
Python Pandas-查找两个数据帧之间的差异

我有两个数据帧df1和df2,其中df2是df1的子集。我如何获得一个新的数据帧(df3),它是两个数据帧之间的差值?
换句话说,一个数据帧,它包含了df1中所有的行/列,而不是DF2中的行/列?
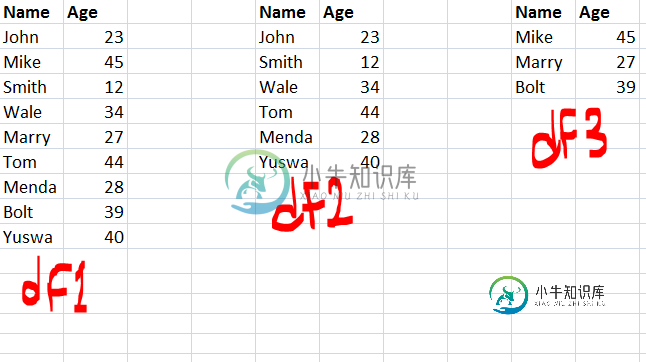
共有1个答案

通过使用drop_duplicates
pd.concat([df1,df2]).drop_duplicates(keep=False)
更新:
上面的方法仅适用于它们本身没有重复的数据流,例如
df1=pd.DataFrame({'A':[1,2,3,3],'B':[2,3,4,4]})
df2=pd.DataFrame({'A':[1],'B':[2]})
它将输出如下所示,这是错误的
错误输出:
pd.concat([df1, df2]).drop_duplicates(keep=False)
Out[655]:
A B
1 2 3
正确输出
Out[656]:
A B
1 2 3
2 3 4
3 3 4
df1[~df1.apply(tuple,1).isin(df2.apply(tuple,1))]
Out[657]:
A B
1 2 3
2 3 4
3 3 4
方法2:合并与指示符
df1.merge(df2,indicator = True, how='left').loc[lambda x : x['_merge']!='both']
Out[421]:
A B _merge
1 2 3 left_only
2 3 4 left_only
3 3 4 left_only
-
我在dataframe中总共有100列。我试图比较两个数据帧,并找到列名不匹配的记录。我得到了以下代码的输出,但当我运行100列的代码时,作业被中止。 我正在为SCD类型2增量进程错误查找执行此操作。 请建议任何其他方式。
-
我需要按行比较两个不同大小的数据帧,并打印出不匹配的行。让我们看以下两个例子: 在df2上按行打印并打印出不在df1中的行的最有效方法是什么。 重要提示:我不希望有行: 包括在差异中: 我已经尝试过了:逐行比较两个不同长度的数据帧,为每行添加相等值的列,比较两个数据帧,并排输出它们的差异 但是这些和我的问题不匹配。
-
我想找出使用内部联接联接时两个数据帧的列值之间的差异。 df1有10列,即。key 1, key 2 现在我想比较连接的df3中已经存在的两个数据帧df1和df2的对应列。 现在我对zip(df1.columns,df2.columns)中的每个x,y进行循环,并存储在list < code > un match list . append((df3 . select(df1 . x,df2.y)
-
问题内容: 关闭。 这个问题是题外话。它当前不接受答案。 想要改善这个问题吗? 更新问题,使它成为Stack Overflow的主题。 9年前关闭。 改善这个问题 我正在尝试将更改从DatabaseA复制到DatabaseB,但是我不完全知道这些更改是什么。 是否有一个SQL脚本可以找到数据库之间不同的对象,然后生成一个脚本来更新DatabaseB以匹配DatabaseA? 我正在使用SQL 20
-
问题内容: 我有以下两个数组。我想要这两个数组之间的区别。也就是说,如何找到两个数组都不存在的值? 问题答案: 注意: 这个答案将返回的值是不存在的,它不会返回值不在。
-
我们从外部来源发送两个日期作为字符串。然后我们计算日期之间的差异,看看它们工作了多少小时。 由于时间的变化,一年两次——我们的计算会出错。我们使用Java。你怎么解决这样的问题? 这两个日期以字符串形式出现在一个文件中,格式如下。“2019-10-07上午11:07”