《pandas》专题
-
 python - 有pandas想求助大佬?
python - 有pandas想求助大佬?链接 https://gaokao.chsi.com.cn/zsgs/zhangcheng/listVerifedZszc --infoId-4543757002,method-view,schId-1940.dhtml 有大佬知道<div class="content zszc-content UEditor">下的全部内容怎么用xpath获取吗?怎么写为word文档,求大佬告知,谢谢! 上面是
-
python中的pandas统计条件出现的次数?
找出 第1列中的最大值第一次出现的位置, 比方说这个 是索引19中的 27.78 从这个索引19 开始 往下 寻找第1列中所有介于27.78的值区间出现的次数 比方说 从 索引19 开始 往下查询 从索引24到326区间的值小于27.78 把这个区间作为 次数 1 516-519 这个区间作为 2 523-760区间作为3, 769-772 作为4 774-1114 作为5,共出现5次在这个区间的
-
pandas如何根据某列不同值,对其他列用不同的bins和labels进行cut函数切割?
问题描述 有一个DataFrame,我根据某一列‘type’的不同,对‘value’一列进行cut切割分组,赋予不同的分组值。但如果bins和labels数值或者长度不一致,就无法在同一个df里继续操作。 问题出现的环境背景及自己尝试过哪些方法 我尝试用apply的方式去解决,但并没有用好cut函数。 相关代码 报错信息如下: 你期待的结果是什么?实际看到的错误信息又是什么? 我期望type=1的
-
python - pandas中将时间戳转化为字符串时遇到空值无法处理?
在用pandas处理数据时,从数据库中读取某一列为时间戳。 用timestamp.strftime('%Y-%m-%d')将其转化为字符串格式的日期。 但遇到空值会报错,请问该如何高效的实现时间戳转化为字符串,同时对空值进行适当处理。 空值的元素为NaTType 源代码如下:
-
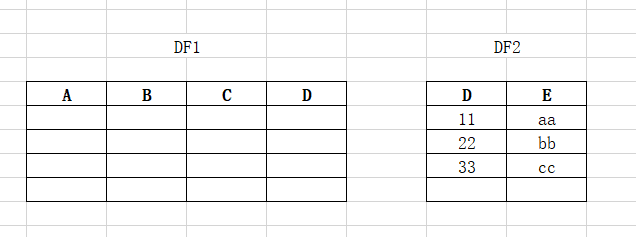 python的pandas不同结构的DF如何整列复制?
python的pandas不同结构的DF如何整列复制?pandas里这种如何操作,df1的结构和df2的结构不一样,我想把df2的某列导入df1的某列下,逐个单元格我能解决,要是需要整列一起复制添加操作,该如何?原因是数据量比较大,逐个复制会慢 效果要如下
-
pandas使用 DataFrame 自身的某一行修改另一行的值,被修改的那一行会被清空?
df1 为: df2 为: 如果想要修改 df2 中第一行的值,使用: df2.loc[df2['A']=='A1', ('B', 'C', 'D')] = df2.loc[df2['A']=='A5', ('B', 'C', 'D')],df2 会变为: 第一行的值全部变为了空值,但是同样的句式,使用 df1 给 df2 的第一行赋值: df2.loc[df2['A']=='A1', ('B',