { // 移动构造函数 //a.m_ptr = nullptr; // 为了实验,这里没有把参数对象的指针指向 nullptr cout << "move construct" << endl; } ~A(){ // cout << "destruct" << endl; delete m_ptr; // 析构函数,释放堆内存的资源 } int get_data() { return *m_ptr; } void set_data(int v) { *m_ptr = v; } private: int* m_ptr; // 成员指针变量 }; int main() { A a1; // construct a1.set_data(1); cout << a1.get_data() << endl; // 1 A a2 = a1; // copy construct cout << a2.get_data() << endl; // 1 a2.set_data(2); cout << a2.get_data() << endl; // 2 cout << a1.get_data() << endl; // 1 A a3 = move(a1); // move construct a3.set_data(3); cout << a3.get_data() << endl; // 3 cout << a1.get_data() << endl; // 3: 因为没有深拷贝,指向的是同一块地址 return 0; }- 运行结果
construct 1 copy construct 1 2 1 move construct 3 3
- 运行结果
STL 容器的移动语义
{ list<string> tokens; //省略初始化... list<string> t = tokens; // 这里存在深拷贝 } list<string> tokens; list<string> t = move(tokens); // 这里没有深拷贝- C++11 中所有的容器都实现了移动语义
move() 的本质
move()实际上并没有移动任何东西,它唯一的功能是将一个左值强制转换为一个右值引用- 如果没有对应的移动构造函数,那么使用
move()仍会发生深拷贝,比如基本类型,定长数组等 - 因此,
move()对于含有资源(堆内存或句柄)的对象来说更有意义。
move() 的原型 TODO
完美转发
右值引用的引入,使函数可以根据值的类型(左值或右值)进行不同的处理
于是又引入了一个问题——如何正确的传递参数,保持参数作为左值或右值的特性
转发失败的例子:
void processValue(int& a) { cout << "lvalue" << endl; } void processValue(int&& a) { cout << "rvalue" << endl; } template <typename T> void forwardValue(T&& val) { processValue(val); // 因为 val 本身是一个左值 // 所以无论 val 是左值引用类型还是右值引用类型的变量 // 都只会调用 processValue(int& a) } int main() { int i = 1; forwardValue(i); // 传入一个左值 // val 会被推断为是一个左值引用类型 forwardValue(1); // 传入一个右值 // 虽然 val 会被推断为是一个右值引用类型,但它本身是一个左值 return 0; }- 输出
lvalue lvalue - 无论传入的是左值还是右值,val 都是一个左值
- 输出
forward<T>() 实现完美转发
这里写的不够详细,有时间在整理
- 在函数模板中,
T&&实际上是未定引用类型,它是可以得知传入的对象是左值还是右值的- 这个特性使其可以成为一个参数的路由,利用
forward()实现完美转发std::forward<T>()可以保留表达式作为“对象”(左值)或“值”(右值)的特性<!-- ```Cpp int&& a = 1;
cout << &a; // OK: 虽然 a 是一个右值引用类型的变量,但它本身是一个左值 cout << &forward(a); // err: taking address of xvalue (rvalue reference)
- 利用 `std::forward<T>()` 实现完美转发:
> 不可以用变量接收 `forward<T>()` 的返回值,因为所有具名变量都是左值
```Cpp
void processValue(int& a) { cout << "lvalue" << endl; }
void processValue(int&& a) { cout << "rvalue" << endl; }
template <typename T>
void forwardValue(T&& val) {
processValue(forward<T>(val)); // 利用 forward 保持对象的左右值特性
// 必须把 forward<T>(val) 打包作为参数,否则都达不到完美转发的目的
// auto v = forward<T>(val);
// processValue(v);
// auto&& v = forward<T>(val);
// processValue(v);
}
int main() {
int i = 1;
forwardValue(i); // 传入一个左值
forwardValue(1); // 传入一个右值
return 0;
}- 输出
lvalue rvalue - 正确实现了转发
forward<T>()的原型 TODO
Reference
- The lvalue/rvalue metaphor — Joseph Mansfield
- 关于C++左值和右值区别有没有什么简单明了的规则可以一眼辨别? - 知乎
- 从4行代码看右值引用 - qicosmos(江南) - 博客园
- c++11 中的 move 与 forward - twoon - 博客园
- 左值右值的一点总结 - twoon - 博客园