《pandas》专题
-
map、applymap与Pandas应用方法的差异
你能用基本的例子告诉我什么时候使用这些矢量化方法吗? 我看到是方法,而其余的是方法。不过,我对和方法感到困惑。为什么我们有两种方法用于将函数应用于DataFrame?同样,简单的例子说明用法将是伟大的!
-
Pandas-在applymap中检索每个元素的行和列名称
到目前为止,我求助于使用以下(以下),但我发现它笨拙和缓慢
-
将Pandas列的列表拆分为多列
如何将这列列表拆分为两列? 期望的结果:
-
如何在python中使用Pandas dataframe按顺序创建和保存csv文件
我有一个简单的代码,它将一个pandas数据文件保存到一个csv文件中。到目前为止,它是通过覆盖文件名来工作的,所以每次我运行它时,它只是用一个同名的新文件替换旧文件。是否可以保存此数据文件,但让它按顺序创建新文件,即如果目录中已经有一个名为“filename1”的文件,则创建一个名为“filename2”的新文件,这样原始文件中的数据就不会丢失了?
-
如何在for循环中追加pandas dataframe中的行?
我试过熊猫串连或类似,但似乎没有效果。你知道吗?谢了。
-
如何在python中使用pandas将词典列表转换为dataframe
我有一个字典列表:},[{'name':'jack','id':93,'value':9500}] 我想把它转换成一个数据文件: 如何在Python中做到这一点。 我试过了,但不起作用
-
使用MySQL创建数据库并用SQLAlchemy和Pandas填充它
我使用MySQl Work Bench制作了一个表模式,并希望用我丢弃的tweet填充它。到目前为止,所有外键和主键都已设置。但我无法让SQLalchemy使用模式并填充它。我使用以下命令行进行了尝试:我缩短了表创建的代码,使其只与“user”部分匹配。我得到的错误是
-
对pandas数据帧中的某些行组求和
我有一个pandas dataframe,我想在其中求和某些不规则间隔的日期之间的值。举个例子,我有这样的东西: 并且我知道这些总和的截止日期是2021-03-01、2021-03-04、2021-03-05,所以我想要截止日期和直到(但不包括)下一个截止日期产生的所有小部件的总和。所有不是截止日期的日期的值都为0。 这将产生如下所示的新列。 我怎么能在熊猫内部做到这一点呢?
-
python dataframe pandas将列从n(int)删除到n(int)
所以我有超过1000000列 但我只需要前10000列,基本上将列从n(int)降至n(int)。谢谢!
-
仅包括一个id有2个标志的id(PANDAS)
我有以下名为的数据帧,我想将该数据帧子集为只有列有1和0的ID。下面的示例将删除=1,因为它只有1(而不是0)。 预期产出: 我怎么能这么做?我想一个团体会有帮助?但不确定如何正式地进行
-
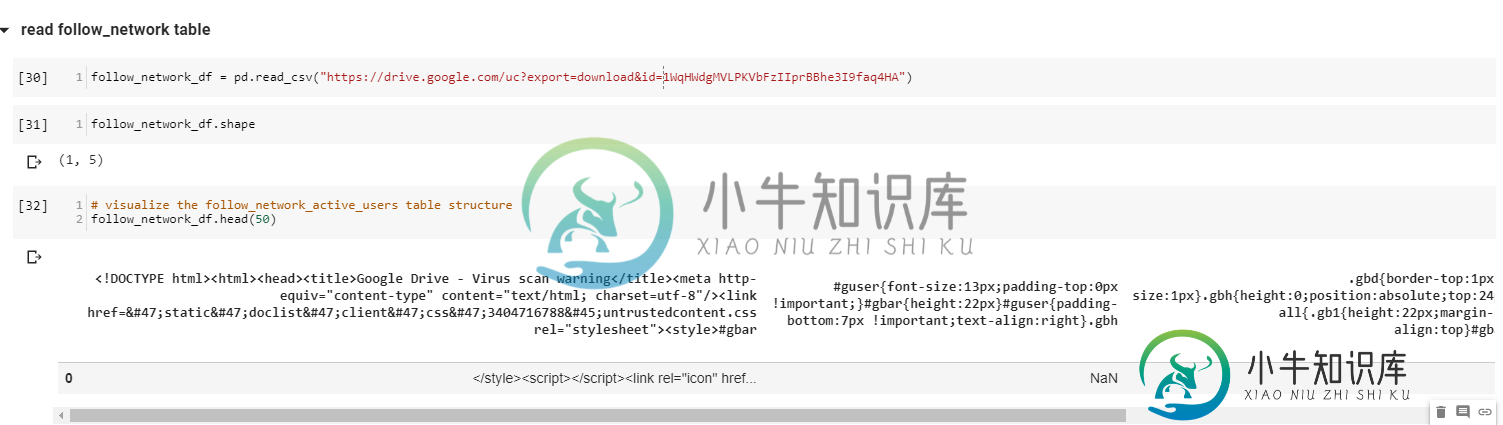 Python中的pandas.read_csv在Google Drive文件中有1000万行的大型csv文件上
Python中的pandas.read_csv在Google Drive文件中有1000万行的大型csv文件上我从Google Bigquery中提取了一个2列1000万行的。csv文件。 我已经在本地下载了一个大小为170MB的.csv文件,然后将文件上传到Google Drive,我想使用pandas.read_csv()函数将其读入我的Jupyter笔记本中的pandas DataFrame。 这是我使用的代码,有我想读的特定文件ID。
-
向Google BigQuery高效地编写Pandas dataframe
null 备选方案2比备选方案1耗时更长(使用和):
-
向Google云存储或BigQuery编写一个Pandas DataFrame
您好,感谢您的时间和考虑。我正在谷歌云平台/DataLab中开发一个Jupyter笔记本。我已经创建了一个Pandas DataFrame,并希望将此DataFrame写到Google Cloud Storage(GCS)和/或BigQuery中。我在GCS中有一个bucket,并通过以下代码创建了以下对象: 我尝试了基于Google Datalab文档的各种方法,但仍然失败。谢谢
-
Python Pandas-从数据帧创建一个数组或矩阵进行乘法
我发现了这个先前的职位,它让我接近。如何将数据帧的列和行的子集转换成数字数组 但是,我需要迭代数据帧,并为“a”中每个正确匹配的值创建一个从列“b”到列“j”的3x3数组(或矩阵),而不是根据第三列中的值创建两列的单个数组(或数组)。 我想要的是两个独立的数组,每个一个 我尝试了以下操作,但收到了一个非常难看的错误。该代码是基于原始帖子的尝试。 这是错误- () ----中的IndexingErr
-
如何将Parquet文件读入Pandas DataFrame?
如何在不设置集群计算基础设施(如Hadoop或Spark)的情况下将大小适中的Parket数据集读取到内存中的Pandas DataFrame中?这只是我想在笔记本电脑上使用简单的Python脚本在内存中读取的适度数据。数据不驻留在HDFS上。它要么在本地文件系统上,要么可能在S3中。我不想启动和配置其他服务,如Hadoop、Hive或Spark。 我原以为Blaze/Odo会使这成为可能:Odo