《pandas》专题
-
 Python Pandas-缺少必需的依赖项['Numpy'] 1
Python Pandas-缺少必需的依赖项['Numpy'] 1从昨天开始,我尝试在anaconda上导入包时出现以下错误: 我尝试过卸载Anaconda和Python,切换到Python 2.7,但没有任何效果仍然是相同的错误,下面是我得到的代码: 非常感谢您的帮助,谢谢!
-
 用pandas识别统计异常值:groupby和reduce行到不同的数据帧中
用pandas识别统计异常值:groupby和reduce行到不同的数据帧中我试图理解如何在数据帧组中识别统计异常值。我需要根据条件对行进行分组,然后将这些分组减少为一行,然后在所有减少的行中找到异常值。 使用这样的数据集,我想根据不同的条件进行分组,例如: 在这一步中,我将每个数据帧缩减为一行,为此,我有一些想法,一个简单的方法是获取每个数据帧的平均值,但问题是有些列是分类的,有些是连续的,为了获取整个数据帧的平均值,我将分类列转换为freq count列: 对于每个d
-
Pandas数据帧的迭代[重复]
在编程方面,我是一个新手,特别是熊猫。我也很抱歉,我问了一个已经在SF上提到的问题:我并不真正理解这个问题的现有答案。可能重复,但这个答案对新手来说很容易理解,如果不太全面的话。
-
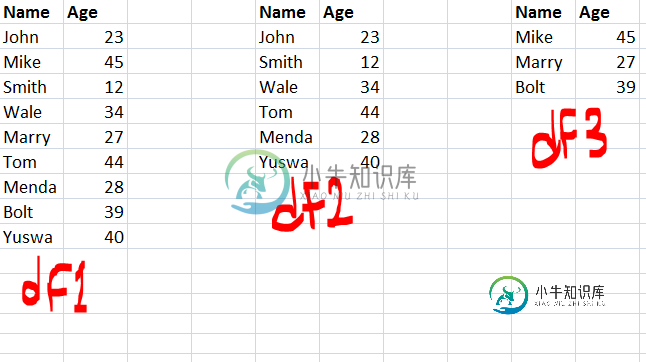 Python Pandas-查找两个数据帧之间的差异
Python Pandas-查找两个数据帧之间的差异我有两个数据帧df1和df2,其中df2是df1的子集。我如何获得一个新的数据帧(df3),它是两个数据帧之间的差值? 换句话说,一个数据帧,它包含了df1中所有的行/列,而不是DF2中的行/列?
-
如何从pandas框架中的特定列中提取numpy数组并将其堆叠为单个numpy数组[重复]
我有一个像这样的熊猫架。 我想从帧中提取向量,像这样的矩阵。
-
获取Pandas DataFrame的行索引值作为列表?[重复]
当我试图找到这个答案时,我可能使用了糟糕的搜索词。现在,在索引DataFrame之前,我以这种方式在列中获得一个值列表... …然后我将在列上设置索引。这似乎是浪费的一步。在索引上尝试上述操作时,我得到一个键错误。 如何获取索引中的值(单个和多个)并将其放入列表或元组列表中?
-
Pandas DataFrame列到列表[重复]
我从一个列中提取数据的子集,基于满足另一个列中的条件。 我可以得到正确的值,但它在pandas.core.frame.DataFrame中。如何将其转换为列表?
-
将多个csv文件导入pandas并连接到一个数据帧中
我想从一个目录中读取几个csv文件到pandas中,并将它们连接到一个大的数据帧中。不过我还没弄明白。以下是我目前掌握的情况: 我想我需要在for循环中得到一些帮助???
-
如果单元格有2个单词,则只提取第一个单词,如果单元格有3个单词,则提取2个第一个单词-PANDAS/REGEX
在我的数据框架中,有一列名为“teams”。它包括城市和球队名称。我想把这个城市拉进另一个纵队。这是数据帧:数据帧示例 我可以使用正则表达式轻松提取列: 然而,在“名称”栏中,对于纽约尼克斯队,它只给了我“New”的值,我想得到“New York”: 结果 那么,我该怎么做呢?如果单元格有2个单词,我该如何从开头只提取一个单词?如果单元格有3个单词,我该如何使用正则表达式从中提取2个单词?
-
从Dataframe-Pandas中所有列的列名中删除最后两个字符
我加入两个数据帧(a,b)与相同的列/列名使用用户ID键,并在加入时,我必须给后缀字符,以便它被创建。以下是我使用的命令, 如果我不使用这个后缀,我就会出错。但是我不想更改列名,因为这会在运行其他分析时导致问题。所以我想从结果数据帧的所有列名中删除这个“_1”字符。有人能给我一个有效的方法来删除数据框中所有列名称的最后两个字符吗? 谢谢
-
根据字典重命名PANDAS中的列
我有一个dataframe,我想根据另一个我计划用作字典的dataframe重命名这些列。例如,我的第一个数据帧是: 作为我想用作字典的第二个数据帧: 我希望得到的结果如下: 最初,我想将第一个数据帧重塑为长格式,然后与字典数据帧合并,然后重塑为宽格式。然而,我认为这是相当低效的,所以我想使用一种更有效的方法(如果存在的话)。非常感谢你的帮助。
-
Pandas.DataFrame.rename方法中的参数“index”是什么?
Pandas DataFrame有一个重命名方法,它使用一个名为“index”的参数。我不理解文档中对参数的描述:DataFrame.rename 具体来说,我使用它就像文档网页上的示例: 我理解结果,但我不明白为什么要设置。 参数用于什么?为什么示例设置了?
-
如何使用布尔掩码将pandas数据帧中的“任意字符串”替换为nan?
我有一个227x4的数据帧与国家名称和数值清洁(wrangle?)。 以下是数据帧的抽象: 如何将所有列中的字符串值替换为,而不涉及国家名称? 我尝试使用布尔掩码: 我看了几个与我有关的问题([1]、[2]、[3]、[4]、[5]、[6]、[7]、[8]),但找不到一个回答我所关心的问题。
-
如何使用pandas更改数据帧中的特定行值?[副本]
这里我附上了我的数据框。我正试图改变行的具体值。但我没有成功。任何线索将不胜感激。 我的数据帧图像
-
如何在pandas(python)[复制]中用其他值替换NAN
例如,我想把'NAN'换成'dog'和'cat'。像从1-30'楠'应该换成'dog',从40-100'应该换成'cat'。我应该怎么做