《pandas》专题
-
将一个数据帧中的值合并到Pandas[duplicate]中的新列中
很抱歉,我一直在做一项基本的任务,但我对python还不熟悉,所以请耐心听我说。 我试图将pandas数据框中的两个值合并到一个单独的列中。我试图将日期值与运动值结合起来。见下面的代码: 我希望最终输出包括新的列“date_sport_concat”w/串联值:
-
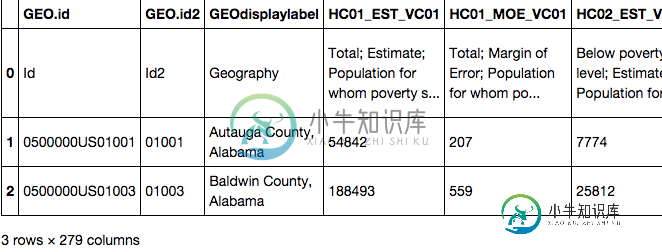 使用. head()方法更改Pandas单元格中打印的文本量[重复]
使用. head()方法更改Pandas单元格中打印的文本量[重复]我想使用方法打印数据集值的全文。 实现这一目标的最佳方式是什么? 下面的行中缩减文本的照片。
-
将Pandas数据帧转换为Spark数据帧时,是否可以将float转换为long?
我有以下两个场景共享的前奏代码: 现在,我想将df转换为pyspark数据帧(
-
我正在尝试使用pandas库在python中创建一个数据帧。但是低于错误[重复]
对象不可调用
-
Pandas在列车测试后显示设置,并显示COPYWARNING[重复]
我试图操纵一个数据帧,它是从Sci Kit Learn的train_test_split操作中收到的。系统提供了以下信息: /usr/local/lib/python3.6/site packages/pandas/core/index.py:179:SettingWithCopyWarning:试图在数据帧中的切片副本上设置值 以下内容会在我的系统上引发警告: 我使用以下版本: python:'
-
Pandas DataFrame: SettingAnd CopyWarning:一个值正试图从DataFrame[复制]的一个片的副本上设置
我知道有很多关于这个警告的帖子,但是我找不到解决我的问题的办法。这是我的密码: 它产生警告: SettingWithCopyWarning:试图在数据帧切片的副本上设置值。尝试改用.loc[row\u indexer,col\u indexer]=value 即使我按照建议更改了代码,我仍然收到此警告?我所需要做的就是转换一列的数据类型。 **备注:**最初该列是具有一个十进制的浮点数类型(例如:
-
在pandas[duplicate]中设置切片值的正确方法
我有一个数据框架:数据。它有列[“名称”、“A”、“B”] 我想做(和工作)的是: 这会将fred行上的列A设置为0。我还做了: 然而,两者都给了我同样的警告: 熊猫想让我怎么做?
-
CSV文件的格式必须如何才能使用pandas Dataframe[duplicate]中的列表数据
我的KBs.csv文件: 然后我读到: 令人惊讶的是,当我试图从列表中的任何位置获取数据时,我得到了以下结果: 如果我尝试构建日期框手册: 这是我正在寻找的行为,csv文件必须如何格式化才能获得它?
-
Pandas:如何获取除与给定列表匹配的列名之外的列名[duplicate]
假设我有一个df: 如何获取所有列名,但不包括名称与,匹配的列名,
-
当尝试从VisualStudio代码运行import pandas时,它抛出了一个ImportError,但在Anaconda(Jupyter笔记本)中运行良好
我曾经在Jupyter笔记本中编写代码,导入熊猫从来没有出现过错误。但是当我在Visual Studio代码中使用相同的代码时, 我收到以下错误。 我尝试搜索几个类似的问题,大多数解决方案要求首先卸载,然后使用以下代码安装NumPy和Pandas, 然而,我遵循了这个解决方案,但问题没有解决。我使用的python版本是Python 3.6。8:: Anaconda,Inc. 如果可以的话,请帮忙。
-
显示股票价格上下波动概率的Pandas级数函数
调整股价天数 假设这张表是熊猫的数据表。有人能帮我写出股票价格上下波动的概率函数吗。例如,股价连续两天上涨的概率是多少。 谢谢,我对python是新手,我已经试着弄清楚这个问题有一段时间了!
-
Pandas read_csv()给出DtypeWarning[重复]
我从数据帧创建了一个文件,如下所示: 数据帧中的数据类型 给出: 当我尝试使用读取新创建的文件时,它会给我错误: Dtype警告:列(5)具有混合类型。在导入时指定 dtype 选项或设置 low_memory=False。交互性=交互性,编译器=编译器,结果=结果) 如何避免此错误?出现此错误是因为我在或时做错了什么吗?
-
如何从大型xlsx文件中加载pandas数据帧的进度条?
来自https://pypi.org/project/tqdm/: 我获取了这段代码并对其进行了编辑,以便从load_excel创建数据帧,而不是使用随机数: 这给了我一个错误,所以我将df.progress_apply改为: 这是最终代码: 这会产生一个进度条,但它实际上并不显示任何进度,而是加载进度条,当操作完成时,它会跳到100%,从而达到目的。 我的问题是:如何让这个进度条工作? prog
-
6.5 GB文件上的Pandas read_csv消耗超过170GB的RAM
我想提出来,只是因为这太奇怪了。也许韦斯有一些想法。该文件非常规则:1100行x~3M列,数据以制表符分隔,仅由整数0、1和2组成。显然这不是预期的。 如果我如下所示预填充数据帧,它会消耗大约26GB的RAM。 系统信息: python 2.7.9 ipython 2.3.1 numpy 1.9.1 熊猫0.15.2 欢迎任何想法。
-
 Pandas/Python在读取3.2 GB文件时内存峰值
Pandas/Python在读取3.2 GB文件时内存峰值因此,我一直在尝试使用pandas<code>read_csv。 所以作为选择 > < li> 我尝试定义< code>dtype以避免将数据作为字符串保存在内存中,但看到了类似的行为。 尝试numpy read csv,以为我会得到一些不同的结果,但肯定是错误的。 试着一行一行地读也遇到了同样的问题,但是真的很慢。 我最近转到了python 3,所以认为那里可能有一些bug,但在python2