
Pandas CSV导入中二进制变量减少内存占用的最佳数据类型

我的原始文件为训练目的有25GB。我的机器有64GB的内存。用默认选项导入数据总是以“内存错误”告终,因此在阅读了一些帖子后,我发现最好的选项是定义所有的数据类型。
为了回答这个问题,我使用了100.7MB的CSV文件(它是从https://pjreddie.com/media/files/mnist_train.CSV获取的mnist数据集)
当我用Pandas中的默认选项导入时:
keys = ['pix{}'.format(x) for x in range(1, 785)]
data = pd.read_csv('C:/Users/UI378020/Desktop/mnist_train.csv', header=None, names = ['target'] + keys)
# you can also use directly the data from the internet
#data = pd.read_csv('https://pjreddie.com/media/files/mnist_train.csv',
# header=None, names = ['target'] + keys)
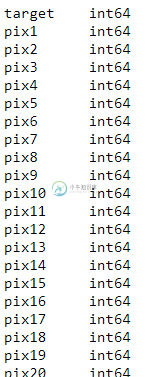
data.dtypes
import sys
sys.getsizeof(data)/1000000
values = [np.int8 for x in range(1, 785)]
data = pd.read_csv('C:/Users/UI378020/Desktop/mnist_train.csv', header=None, names = ['target'] + keys,
dtype = dict(zip(keys, values)))
我的内存使用量减少到:
47.520104
我的问题是,对于二进制变量,什么是更好的数据类型,以减少更多的大小?
共有1个答案

参考这里的NumPy文档,在数组/列表中分配项的最小可能选择是NumPy的“int8”dtype,它在C中具有相应的“int8_t”。
对于二进制列表/类似列表的对象,“uint8”、“int8”、“byte”或“bool”类型将为一个1字节的项目生成相同的大小(分配)。
-
问题内容: 我想问你如何减少Spring框架的RAM占用量。 我创建了一个简单的helloworld应用来演示该问题。只有两个类和context.xml文件: -主要方法课 -用于模拟某些“工作”的类(无穷循环中的printig Hello) 仅包含以下内容: 测试类仅包含称为的方法,构造后会调用: 我准备了两种情况,在这两种情况下,方法仅包含一行。 在第一种情况下,主要方法是这样做的: App在
-
问题内容: 我正在尝试将几个文件加载到内存中。这些文件具有以下3种格式之一: 字符串TAB int 字符串TAB浮动 int TAB浮点数。 的确,它们是ngram静态文件,以防解决方案的出现。例如: 目前,我正在执行的伪代码是 令我惊讶的是,尽管磁盘中文件的总大小约为21 mb,但是将其加载到内存中时,该过程将占用120-180 mb的内存!(整个python应用程序不会将其他任何数据加载到内存
-
我在c中有一个存储字节的结构,如下所示: 我需要通过节俭将这些数据发送到用C编写的远程服务。我发现了三种方法如何将此结构映射到节俭idl: > 使用二进制键入: 以类型存储数据: 最好的办法是什么?
-
我正在使用spring boot开发客户端应用程序。在运行spring boot应用程序(使用完全可执行的jar)时,x64服务器的内存占用约为190M,x86服务器的内存占用约为110M。 我的jvm选项是(-xmx64m-xms64m-xx:maxpermsize=64m-server),为什么在x64服务器中,内存占用这么大?如何将内存使用量降低到150M以下? 多谢了。
-
问题内容: 有没有一种类型或方式以二进制级别在oracle中存储数据。我对表中的dml和pl / sql的操作都感兴趣。 当前所有二进制元素都以varchar2(1000)=‘11111 …0000.1111’的形式存储,但是操作和数据存储量很大,因此需要一些优化解决方案。如果此数据可以二进制格式存储,则将需要1000/8字节(具有>700mn条记录) 可能的解决方案是对这些操作使用某种Java
-
用途: 在字符串与二进制数据之间相互转换 打包和拆包 import struct import binascii values = (1, 'ab'.encode('utf-8'), 2.7) s = struct.Struct('I 2s f') packed_data = s.pack(*values) print('Original values:', values) print('Fo