《pandas》专题
-
 Python 和 Pandas 数据分析教程
Python 和 Pandas 数据分析教程大家好,欢迎阅读 Python 和 Pandas 数据分析系列教程。 Pandas 是一个 Python 模块,Python 是我们要使用的编程语言。Pandas 模块是一个高性能,高效率,高水平的数据分析库。
-
 Pandas Cookbook 秘籍
Pandas Cookbook 秘籍您可以使用 read_csv 函数从 CSV 文件读取数据。 默认情况下,它假定字段以逗号分隔。我们将从蒙特利尔(Montréal)寻找一些骑自行车的数据。 这是原始页面(法语),但它已经包含在此仓库中。 我们使用的是 2012 年的数据。
-
 十分钟搞定 pandas
十分钟搞定 pandas官方网站上《10 Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对 pandas 的一个简单的介绍,详细的介绍请参考:秘籍 。习惯上,我们会按下面格式引入所需要的包。
-
Pandas
Python Data Analysis Library 或 pandas 是连接 SciPy 和 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Comma-separated values (CSV) 文件表示在有关各方之间分发数据的最常见的方法之一。Pandas 提供了一种优化库功能来读写多种
-
Sklearn-pandas
Sklearn-pandas既可以视为一个通用型的机器学习工具包,也可是视为一些特定算法的实现。它在具体的机器学习任务中主要充当支持者的角色。 这里所谓支持者的角色,按照其官网的解释即是说:Sklearn-pandas在Scikit-Learn和pandas之间提供了一个互通的桥梁(这一点从项目的名称也能看出)。Scikit-Learn上文已经提过,这里pandas是指一个开源的基于Python实
-
pandas-profiling
Pandas Profiling Documentation | Slack | Stack Overflow | Latest changelog Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great but a little basic for serious
-
pandashells
pandashells 可以将 Python 的数据栈引入到 shell 提示符,即把可表现的、精确的 shell pipeline 工作流和 Python 数据栈的统计和可视化工具结合到一起。 一组命令行工具与表格数据协同工作 轻松在 CSV 读/写数据,或者空出分隔格式 可对表格式数据迅速聚集,加入和汇总 计算描述性数据 执行频谱分解和线性回归 创建可视化数据,可以被保存到图像,或使用一个本地
-
Pandas AI
Pandas AI 是一个 Python 库,它为流行的 Python 数据分析和操作工具 Pandas 库添加了生成人工智能功能,旨在与 Pandas 结合使用,而不是它的替代品。 Demo 在浏览器中试用 PandasAI: 安装 pip install pandasai 用法 PandasAI 旨在与 Pandas 结合使用。它使 Pandas 具有对话性,允许以 Pandas DataFr
-
 pandas - 如何在导出到Excel时处理Pandas DataFrame的多级列索引,避免空白行和列?
pandas - 如何在导出到Excel时处理Pandas DataFrame的多级列索引,避免空白行和列?数据:数据df是dataframe类型,并且包含多个dataframe类型子数据,他们的列名都是两级,将df导出到Excel的默认工作簿中后,发现表中第三行和第一列都是空白的,其实就是dataframe的列索引和行索引。 问题:导出数据后,再加载Excel删去行、列索引,发现表中多级列名中的第一级列名合并单元格都失效了,并且只显示第一个子数据的第一级列名 代码: 使用 to_excel() 方法将
-
pandas - 想要通过excel表格操作网页实现点击和填写的需求,需要定位点击按钮,等待,然后选择,填写。需要同时操作多个网页,不同电脑上定位不同,怎么能可复制?
想要通过excel表格操作网页实现点击和填写的需求,需要定位点击按钮,等待,然后选择,填写。需要同时操作多个网页,不同电脑上定位不同,难以复制。 读取excel用的pandas或openpyxl,定位点击按钮用的pyautogui,
-
python - 一个简单的问题,不借助pandas,二维列表如何快速分组?
一个简单的问题,不借助pandas,二维列表如何快速分组? [['A',33],['A',0],['A',12],['A',3],['B',3],['B',0],['B',77],['C',1],['C',2],['C',5],['C',0],['C',11],['C',19]] 或者 [['A', 'A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'C',
-
为什么pandas iloc()中使用df.iloc[[i][0]]会导致特定行为?
pandas中iloc()函数的参数问题 我刚刚开始学习pandas,在一份代码中出现了df.iloc[[1][0]](df是shape为(60935, 54)的pd.DataFrame数据类型)的调用,从代码上下文上理解df.iloc[[1][0]]应该是df的一行,但是应该如何理解[[1][0]]呢?为什么iloc[]中的参数会允许接受两个相邻的列表?iloc[]内部是如何处理的?这显然不是对
-
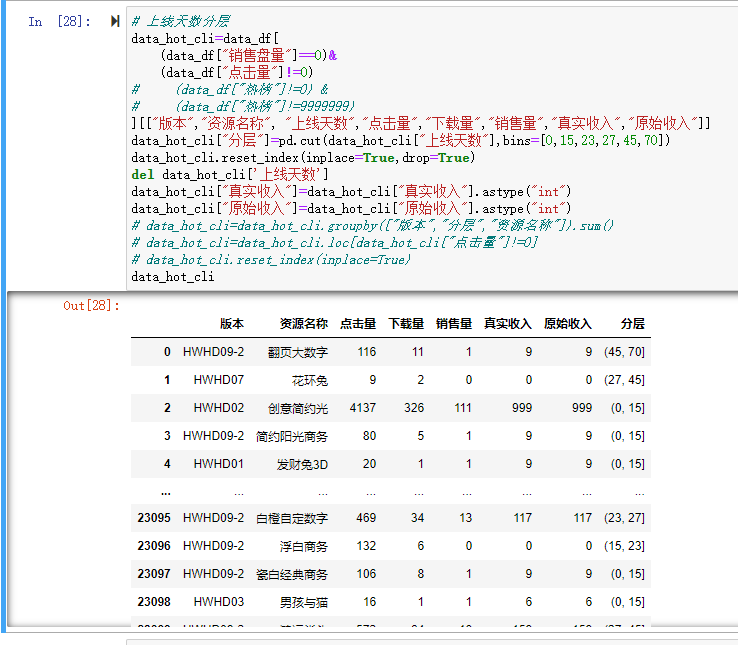 python - pandas对筛选后的数据groupby结果是筛选前数据,筛选无效?
python - pandas对筛选后的数据groupby结果是筛选前数据,筛选无效?这一组数据在进行groupby前已经完成筛选,但进行groupby聚合后的结果显示是利用未筛选的数据进行的聚合,就像下面的结果,在groupby前已经完成点击量非0过滤,但最后仍存在含0的资源,询问chatGPT给的方案是可能用索引前的数据进行的聚合,重置索引后仍无法解决,请教大牛是否遇到过类似的问题,虽然可以在聚合后重新进行filter过滤,但这个问题搞得很焦灼 代码源文本
-
python - pandas怎么修改旧表?
pandas只会创造新表吗?不能直接修改旧表?
-
python - Python pandas怎么在末尾一行插入数据?
第一行是2023-9-5的数据,在2023-9-6插入一行数据