《pandas》专题
-
从另一列比较python pandas中缺少的值
我有一个pandas数据帧,它由两个带值的列组成。有些值丢失了,我想创建第三列,以标记两列中是否都有丢失的值,或者是否有一列被填充。我不知道如何做这件事,因为我是新来的,如果你能提供任何帮助,我将不胜感激
-
基于Pandas中的多个列筛选并显示所有重复行[重复]
给定一个数据集如下: 我需要根据Pandas中的列和过滤和显示所有重复的行。 通过下面的代码,我得到: 出: 但我希望结果如下: 我怎么能在熊猫里做到这一点?
-
使用Pandas获取大Excel文件的重复行[重复]
我有一个至少 600,00 行的 excel 文件(大小各不相同)。我想用熊猫获取特定列的所有重复项。 这是我到目前为止尝试过的: 然而,我得到的结果不是重复的,我不确定我可能做错了什么。有没有更有效的方法来解决这个问题?
-
Pandas Dataframe按列排序[重复]
我有一个Python Pandas数据帧。df有2列,我想按第二列对df进行排序。 我想按角度排序df(升序)。
-
如何从一列中对pandas dataframe进行排序
如您所见,月份不按日历顺序排列。所以我创建了第二列来获取每个月(1-12)对应的月份号。从那里,我如何根据日历月份的顺序对此数据帧进行排序?
-
FileNotFoundError:[Errno 2]没有这样的文件或目录Pandas
我正试图用python中的pd.read_excel读取我的excel文件。但是ıam得到这个错误消息=FileNotFoundError:[Errno 2]没有这样的文件或目录 我把我的excel文件和python文件放在同一个地方。图1图2
-
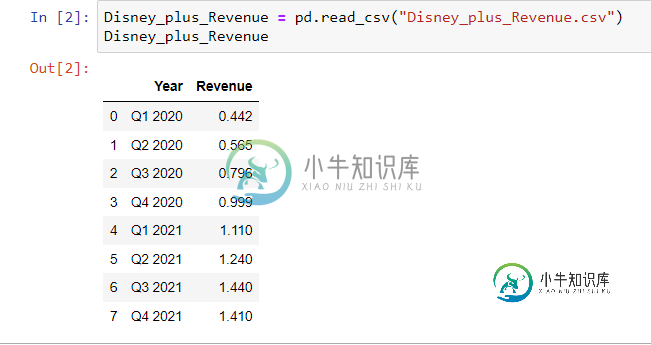 使用 Pandas 将季度业绩转换为年度业绩的建议
使用 Pandas 将季度业绩转换为年度业绩的建议因此,我有2020年第一季度至2021第四季度迪士尼加收入的季度数据。 错误-
-
连接pandas中的数据帧
有没有一种方法可以将下面的两个数据流连接起来,这样: 我将有一个带有标题的新数据帧: 时间戳调整的关闭reportedEPS estimatedEPS 并且reportedEPS和estimatedEPS将根据以下值保持不变: 时间戳:1月1日至3月31日,4月1日至6月30日,7月1日至9月30日,10月1日至12月31日? 2个数据流: https://gyazo.com/38B50A3D7E
-
Alpha Vantage API时间序列盘中外国股票转化为pandas df
我需要将ADR和ORD对(以及它们之间的货币)的股票价格数据编译成Pandas数据帧。我刚开始使用Alpha Vantage API,它可以很好地获取在美国上市的股票价格(以分钟为单位)和汇率,但我还没有弄清楚如何获取在国外上市的股票价格(ORD)。我几乎肯定这只是一个ticker.exchange类型的输入,但这似乎不起作用。 下面的代码是我在木星笔记本中使用的,用于获取帝亚吉欧PLC的ADR。
-
当从pandas数据帧转换为html时,如何在html中显示完整的(未截断的)数据帧信息?
我使用函数将pandas数据帧转换为html输出。当我将其保存到一个单独的html文件中时,该文件将显示截断的输出。 例如,在“我的文本”列中, 将显示 这部电影是一部出色的作品… 而不是 这部电影是解构这一时期盛行的复杂社会情绪的一次极好的努力。 这种呈现对于屏幕友好格式的大量pandas dataframe是很好的,但是我需要一个html文件来显示包含在dataframe中的完整的表格数据,也
-
Pandas字符串,替换没有for循环的多个单词[重复]
在Pandas df中,我有大约130万个字符串(代表用户向IT帮助台发送邮件时的需求)。我还有一系列29813个名称,我想从这些字符串中删除,这样我只剩下描述问题的单词。这里有一个数据的小例子-它可以工作,但需要太长时间。我正在寻找一种更有效的方法来实现这一结果: 输入: 输出: 我已经努力寻找答案很长一段时间了:如果我因为缺乏经验而错过了某个地方,请温柔地告诉我! 非常感谢:)
-
如何用pandas和sqlalchemy在雪花中插入变量或数组数据类型
我有一个Pandas dataframe,其中包含几个列,这些列是列表。我希望将它们作为数据类型插入到雪花表中。
-
Pandas文本文件到CSV
对理解这一差异的任何帮助都是感激的。
-
Python Pandas在不聚合的情况下透视包含重复值的多个字符串列
我有以下数据框架,并希望以这样的方式进行数据透视:将列< code>Imprv_Attribute转换为每个键的单个列,并且值应为< code>Imprv_Attr_Desc。我还需要< code>Imprv_Attr_Units信息,对于每个新创建的列,例如< code >浴室的< code>Imprv_Attr_Units应该有自己的名为< code >浴室_Imprv_Attr_Units的
-
如何在 pandas 中使用数据帧中的值作为列名,并将列名用作数据帧中的值
我有一个这样的数据框: 输出应如下所示 有没有一种方法可以在没有循环的情况下获得这个结果,一些可移植的代码来获得这个输出?