《pandas》专题
-
将多个csv文件导入pandas并将其合并到一个数据帧中
我有多个csv文件(每个文件包含N行(例如,1000行)和43列)。 我想把文件夹中的几个csv文件读入pandas,并将它们合并到一个数据帧中。 不过我还没能弄明白。 问题是,数据帧的最终输出(即,)将所有列(即43列)合并到代码的一列(见附图)屏幕截图中 选定行和列的示例(文件一) 选择的行和列(文件二)Client_IDClient_NamePointer_of_Bins日期权重C00000
-
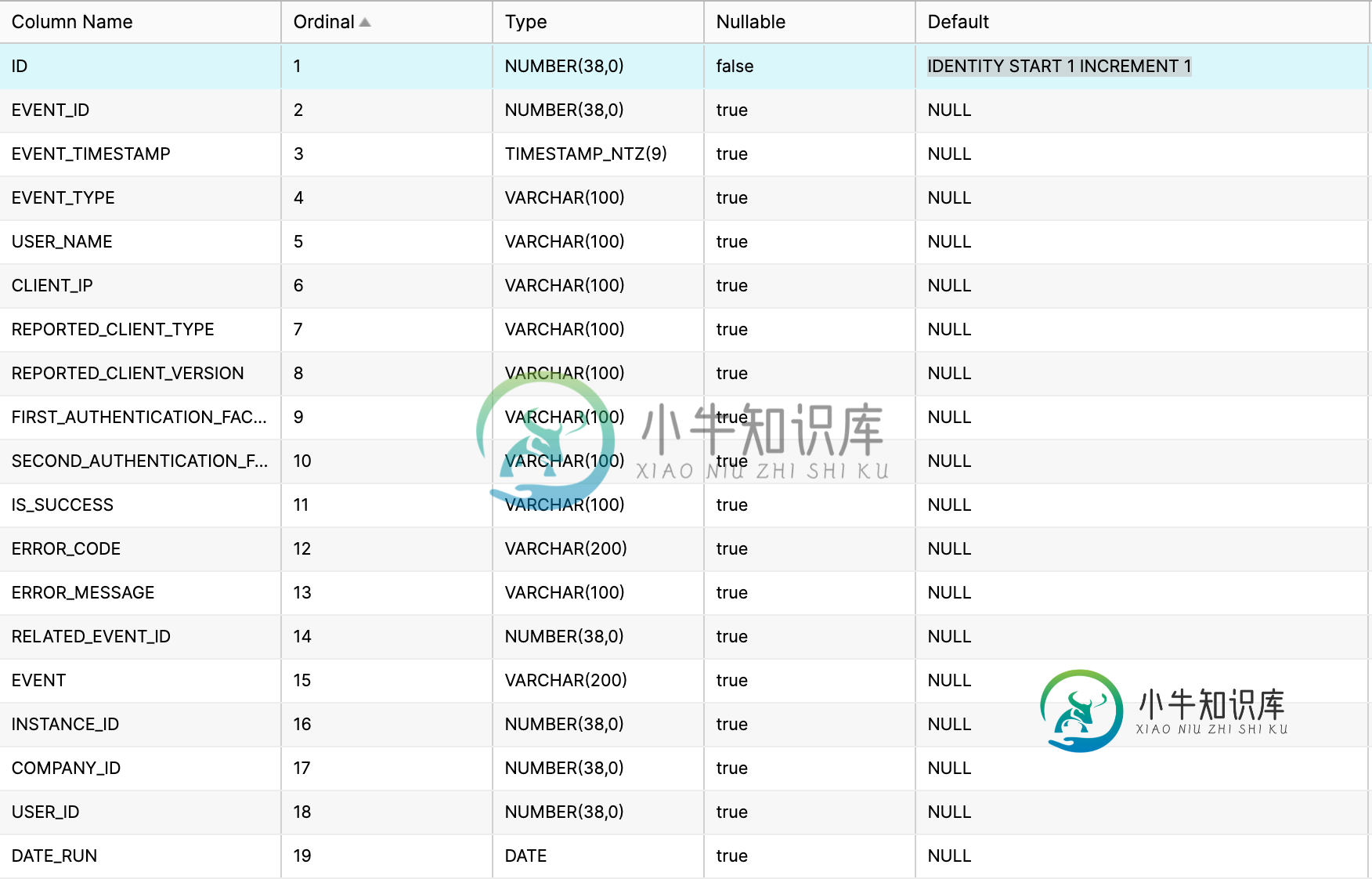 无法使用pandas to_sql()方法将数据插入雪花数据库表
无法使用pandas to_sql()方法将数据插入雪花数据库表我的雪花实例上有一个数据库。数据库有两个模式和。 模式使用SQLAlchemy- 我有一个列的dataframe,如下所述,需要插入到上面创建的表中- 因此,为了插入数据帧,我使用了方法,如下所示- 数据帧。to_sql(table_name,self.engine,index=False,method=pd_writer,if_exists=“append”) 这会给我一个错误- 这个错误是因为
-
PyInstaller与Pandas一起创建超过500 MB的exe
我尝试使用PyInstaller 3.2.1创建一个exe文件,出于测试目的,我尝试为以下代码创建一个exe: 经过相当长的时间(15min+),我完成了大到620 MB的dist文件夹和150 MB的build。我在Windows上使用Python 3.5.2Anaconda定制(64位)。值得注意的是,在dist文件夹中,mkl文件几乎占用了300 MB。我使用'pyinstaller.exe
-
学习 Pandas - 11 - Lesson
英文原文: 11 - Lesson 从多个 Excel 文件中读取数据并且在一个 dataframe 将这些数据合并在一起。 import pandas as pd import matplotlib import os import sys %matplotlib inline print('Python version ' + sys.version) print('Pandas versio
-
学习 Pandas - 10 - Lesson
英文原文: 10 - Lesson 从 DataFrame 到 Excel 从 Excel 到 DataFrame 从 DataFrame 到 JSON 从 JSON 到 DataFrame import pandas as pd import sys print('Python version ' + sys.version) print('Pandas version ' + pd.__ver
-
学习 Pandas - 09 - Lesson
英文原文: 09 - Lesson 从微软的 sql 数据库将数据导出到 csv, excel 或者文本文件中。 # 导入库 import pandas as pd import sys from sqlalchemy import create_engine, MetaData, Table, select print('Python version ' + sys.version) print
-
学习 Pandas - 08 - Lesson
英文原文: 08 - Lesson 如何从微软的 SQL 数据库中抓取数据。 # 导入库 import pandas as pd import sys from sqlalchemy import create_engine, MetaData, Table, select, engine print('Python version ' + sys.version) print('Pandas v
-
学习 Pandas - 07 - Lesson
英文原文: 07 - Lesson 离群值 (Outlier) import pandas as pd import sys print('Python version ' + sys.version) print('Pandas version ' + pd.__version__) Python version 3.6.1 | packaged by conda-forge | (defaul
-
学习 Pandas - 06 - Lesson
英文原文: 06 - Lesson 我们看一下 groupby 这个函数。 # 导入库 import pandas as pd import sys print('Python version ' + sys.version) print('Pandas version ' + pd.__version__) Python version 3.6.1 | packaged by conda-for
-
学习 Pandas - 05 - Lesson
英文原文: 05 - Lesson 我们将快速地看一下 stack 和 unstack 这两个函数。 # 导入库 import pandas as pd import sys print('Python version ' + sys.version) print('Pandas version: ' + pd.__version__) Python version 3.6.1 | package
-
学习 Pandas - 04 - Lesson
英文原文: 04 - Lesson 在这一课,我们将回归一些基本概念。 我们将使用一个比较小的数据集这样你就可以非常容易理解我尝试解释的概念。 我们将添加列,删除列,并且使用不同的方式对数据进行切片(slicing)操作。 Enjoy! # 导入需要的库 import pandas as pd import sys print('Python version ' + sys.version) pr
-
学习 Pandas - 03 - Lesson
英文原文: 03 - Lesson 获取数据 - 我们的数据在一个 Excel 文件中,包含了每一个日期的客户数量。 我们将学习如何读取 Excel 文件的内容并处理其中的数据。 准备数据 - 这组时间序列的数据并不规整而且有重复。 我们的挑战是整理这些数据并且预测下一个年度的客户数。 分析数据 - 我们将使用图形来查看趋势情况和离群点。我们会使用一些内置的计算工具来预测下一年度的客户数。 表现数
-
学习 Pandas - 02 - Lesson
英文原文: 02 - Lesson 创建数据 - 我们从创建自己的数据开始做数据分析。 这避免了阅读这个教程的用户需要去下载任何文件来重现结果。我们将会把这些数据导出到一个文本文件中这样你就可以试着从这个文件中去读取数据。 获取数据 - 我们将学习如何从文本文件中读取数据。 这些数据包含了1880年出生的婴儿数以及他们使用的名字。 准备数据 - 这里我们将简单看一下数据并确保数据是干净的,就是说我
-
学习 Pandas - 01 - Lesson
英文原文: 01 - Lesson 创建数据 - 我们从创建自己的数据开始。 这避免了阅读这个教程的用户需要去下载任何文件来重现结果。我们将会把这些数据导出到一个文本文件中这样你就可以试着从这个文件中去读取数据。 获取数据 - 我们将学习如何从文本文件中读取数据。 这些数据包含了1880年出生的婴儿数以及他们使用的名字。 准备数据 - 这里我们将简单看一下数据并确保数据是干净的,就是说我们将看一下
-
Pandas 秘籍 - 第九章
import pandas as pd import sqlite3 到目前为止,我们只涉及从 CSV 文件中读取数据。 这是一个存储数据的常见方式,但有很多其它方式! Pandas 可以从 HTML,JSON,SQL,Excel(!!!),HDF5,Stata 和其他一些东西中读取数据。 在本章中,我们将讨论从 SQL 数据库读取数据。 您可以使用pd.read_sql函数从 SQL 数据库读取