
Pandas:基于列中的空值拆分数据帧[duplicate]

我有一个数据帧如下所示:
data = [['lynda', 10,'F',125,'5/21/2018'],['tom', np.nan,'M',135,'7/21/2018'], ['nick', 15,'F',99,'6/21/2018'], ['juli', 14,np.nan,120,'1/21/2018'],['juli', 19,np.nan,140,'10/21/2018'],['juli', 18,np.nan,170,'9/21/2018']]
df = pd.DataFrame(data, columns = ['Name', 'Age','Gender','Height','Date'])
df
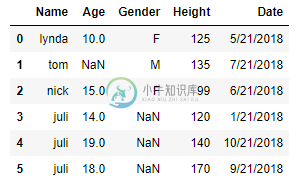
如何根据性别的np值转换dataframe?
我想要原始数据帧df被拆分为df1(姓名,年龄,性别,高度,日期),它将具有性别的值(df的前3行)
共有1个答案

这是一种方法:
import pandas as pd
import numpy as np
data = [['lynda', 10,'F',125,'5/21/2018'],['tom', np.nan,'M',135,'7/21/2018'], ['nick', 15,'F',99,'6/21/2018'], ['juli', 14,np.nan,120,'1/21/2018'],['juli', 19,np.nan,140,'10/21/2018'],['juli', 18,np.nan,170,'9/21/2018']]
df = pd.DataFrame(data, columns = ['Name', 'Age','Gender','Height','Date'])
df2 = df[df['Gender'].notnull()].drop("Gender", axis=1)
print(df2)
输出:
Name Age Height Date
0 lynda 10.0 125 5/21/2018
1 tom NaN 135 7/21/2018
2 nick 15.0 99 6/21/2018
-
我有一个像下面这样的DataFrame,标识符作为现有DateIndex顶部的列。 我的目标是为除id之外的每一列(a和B)创建一个新的子DataFrames,其中dateIndex作为单个索引,id(foo,bar)作为列名。预期产出如下所示:
-
我有列。 如何根据值将其拆分为2? 第一个将包含
-
我有两个数据帧df1和df2。df1就像一个具有以下值的字典 df2具有以下值: 我想基于df1数据帧中的,将df2拆分为3个新的数据帧。 日期,TLRA_权益栏应位于数据框 预期产出: > 数据帧 消费者,非周期性数据帧 请让我知道如何有效地做。我想做的是连接列名,例如,然后根据列名的前半部分分割数据帧。 代码: 但这很复杂。需要更好的解决方案。
-
我有下面的spark数据框架。 我必须将上面的数据帧列拆分为多个列,如下所示。 我尝试使用分隔符进行拆分;和限制。但是它也将主题拆分为不同的列。姓名和年龄被组合在一起成一列。我要求所有主题在一列中,只有姓名和年龄在单独的列中。 这在Pyspark有可能实现吗?
-
我有两个熊猫数据框 步骤2:对于flag=1的行,AA_new将计算为var1(来自df2)*组“A”和val“AA”的df1的'cal1'值*组“A”和val“AA”的df1的'cal2'值,类似地,AB_new将计算为var1(来自df2)*组“A”和val“AB”的df1的'cal1'值*组“A”和val“AB”的df1的'cal2'值 我的预期输出如下所示: 以下基于其他stackflow
-
我有一个数据集,我想根据该行的2或列值从数据框中删除行。例如-我有关于美国所有电视节目的数据帧,我需要根据电视节目的季节和剧集删除电视节目的特定行。就像我需要删除高谭市电视台的行,但只删除包含第四季和第十集的行。 如果我能在这方面得到帮助,我将不胜感激。