《pandas》专题
-
pandas数据帧中多列转换为字符串
-
如何将pandas系列或索引转换为Numpy数组?[副本]
您知道如何将DataFrame的索引或列作为NumPy数组或python列表获取吗?
-
有没有一种方法使用Pyhon Pandas库只选择列标签而不选择任何行?[副本]
谢谢你的帮助。
-
如何在Pandas数据帧的列中用零替换NaN值?
当我尝试将函数应用于Amount列时,我得到以下错误: 我试过使用Math模块中的.isnan应用函数我试过使用pandas.replace属性我试过使用pandas0.9中的.sparse data属性我也试过使用函数中的if NaN==NaN语句。我还看了这篇文章,如何在R数据帧中用0替换NA值?同时查看一些其他文章。我试过的所有方法都不起作用,或者不认识南。如有任何提示或解决方案,将不胜感激
-
如何从Python Pandas系列或数据框中的行中删除省略号,当长行/宽列被截断时显示?[重复]
当我创作以下熊猫系列时: 我得到的结果是: 我怎样才能得到一个没有省略号的系列呢
-
带有lambda函数的Pandas.filter()方法[duplicate]
我正在尝试理解Pandas中的.filter()方法。我不确定为什么下面的代码不起作用: 我得到:
-
如何在pandas dataframe中删除关于特定组/数据的行(数据)?[副本]
在下面的pandas dataframe中,在下面,我只想要ID 1的数据,并删除其余的数据。如何实现?
-
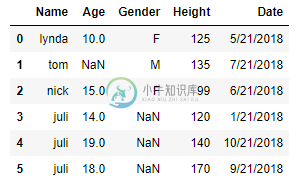 Pandas:基于列中的空值拆分数据帧[duplicate]
Pandas:基于列中的空值拆分数据帧[duplicate]我有一个数据帧如下所示: 如何根据性别的np值转换dataframe? 我想要原始数据帧df被拆分为df1(姓名,年龄,性别,高度,日期),它将具有性别的值(df的前3行)
-
 如果Pandas dataframe[duplicate]中的特定列中存在空值,则删除行
如果Pandas dataframe[duplicate]中的特定列中存在空值,则删除行我刚认识蟒蛇熊猫。需要一些关于删除有空值的几行的帮助。在屏幕截图中,我需要使用python Pandas删除中的行。
-
如何在Pandas Dataframe[duplicate]中迭代行
我有这样的数据: 我想创建一个新的列,将成本转换为美元。只是提一下,有12种货币。 这是我所写的: 使用这段代码,我得到了一个错误。
-
什么时候我应该(不)希望在代码中使用pandas apply()?
我看到过许多关于堆栈溢出问题的答案,这些问题涉及使用Pandas方法。我也看到用户在他们下面评论说“速度慢,应该避免”。 如果是如此糟糕,那么为什么它会出现在API中? 如何和何时使我的代码免费? 是否有任何情况下是好的(优于其他可能的解决方案)?
-
pandas迭代行有性能问题吗?
我注意到使用来自Pandas的迭代行时性能非常差。 这是别人经历过的事情吗?它是特定于迭代行的吗?对于一定大小的数据(我正在处理200万-300万行),是否应该避免使用这个函数? GitHub上的讨论使我相信它是在数据帧中混合dtype时引起的,然而下面的简单示例显示,即使使用一个dtype(float64)时也会出现这种情况。这在我的计算机上需要36秒: 为什么像apply这样的矢量化操作要快得
-
如何用不同的标记分隔符连接多个Pandas数据帧列?
我正在尝试用不同的令牌连接多个Pandas DataFrame列。 例如,我的数据集如下所示: 我不想修改原始的DataFrame,所以创建了两个新的DataFrame: 有一个问题,我面临,它是添加<2>最后,但我想要像上面的输出,而且这不是熊猫的方式来做这个任务,我如何使它更有效率?
-
pandas python如何计算数据帧中的记录数或行数
对熊猫来说显然是新鲜事物。如何简单地计算数据帧中的记录数。 我本以为像这样简单的东西就能做到,但我似乎甚至在搜索中都找不到答案...可能是因为它太简单了。 上面的代码实际上只是打印整个df
-
从列名列表中删除pandas dataframe中的列的快速方法是什么[重复]
我试图找出使用列名列表在df中删除列的最快方法。这是一种花哨的特征约简技术。这就是我现在正在使用的,而且是永远的。任何建议都非常感谢。