
自然语言处理基础
自然语言处理之序列模型 - 小象学院
解决 NLP 问题的一般思路
这个问题人类可以做好么? - 可以 -> 记录自己的思路 -> 设计流程让机器完成你的思路 - 很难 -> 尝试从计算机的角度来思考问题
NLP 的历史进程
规则系统
正则表达式/自动机
规则是固定的
搜索引擎
“豆瓣酱用英语怎么说?” 规则:“xx用英语怎么说?” => translate(XX, English) “我饿了” 规则:“我饿(死)了” => recommend(饭店,地点)
概率系统
规则从数据中抽取
规则是有概率的
概率系统的一般工作方式
流程设计 收集训练数据 预处理 特征工程 分类器(机器学习算法) 预测 评价
- 最重要的部分:数据收集、预处理、特征工程
示例
任务: “豆瓣酱用英语怎么说” => translate(豆瓣酱,Eng) 流程设计(序列标注): 子任务1: 找出目标语言 “豆瓣酱用 **英语** 怎么说” 子任务2: 找出翻译目标 “ **豆瓣酱** 用英语怎么说” 收集训练数据: (子任务1) “豆瓣酱用英语怎么说” “茄子用英语怎么说” “黄瓜怎么翻译成英语” 预处理: 分词:“豆瓣酱 用 英语 怎么说” 抽取特征: (前后各一个词) 0 茄子: < _ 用 0 用: 豆瓣酱 _ 英语 1 英语: 用 _ 怎么说 0 怎么说: 英语 _ > 分类器: SVM/CRF/HMM/RNN 预测: 0.1 茄子: < _ 用 0.1 用: 豆瓣酱 _ 英语 0.7 英语: 用 _ 怎么说 0.1 怎么说: 英语 _ > 评价: 准确率
概率系统的优/缺点
+规则更加贴近于真实事件中的规则,因而效果往往比较好-特征是由专家/人指定的;-流程是由专家/人设计的;-存在独立的子任务
深度学习
- 深度学习相对概率模型的优势
- 特征是由专家指定的
->特征是由深度学习自己提取的 - 流程是由专家设计的
->模型结构是由专家设计的 - 存在独立的子任务
->End-to-End Training
- 特征是由专家指定的
- 深度学习相对概率模型的优势
Seq2Seq 模型
大部分自然语言问题都可以使用 Seq2Seq 模型解决

“万物”皆 Seq2Seq

评价机制
困惑度 (Perplexity, PPX)
Perplexity - Wikipedia
- 在信息论中,perplexity 用于度量一个概率分布或概率模型预测样本的好坏程度 ../机器学习/信息论
基本公式
概率分布(离散)的困惑度
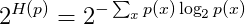
其中
H(p)即信息熵概率模型的困惑度

通常
b=2指数部分也可以是交叉熵的形式,此时困惑度相当于交叉熵的指数形式
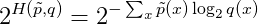
其中
p~为测试集中的经验分布——p~(x) = n/N,其中n为 x 的出现次数,N 为测试集的大小
语言模型中的 PPX
在 NLP 中,困惑度常作为语言模型的评价指标

直观来说,就是下一个候选词数目的期望值——
如果不使用任何模型,那么下一个候选词的数量就是整个词表的数量;通过使用
bi-gram语言模型,可以将整个数量限制到200左右
BLEU
一种机器翻译的评价准则——BLEU - CSDN博客
- 机器翻译评价准则
- 计算公式
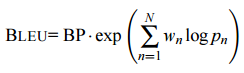
其中
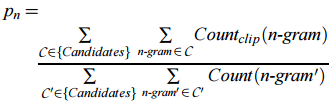
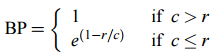
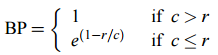
> `c` 为生成句子的长度;`r` 为参考句子的长度——目的是**惩罚**长度过短的候选句子为了计算方便,会加一层
log
通常
N=4, w_n=1/4
ROUGE
自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S - CSDN博客
- 一种机器翻译/自动摘要的评价准则
XX 模型的含义
- 如果能使用某个方法对 XX 打分(Score),那么就可以把这个方法称为 “XX 模型”
- 篮球明星模型:
Score(库里)、Score(詹姆斯) - 话题模型——对一段话是否在谈论某一话题的打分
Score( NLP | "什么 是 语言 模型?" ) --> 0.8 Score( ACM | "什么 是 语言 模型?" ) --> 0.05
- 篮球明星模型:
概率/统计语言模型 (PLM, SLM)
语言模型是一种对语言打分的方法;而概率语言模型把语言的“得分”通过概率来体现
具体来说,概率语言模型计算的是一个序列作为一句话可能的概率
Score("什么 是 语言 模型") --> 0.05 # 比较常见的说法,得分比较高 Score("什么 有 语言 模型") --> 0.01 # 不太常见的说法,得分比较低以上过程可以形式化为:
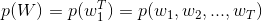
根据贝叶斯公式,有
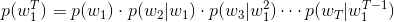
其中每个条件概率就是模型的参数;如果这个参数都是已知的,那么就能得到整个序列的概率了
参数的规模
- 设词表的大小为
N,考虑长度为T的句子,理论上有N^T种可能的句子,每个句子中有T个参数,那么参数的数量将达到O(T*N^T)
可用的概率模型
- 统计语言模型实际上是一个概率模型,所以常见的概率模型都可以用于求解这些参数
- 常见的概率模型有:N-gram 模型、决策树、最大熵模型、隐马尔可夫模型、条件随机场、神经网络等
- 目前常用于语言模型的是 N-gram 模型和神经语言模型(下面介绍)
N-gram 语言模型
马尔可夫(Markov)假设——未来的事件,只取决于有限的历史
基于马尔可夫假设,N-gram 语言模型认为一个词出现的概率只与它前面的 n-1 个词相关
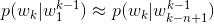
根据条件概率公式与大数定律,当语料的规模足够大时,有
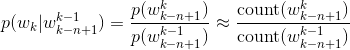
以
n=2即 bi-gram 为例,有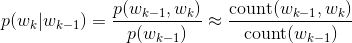
假设词表的规模
N=200000(汉语的词汇量),模型参数与 `n· 的关系表
可靠性与可区别性
- 假设没有计算和存储限制,
n是不是越大越好? - 早期因为计算性能的限制,一般最大取到
n=4;如今,即使n>10也没有问题, - 但是,随着
n的增大,模型的性能增大却不显著,这里涉及了可靠性与可区别性的问题 - 参数越多,模型的可区别性越好,但是可靠性却在下降——因为语料的规模是有限的,导致
count(W)的实例数量不够,从而降低了可靠性
OOV 问题
- OOV 即 Out Of Vocabulary,也就是序列中出现了词表外词,或称为未登录词
- 或者说在测试集和验证集上出现了训练集中没有过的词
- 一般解决方案:
- 设置一个词频阈值,只有高于该阈值的词才会加入词表
- 所有低于阈值的词替换为 UNK(一个特殊符号)
- 无论是统计语言模型还是神经语言模型都是类似的处理方式
平滑处理 TODO
count(W) = 0是怎么办?- 平滑方法(层层递进):
- Add-one Smoothing (Laplace)
- Add-k Smoothing (k<1)
- Back-off (回退)
- Interpolation (插值法)
- Absolute Discounting (绝对折扣法)
- Kneser-Ney Smoothing (KN)
- Modified Kneser-Ney
自然语言处理中N-Gram模型的Smoothing算法 - CSDN博客
神经概率语言模型 (NPLM)
- 神经概率语言模型依然是一个概率语言模型,它通过神经网络来计算概率语言模型中每个参数
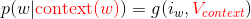
- 其中 `g` 表示神经网络,`i_w` 为 `w` 在词表中的序号,`context(w)` 为 `w` 的上下文,`V_context` 为上下文构成的特征向量。
- `V_context` 由上下文的**词向量**进一步组合而成N-gram 神经语言模型
A Neural Probabilistic Language Model (Bengio, et al., 2003)
- 这是一个经典的神经概率语言模型,它沿用了 N-gram 模型中的思路,将
w的前n-1个词作为w的上下文context(w),而V_context由这n-1个词的词向量拼接而成,即

- 其中 `c(w)` 表示 `w` 的词向量
- 不同的神经语言模型中 `context(w)` 可能不同,比如 Word2Vec 中的 CBOW 模型- 每个训练样本是形如
(context(w), w)的二元对,其中context(w)取 w 的前n-1个词;当不足n-1,用特殊符号填充- 同一个网络只能训练特定的
n,不同的n需要训练不同的神经网络
- 同一个网络只能训练特定的
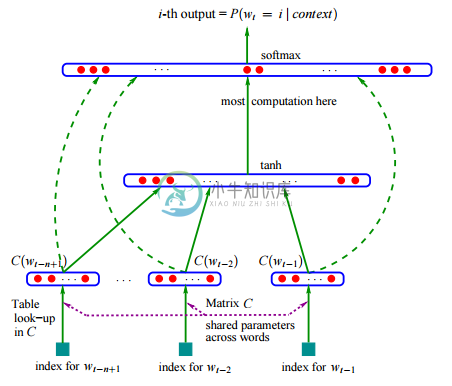
N-gram 神经语言模型的网络结构
【输入层】首先,将
context(w)中的每个词映射为一个长为m的词向量,词向量在训练开始时是随机的,并参与训练;【投影层】将所有上下文词向量拼接为一个长向量,作为
w的特征向量,该向量的维度为m(n-1)【隐藏层】拼接后的向量会经过一个规模为
h隐藏层,该隐层使用的激活函数为tanh【输出层】最后会经过一个规模为
N的 Softmax 输出层,从而得到词表中每个词作为下一个词的概率分布其中
m, n, h为超参数,N为词表大小,视训练集规模而定,也可以人为设置阈值训练时,使用交叉熵作为损失函数
当训练完成时,就得到了 N-gram 神经语言模型,以及副产品词向量
整个模型可以概括为如下公式:


原文的模型还考虑了投影层与输出层有有边相连的情形,因而会多一个权重矩阵,但本质上是一致的:

模型参数的规模与运算量
- 模型的超参数:
m, n, h, Nm为词向量的维度,通常在10^1 ~ 10^2n为 n-gram 的规模,一般小于 5h为隐藏的单元数,一般在10^2N位词表的数量,一般在10^4 ~ 10^5,甚至10^6
- 网络参数包括两部分
- 词向量
C: 一个N * m的矩阵——其中N为词表大小,m为词向量的维度 - 网络参数
W, U, p, q:- W: h * m(n-1) 的矩阵 - p: h * 1 的矩阵 - U: N * h 的矩阵 - q: N * 1 的矩阵
- 词向量
- 模型的运算量
- 主要集中在隐藏层和输出层的矩阵运算以及 SoftMax 的归一化计算
- 此后的相关研究中,主要是针对这一部分进行优化,其中就包括 Word2Vec 的工作
相比 N-gram 模型,NPLM 的优势
- 单词之间的相似性可以通过词向量来体现
相比神经语言模型本身,作为其副产品的词向量反而是更大的惊喜
- 自带平滑处理
NPLM 中的 OOV 问题
- 在处理语料阶段,与 N-gram 中的处理方式是一样的——将不满阈值的词全部替换为 UNK 神经网络中,一般有如下几种处理 UNK 的思路
- 为 UNK 分配一个随机初始化的 embedding,并参与训练
最终得到的 embedding 会有一定的语义信息,但具体好坏未知
- 把 UNK 都初始化成 0 向量,不参与训练
UNK 共享相同的语义信息
- 每次都把 UNK 初始化成一个新的随机向量,不参与训练
常用的方法——因为本身每个 UNK 都不同,随机更符合对 UNK 基于最大熵的估计
How to add new embeddings for unknown words in Tensorflow (training & pre-set for testing) - Stack Overflow
Initializing Out of Vocabulary (OOV) tokens - Stack Overflow
- 基于 Char-Level 的方法
PaperWeekly 第七期 -- 基于Char-level的NMT OOV解决方案