《pandas》专题
-
将Pandas GroupBy输出从Series转换为DataFrame
-
使用Pandas/Beautiful Shoum(而不是selenium哪个慢?)刮表数据,BS实现不起作用
我试图在这个网站上搜索web数据,我能够访问数据的唯一方法是遍历表的行,将它们添加到列表中(然后将它们添加到pandas数据框架中/写入csv),然后单击下一页并重复这个过程[每次搜索大约有50页,我的程序进行100+次搜索]。它非常慢/效率低,我想知道是否有一种方法可以使用pandas或Beautive soup高效地添加所有数据,而不是遍历每一行/每列。
-
使用索引设置pandas数据帧中特定单元格的值
拿到这个了 然后我要为特定单元格赋值,例如为行“C”和列“X”赋值。我已经料到会有这样的结果: 使用此代码:
-
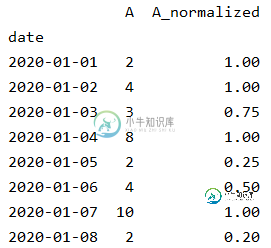 按到目前为止观察到的最大值对pandas dataframe列进行规范化
按到目前为止观察到的最大值对pandas dataframe列进行规范化我有一个带有时间索引的pandas dataframe,希望通过观察到该日期和时间的最大值来规范化列的每一行。 (一个可能的解决方案是遍历行,对过去的行进行子集,然后除以最大值[1,2,3],但这样做效率很低)
-
如何使用Pandas计算值在每列(每列)中出现的次数?
有没有办法用熊猫来计算某个值在每一列中出现的次数? 数据= pd。DataFrame({'userID':['Luis ',' Mike ',' Harvey'],' category1':[True,False,True],' category2': [True,True,False],' category3':[False,False,False]}) 假设我想计算每个类别中“真”布尔值的数量
-
Pandas:在多列上使用字典映射列
我有一个数据帧,其中一列中具有值。我想将此 值替换为其他列的相同组合的“类别”的最大值。 示例:熊猫数据帧 我想将3中的值替换为唯一组合(1.2列组)此列的max()值。预期结果如下所示: 我尝试过的:我把1。2.列(“公司产品”)获取3的最大值()。列建立一个字典'类别'。(基于GroupBy结果到列表字典的思想) 我得到这个判决(显示每个组合的最大类别值): 现在我想用字典中每个组合的最大值替
-
Python pandas:显示基于唯一值的行[重复]
我是一个新的Python学习者,我不知道该怎么做。 假设我有一个这样的数据框: 我只想为每个标题选择行,查看的小时数最多,结果如下: 提前感谢您。
-
如何向没有列的pandas数据帧添加列?[副本]
我有一个数据框架,其中有2列。第一列似乎没有列名,第二列名为< code>Speed。 这是一个MRE: 这是我执行打印语句时的输出: 这是我想要的输出:
-
在pandas[duplicate]中操作整个列时获取数组的第一个元素
我目前正在做一个熊猫的数据框架。我正在重新格式化数据,以便在运行分析时更容易理解。列中的默认数据是一个字符串,类似于< code> something | something。例如< code >事故|可修复损坏。 我想在dataframe中创建两个新列,将字符串拆分为两个不同的字符串,并将拆分字符串的不同部分分配给不同的列。 这是预期的输出: 这是我目前拥有的代码: 它当前正在获取第一条记录,并
-
如何最好地将包含列表或元组的Pandas列提取为多列[重复]
我不小心用一个到错误副本的链接关闭了这个问题。下面是正确的:熊猫将列表的一列拆分成多列。 假设我有一个数据帧,其中一列是列表(长度已知且相同)或元组,例如: ie: 我想将“vals”中的值附加到单独的命名列中。我可以通过迭代行来笨拙地做到这一点: 结果如愿以偿: 有没有更整洁(矢量化)的方式?我尝试使用[]但是我得到一个错误。 给出: 看起来Pandas试图将[]操作符应用于series/dat
-
我可以将spark dataframe作为参数发送到pandas UDF吗
提前感谢!!!
-
如何计算Pandas中滚动窗口中的波动率(标准差)
-
 如何在PySpark中使用pandas轴等价来删除列而不是行?
如何在PySpark中使用pandas轴等价来删除列而不是行?我有一个spark dataframe,如下所示 我想做的是删除包含超过80%的值的列? 我试过下面的东西,但不起作用
-
如何将Pandas绘图注释更改为整数?
我一直在使用这篇文章中的代码行来注释条形图中列顶部的总值,但我似乎无法弄清楚如何在没有小数位数的情况下获得整数结果? 有什么想法吗?
-
在向Pandas数据框条形图添加值标签时遇到问题[duplicate]
我一直在努力将一个简单的东西作为值标签添加到Pandas数据框条形图中。我已经查看了20多个线程(其中这三个最有帮助-如何在matplotlib中的条形图中的列上显示文本?、matplotlib高级条形图和Python熊猫/matplotlib在条形图列上注释标签,但什么都不起作用。 我的数据一点也不复杂。数据帧结构为: 年份是数据帧的索引。 我正在寻找的表示很简单。所有产品的堆叠条形图,只有“总