
Python中的pandas.read_csv在Google Drive文件中有1000万行的大型csv文件上

我从Google Bigquery中提取了一个2列1000万行的。csv文件。
我已经在本地下载了一个大小为170MB的.csv文件,然后将文件上传到Google Drive,我想使用pandas.read_csv()函数将其读入我的Jupyter笔记本中的pandas DataFrame。
这是我使用的代码,有我想读的特定文件ID。
# read into pandasDF from .csv stored on Google Drive.
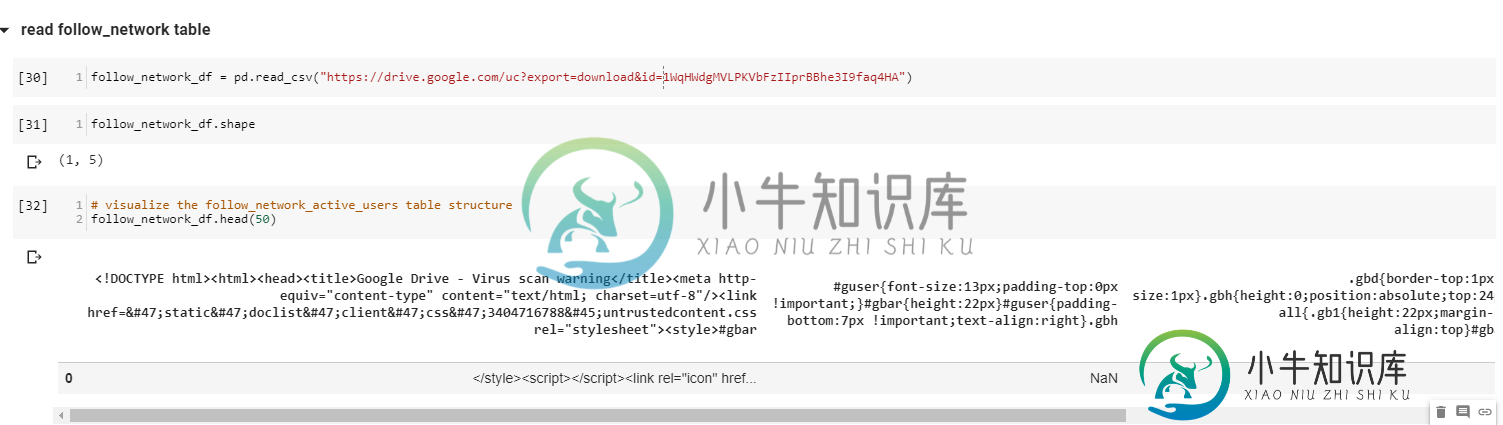
follow_network_df = pd.read_csv("https://drive.google.com/uc?export=download&id=1WqHWdgMVLPKVbFzIIprBBhe3I9faq4HA")
# another csv file of 40Mb.
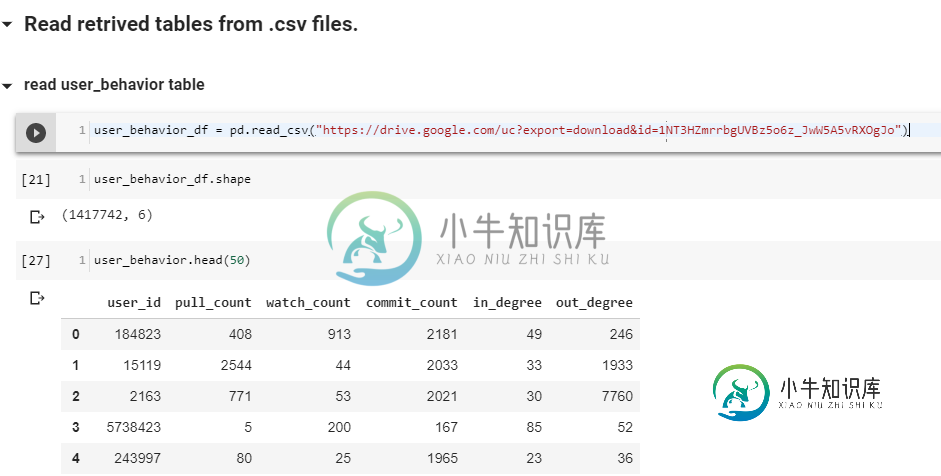
user_behavior_df = pd.read_csv("https://drive.google.com/uc?export=download&id=1NT3HZmrrbgUVBz5o6z_JwW5A5vRXOgJo")
共有1个答案

问题是第一个文件太大,Google Drive无法扫描病毒,所以显示的是一个用户提示,而不是实际的文件。如果访问第一个文件的链接,您可以看到这一点。
我会说单击用户提示并使用下面的url和pd.read_csv。
-
由于多值字段和维度使用报价,csv读取器读取此文件失败。我的函数(上面代码中的函数f)如果那个逗号在属于同一字段的两个数据之间,就用分号代替逗号,如果那个引号是维度的东西,就用'inch'代替。
-
问题内容: 我正在使用Python脚本处理大型CSV文件(数以10M行的GB数)。 这些文件具有不同的行长,并且无法完全加载到内存中进行分析。 每行由脚本中的一个函数分别处理。分析一个文件大约需要20分钟,并且看来磁盘访问速度不是问题,而是处理/函数调用。 代码看起来像这样(非常简单)。实际的代码使用Class结构,但这是相似的: 鉴于计算需要共享的数据结构,使用多核在Python中并行运行分析的
-
我正在处理非常大的.csv文件,并且正在尝试查找文件中的行数以及其他事情,例如解析为json等。 我的问题是如何克服csv库的限制,因为我不断收到以下错误。 我提供了一个在python3中工作的示例程序,它将返回csv文件中的行数。 但是,当运行1.5GB csv文件时,我仍然会收到这个错误。 在这个问题上所做的任何工作都是非常值得赞赏的。谢谢!
-
问题内容: 我正在尝试将非常大的json文件转换为csv。我已经能够将这种类型的小文件转换为10条记录(例如)csv文件。但是,当尝试转换大文件(csv文件中的50000行的数量)时,它不起作用。数据是通过curl命令创建的,其中- o指向要创建的json文件。输出的文件中没有换行符。csv文件将使用csv.DictWriter()编写,并且(其中数据是json文件输入)的格式为 然后,我遍历行和
-
问题内容: 我可能犯了一个愚蠢的错误,但我找不到它在哪里。我想计算csv文件中的行数。我写了这个,显然没有用:我有应该是400。干杯。 问题答案: 保存列表后,如果文件指针已到达文件末尾,则您尝试读取两次文件。
-
我可能犯了一个愚蠢的错误,但我找不到它在哪里。我想计算我的csv文件中的行数。我写了这个,显然不起作用:我有,而它应该是400。干杯。