《pandas》专题
-
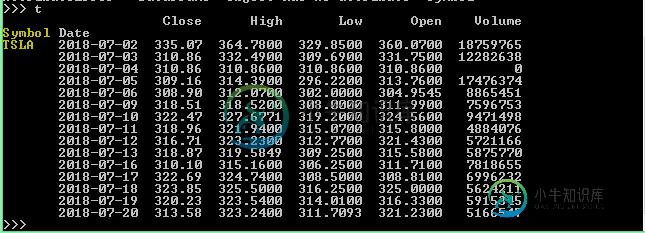 从pandas数据帧中获取符号[重复]
从pandas数据帧中获取符号[重复] -
从pandas移动到dask,以利用所有本地cpu内核
最近,我偶然发现了http://dask.pydata.org/en/latest/,因为我有一些pandas代码,它只运行在一个核心上,我想知道如何利用我的其他CPU核心。dask是否可以很好地使用所有(本地)CPU内核?如果是,它与熊猫的相容性如何? 我可以用多个CPU来处理熊猫吗?到目前为止,我读到关于发布GIL的消息,但这一切似乎相当复杂。
-
pandas中的大型持久数据帧
作为一个长期的SAS用户,我正在探索切换到python和pandas。 然而,在今天运行一些测试时,我很惊讶python在尝试一个128MB的csv文件时内存耗尽。它大约有200,000行和200列,大部分是数字数据。 使用SAS,我可以将csv文件导入SAS数据集,并且它可以和我的硬盘一样大。 中有类似的内容吗? 我经常处理大文件,没有访问分布式计算网络的权限。
-
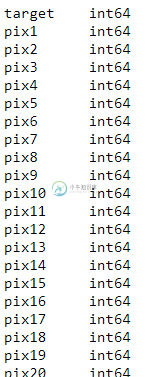 Pandas CSV导入中二进制变量减少内存占用的最佳数据类型
Pandas CSV导入中二进制变量减少内存占用的最佳数据类型我的原始文件为训练目的有25GB。我的机器有64GB的内存。用默认选项导入数据总是以“内存错误”告终,因此在阅读了一些帖子后,我发现最好的选项是定义所有的数据类型。 为了回答这个问题,我使用了100.7MB的CSV文件(它是从https://pjreddie.com/media/files/mnist_train.CSV获取的mnist数据集) 当我用Pandas中的默认选项导入时: 我的内存使用
-
Python Pandas用户警告:排序,因为非串联轴不对齐
我正在做一些代码练习,并在获得用户警告的同时应用数据帧合并 /usr/lib64/python2.7/site packages/pandas/core/frame.py:6201:FutureWarning:Sorting,因为非连接轴未对齐。熊猫的未来版本将默认更改为“不排序”。要接受将来的行为,请传递“sort=True”。要保留当前行为并使警告静音,请传递sort=False 在这几行代码
-
序列化包含pandas数据帧的字典(Python)
我有一个包含几个pandas数据帧(由键标识)的dict,任何有效序列化(和干净加载)它的建议。下面是结构(一个pprint显示输出)。每个DICT['method_x_']['meas_x_']都是一个pandas数据帧。我们的目标是保存数据流,以便使用一些特定的绘图选项进行进一步的绘图。 {“Method1”: {“Meas1”: “方法2”: {“Meas1”: “Meas2”:
-
在巨大的TSV文件中,pandas read_csv dtype对大多数整数字符串列的推断不一致
我有一个以制表符分隔的文件,其中有一列应该解释为字符串,但许多条目都是整数。对于小文件,read_csv在看到一些非整数值后会正确地将列解释为字符串,但是对于较大的文件,这就不起作用了: 输出: 我很确定这是一个bug,但是希望能够使用引用来解决这个问题,尽管添加quoting=csv.quote_nonnumeric用于读写并不能解决这个问题。理想情况下,我可以通过引用我的字符串数据来解决这一问
-
导入时忽略Python-Pandas数据帧\
-
将通过Pandas/PyTables写入的大型hdf5数据集转换为vaex
我有一个非常大的数据集,我通过append以块形式写入hdf5,如下所示: 数据太大,无法加载到一个DataFrame中,因此我想尝试使用vaex进行进一步处理。不过有几件事我不太明白。 由于vaex在hdf5中使用了不同于pandas/pytables(VOTable)的表示形式,我想知道如何在这两种格式之间进行转换。我尝试将数据块加载到pandas中,将其转换为vaex数据帧,然后将其存储,但
-
使用Pandas将2个命令列表与公共元素合并
所以我有两个指令列表.. 目标是获得如下所示的最终数据集: 由于我的数据集是针对某一年所有12个月的大量学生的,所以我使用Pandas进行数据采集。这就是我的工作方式: 首先,使用name键将这两个列表组合为一个数据帧。 很明显,最终的数据集并不完全是我想要的。我得到的不是两个月都分开的两个数据集,而是四个月分开的数据集。我该如何解决这个问题呢?我更愿意在熊猫自身中修复它,而不是使用这个最终的输出
-
将大型数据集加载到Pandas Python中
我想从InstaCart https://www.InstaCart.com/datasets/grocery-shopping-2017加载大型.csv(3.4百万行,20.6万用户)开源数据集 基本上,我在将orders.csv加载到Pandas数据帧中时遇到了麻烦。我想学习将大文件加载到Pandas/Python中的最佳实践。
-
Pandas concat函数给出ValueError:传递值的形状为{passed},索引暗示{implied}
concat线给出 raise VALUERROR(f“传递值的形状为{传递},索引暗示{隐含}”)VALUERROR:传递值的形状为(18585,6),索引暗示(12390,6) 我不明白为什么上面写着18585。还有其他连接方法吗?请帮忙。 编辑:我想我找到了问题所在。 打印结果给了我以下信息 印刷原理图 结果Df最初是通过附加两个Df获得的 行号不是从0到12390的延续,而是从0到6194
-
我使用pandas库用python编写代码,没有错误,也没有结果。你能帮我吗,结果必须是一个图[closed]
代码:
-
Pandas Python程序在Python3、3.8上运行,但不是在3.6上运行
每当我运行命令python3.6 Check.py时,我都会得到以下错误:, 熊猫误差 回溯(最后一次调用):文件“/usr/lib/python3/dist-packages/pandas/_-libs/init.py”,第30行,从pandas开始。_-libs导入哈希表为_-hashtable,lib为_-lib,tslib为_-tslib文件“/usr/lib/python3/dist-p
-
删除Pandas中列名的前缀
如何更改pandas数据框的列标签: 到