
按到目前为止观察到的最大值对pandas dataframe列进行规范化

我有一个带有时间索引的pandas dataframe,希望通过观察到该日期和时间的最大值来规范化列的每一行。
# an example input df
rng = pd.date_range('2020-01-01', periods=8)
a_lst = [2, 4, 3, 8, 2, 4, 10, 2]
df = pd.DataFrame({'date': rng, 'A': a_lst})
df.set_index('date', inplace=True, drop=True)
(一个可能的解决方案是遍历行,对过去的行进行子集,然后除以最大值[1,2,3],但这样做效率很低)
共有1个答案

您正在查看Cummax:
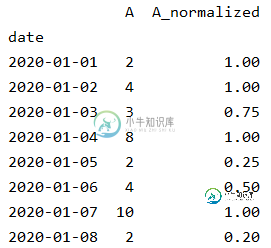
df['A_normalized'] = df['A']/df['A'].cummax()
产出:
A A_normalized
date
2020-01-01 2 1.00
2020-01-02 4 1.00
2020-01-03 3 0.75
2020-01-04 8 1.00
2020-01-05 2 0.25
2020-01-06 4 0.50
2020-01-07 10 1.00
2020-01-08 2 0.20
-
问题内容: 我有一张表格,其中存储了发生的消息。通常有一个消息“ A”,有时A被单个消息“ B”分隔。现在,我想对这些值进行分组,以便能够对它们进行分析,例如找到最长的“ A”条纹或“ A”条纹的分布。 我已经尝试了COUNT-OVER查询,但仍在为每条消息计数。 这是我的示例数据: 我想要以下输出 问题答案: 那很有趣:) 这是结果集: 该查询可能更短,但我以这种方式发布,因此您可以看到正在发生
-
我尝试使用这个实现ViewModel。但观察者从未被调用。 基本上,这个应用程序在SAMPLE_URL上发出网络请求,将JSON转换为列表,并通过BookView显示列表。这个应用程序在没有ViewModel的情况下工作得很好。使用ViewModel,应用程序会运行,但Observer从未被调用,也没有显示任何数据。 我在这里做错了什么? BookActivity类: BookViewModel类
-
问题内容: 给定汽车清单(),我可以这样做: 有没有办法我可以从一个到一个序列? 像没有参数的东西 问题答案: 您可以这样映射到: 请注意,flatMapping可能不会保留源可观察的顺序。如果订单对您很重要,请使用。
-
我正在用一个库编程,我不知道代码,只知道方法,我不能修改它。我试着制作一个“航班”的表格视图,但我不知道如何为每个航班命名(或ID)。有人能帮我吗?谢谢此处有一些代码:
-
我想创建一个可观察的,将按需发射项目,这意味着我想要一个单一的订阅可观察的,并通知可观察的,我需要基于我的请求的新项目。 这就是我使用Publishsubject所做的: } 下面是活动类中的用法: 所以基本上我订阅了Flowable对象,并将Bitmap对象传递给我的Subject类,通过Flowable继续并返回结果,这个解决方案是正确的还是会产生一些内存泄漏? 是否有更好的解决方案将对象发送
-
让我们考虑下面的示例代码: 在函数gude()中,将创建一个新的observable,它将发出哈希值,该哈希值的前n个前导值设置为零。一个观察者订阅了那个可观察的,并立即取消订阅。让我们假设函数createHashWithNLeadingZeroes()需要相当长的时间来生成响应。 我想这里发生了以下事情: (1) 创建了一个新的可观察对象,描述可观察对象行为的函数被内部存储在属性_subscri