《pandas》专题
-
pandas to_csv:ascii不能编码字符
我正在尝试将数据帧读写到管道分隔的文件中。有些字符是非罗马字母(`、ç、ñ)。但当我把口音写成ASCII时,它就会断了。 如果将_CSV更改为utf-8编码,则无法正确读取文件: 我的目标是有一个管道分隔的文件,保留重音和特殊字符。 另外,是否有一种简单的方法来计算read_csv是哪一行断开的?现在我不知道如何让它显示我的坏角色(一个或多个)。
-
Python Pandas数据帧到CSV[副本]
你好,我有一个pandas系列的数据文件名“boilerinfo”来自一个API请求,我想创建一个CSV文件的数据。我该怎么做? python可以在这个目录中创建一个CSV文件吗?C:\users\lingbart\documents\python\wb Data
-
将pandas_datareader存储到新的csv文件[重复]
此函数返回以下内容: 我想让我的python脚本可以将股票历史数据保存到一个csv文件中,这样我就可以在以后的项目中使用它。我试着用csv模块做这件事,但是找不到任何与我正在尝试做的事情相匹配的东西。是否有任何方法可以将这些数据存储到一个新的csv文件中,而不需要一个现有的文件。
-
将选择的Pandas数据帧保存到csv[重复]
假设我创建了一个熊猫数据帧 现在我正在运行一个像这样的选择 问题是:我如何将这个结果导出/保存到一个CSV文件? 预先默许 a
-
Python。从Pandas列中提取字符串的最后一位数字
我想在一个新变量中存储“UserId”的最后一位数字(这样的UserId是字符串类型)。 我想出了这个,但它是一个很长的df,需要很长时间。关于如何优化/避免循环有什么建议吗?
-
根据 pandas 中的另一个值更改一个值
我试图用Python复制我的Stata代码,我被指向熊猫的方向。然而,我很难思考如何处理数据。 假设我想遍历列标题“ID”中的所有值。如果该ID与一个特定的数字匹配,那么我想更改两个相应的值FirstName和LastName。 在Stata,它看起来像这样: 因此,这将替换 FirstName 中与 ID == 103 到 Matt 的值对应的所有值。 在熊猫身上,我正在尝试这样的东西 不知道该
-
 用Pandas dataframe中的值注释heatmap
用Pandas dataframe中的值注释heatmap我想用从dataframe传递到下面函数中的值来注释heatmap。我已经查看了matplotlib.text,但无法以HeatMap中所需的方式从dataframe中获取值。我已经在下面粘贴了生成heatmap的函数,之后是我的dataframe和heatmap调用的输出。我想在HeatMap中的每个单元格的中心绘制我的dataframe中的每个值。 用于生成热图的函数: Herre是我的dat
-
使用pandas数据帧更新红移失败,字符串索引超出范围
我试图用psycopg2和psycopg2.extras更新一个红移表,但是失败了,出现以下错误。有人能帮忙解决这个错误吗? 我有一个23列的数据帧,我正在尝试在AWS Lambda中更新如下。与数据库的连接成功,但更新失败: 新错误 我的输入行如下 我看到数据“50017651”的每个值都被传递为“5”、“0”、“0”……。我不知道是什么原因? 我从StackOverflow推荐了这2个URL来
-
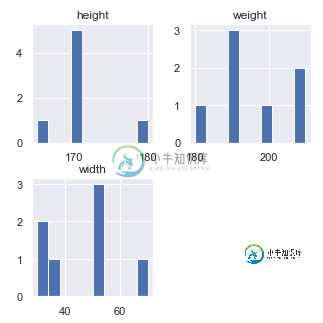 如何将条形图与plt或pandas直方图中的刻度标签对齐(绘制多列时)
如何将条形图与plt或pandas直方图中的刻度标签对齐(绘制多列时)我已经开始使用python解决工作中的许多数据问题,数据集总是略有不同。我试图探索使用内置pandas函数绘制数据的更有效方法,而不是单独写出每个列的代码并编辑格式以获得更好的结果。 背景:我正在使用Jupyter笔记本并查看直方图,其中的值都是唯一的整数。 问题:当用一个函数(例如df)绘制多列数据时,我希望xtick标签与直方图条的中心对齐。hist()一次获取所有列的直方图。 有人知道这是否
-
将数组和元组元素转换为Pandas数据帧中的列[重复]
我有一个Pandas数据框架,看起来像这样(有两行的示例): 我需要将所有内容解构为单个标量列,如下所示: 我不太关心新的列名;重要的是将行排列成如上所示的平面向量。 我如何才能做到这一点?
-
如何在pandas data-frame中将包含列表的列转换为单独的列?[重复]
我有一个数据框,其中一列包含一个列表。 输出应如下所示: 我已经尝试了我在这里找到的这些选项,但不起作用。
-
从pandas列[duplicate]中的列表创建多个列
我有一个数据框架,我想从其中一列的列表中创建5列 示例: 请注意,这里很少有列表少于5列,对于这些列,请在该位置插入NAN。
-
Pandas:使用另一列的max()值映射列
我有一个类似的例子,类似于我的另一个问题Pandas:在多个列上使用字典映射列,但是现在,我想不直接使用列“category”的max()值,而是间接使用它来填充第四列“category_name”中的None与问题1中的情况相同,但是增加了一个包含字符串的列。 此处“类别”列始终是填充的,而“类别名称”列有一些缺失值: 我想再一次用值填充无/南,我想使用的逻辑是:使用列“类别”中最大值的行的列“
-
如何在pandas groupby中对数据帧行进行列表分组
我有一个pandas数据帧像: 我想按第一列进行分组,并将第二列作为行中的列表:
-
pandas.dataframe.columns.values.ToList()与pandas.dataframe.columns.ToList()相同吗
稍稍反省一下,似乎表明值只是一些实现细节,只是一个数字。ndarray