《pandas》专题
-
左联接表pandas出现问题(valueError:您试图合并object和int64列。)[副本]
我有两个列表,我想离开加入一个。 当我尝试这样做时,我会得到同样的错误: 运行dtypes将两个列表标识符作为Object返回。
-
检查string是否在pandas数据帧中
-
使用OR语句筛选Pandas数据帧
ValueError:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()。 所以我知道我没有正确使用or语句,有没有办法做到这一点?
-
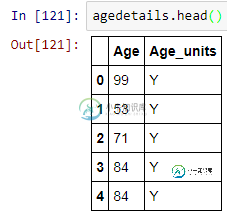 如何将数字数据映射到Pandas dataframe中的类别/仓中
如何将数字数据映射到Pandas dataframe中的类别/仓中我刚刚开始用python编码,我的一般编码技巧相当生疏:(所以请稍有耐心 我有一个熊猫的数据帧: 它大约有300万行。年龄单位有三种:Y、D、W表示年、天、周。任何一个超过1岁的人都有一个Y的年龄单位,我想要的第一个分组是<2Y岁,所以我要测试的年龄单位是Y。 null
-
使用CrossTab Pandas索引DataFrame[重复]
我有两个数据集。 第一个,在市场变量中包含具有以下结构的一般市场趋势: 第二,在心情变量中,每一天都包含一些推文,在这个结构中带有同样的情绪: 所以,我想每天数一数有多少“熊市”和“牛市”情绪。它的工作原理,这是我的代码与注释: 结果如下: 所以它工作得很好,但我不明白为什么我不能访问或索引。 事实上,如果我尝试这样的事情: 我获得: 我错过了什么吗?谢啦
-
使用Python/Pandas按行获取列内容的值
我已经用python确定了我需要在excel文件中获取的行号;使用以下命令: i、 e.打印时,行号显示: 现在,我只是想知道如何使用行号;以获取不同的列值。所以,按行号获取列值。 例如,在下面的示例中: 如何使用行号;i、 e.假设,列“”,以获取“”值?
-
尝试将多个csv文件导入pandas时出错
我试图将一个目录中的几个csv文件读入pandas,并将它们连接到一个大数据帧中,但出现以下错误: 这是我的密码 我不知道为什么它不起作用。我试图用chmod解决这个问题,但一切都变了
-
Python Pandas:将datetime列分组为小时和分钟聚合
这似乎是一个相当直接的前进,但几乎一整天后,我没有找到解决办法。我已经用read_csv加载了我的数据帧,并且很容易地将日期和时间列解析、组合和索引到一个列中,但是现在我希望能够根据小时和分钟分组来重新塑造和执行计算,类似于您可以在excel Pivot中所做的。 我知道如何重新采样到小时或分钟,但它维护与每个小时/分钟相关联的日期部分,而我只想将数据集聚合到小时和分钟,这类似于在excel数据透
-
用时间戳格式的变量替换pandas数据帧上的year
我使用以下代码创建了以下: 但循环什么也不做。我感觉这与变量赋值有关。但我想不出另一种办法来完成这件事。 我试着在每次循环迭代之后分配一个变量,考虑到我在这篇文章中看到的答案。
-
使用pandas[重复]按组获取计数
我有一个熊猫数据框,其中包含如下所示的数据: 所以ID可以在特定月份的任何类下,下个月他的类可能会改变。现在我想做的是,为每个ID获取它在特定类别下的月数,以及它属于的最新类别。像下面这样: 如何在python中实现这一点。有人能帮我吗?另外,由于真实的数据集是巨大的,并且无法手动验证,我如何才能获得属于多个类的ID列表?
-
使用单列转置的Pandas将数据集的矩阵打印到表中
我在Python熊猫中使用电影镜头数据集。我需要打印矩阵的一个制表符分隔文件在下面。方式 我已经通过以下链接 一个数据集非常庞大,将其放在系列中 二-未提及行的转置 三-尝试使用reindex,以便在一列中获得NaN值 四-和也不起作用 我需要输出,因为它显示我的评级和NaN(当未评级)的电影w. r. t.用户。 另外,我不介意使用numpy、crab、recsys、csv或任何其他python
-
如何使用pandas[duplicate]计算特定列的excel行号
我想用熊猫数某列的行数。我有这样的DataFrame: 我想计算列B中的行数,我的代码如下: 但是不管什么我都会把它放在最长列的行号上。 我应该在代码中更改什么来获得列B的行数o,但没有空行?
-
Python Pandas-主DataFrame,想要删除较小DataFrame中的所有列
我有一个数据框('main'),大约有300列。我创建了一个较小的数据帧(“public”),并一直在致力于此。 现在我想从较大的数据框('main')中删除包含在'public'中的列。 我尝试了以下说明: http://pandas.pydata.org/pandas-docs/dev/generated/pandas.DataFrame.drop.html Python Pandas-在一个
-
用dict、preserve和NaNs重新映射pandas列中的值
我有一个字典,看起来像这样: 我想将其应用于数据帧的“col1”列,类似于: 得到: 我怎样才能做到最好?出于某种原因,谷歌搜索与此相关的术语只会向我显示有关如何从dicts生成列的链接,反之亦然:-/
-
pandas reindex()为什么不能正常运行?
从重新索引文档: 使用可选的填充逻辑将DataFrame与新索引一致,将NA/NaN放置在上一个索引中没有值的位置。除非新索引与当前索引等效,并且Cope=False,否则将生成新对象。 因此,我认为我可以通过在适当的位置(!)设置复制=False来重新排序。然而,我似乎得到了一个副本,需要再次将其分配给原始对象。我不想把它分配回去,如果我能避免它的话(原因来自于另一个问题)。 这就是我正在做的: