
用pandas识别统计异常值:groupby和reduce行到不同的数据帧中

我试图理解如何在数据帧组中识别统计异常值。我需要根据条件对行进行分组,然后将这些分组减少为一行,然后在所有减少的行中找到异常值。
df = pd.DataFrame({'X0': {0: 1, 1: 1, 2: 1, 3: 1, 4: 0, 5: 1, 6: 1, 7: 1, 8: 0, 9: 1, 10: 0, 11: 1, 12: 0, 13: 1, 14: 1, 15: 1, 16: 0, 17: 0, 18: 0, 19: 1, 20: 0, 21: 1, 22: 1, 23: 1, 24: 1, 25: 0, 26: 1, 27: 1, 28: 1, 29: 1, 30: 0, 31: 1, 32: 0, 33: 1, 34: 0, 35: 1, 36: 1, 37: 0, 38: 1, 39: 0, 40: 1, 41: 0, 42: 1, 43: 0, 44: 0, 45: 1, 46: 1, 47: 1, 48: 1, 49: 0}, 'X1': {0: -0.037112917323895135, 1: -0.10487134240202785, 2: -1.2231079338781112, 3: -1.4422747724730558, 4: 1.1903093112171788, 5: 0.16264503017608584, 6: 0.09575885513801816, 7: -0.04065753545650327, 8: 0.9811627656097434, 9: -1.0895731715012618, 10: 1.2771663221280398, 11: 0.20642136730493899, 12: 1.4502341066082816, 13: 0.393823431298906, 14: 0.3451716634317143, 15: 0.4709902758164765, 16: 0.9982956103799087, 17: 1.189077916373609, 18: 0.9234439359961105, 19: -1.3255857892440723, 20: 1.2098373846214483, 21: -1.0264301443260604, 22: -1.2752711175444444, 23: -1.1775143284917524, 24: 0.259560479915767, 25: 0.8873566136283076, 26: 0.21516987874467863, 27: -1.1480968752611762, 28: -1.1903434754082, 29: 0.16553499639585526, 30: -0.027563846470247143, 31: 0.19474819789386086, 32: 1.5332001783034717, 33: -1.4746621814990961, 34: 0.9251147862187328, 35: 0.009242841373200278, 36: -1.4155649459675044, 37: 1.1476020465617858, 38: -1.3349528515873126, 39: 1.3090049690691499, 40: -1.0159692538569027, 41: 1.006261902461321, 42: -1.161160155994317, 43: 0.8833114074575376, 44: 1.0811966452823563, 45: -1.368200135415236, 46: -1.556580287072397, 47: -1.2006674694322674, 48: 0.13038922844618558, 49: 0.9941283827531714}, 'X2': {0: 1, 1: 1, 2: 0, 3: 0, 4: 0, 5: 1, 6: 1, 7: 1, 8: 0, 9: 0, 10: 0, 11: 1, 12: 0, 13: 1, 14: 1, 15: 1, 16: 0, 17: 0, 18: 0, 19: 0, 20: 0, 21: 0, 22: 0, 23: 0, 24: 1, 25: 0, 26: 1, 27: 0, 28: 0, 29: 1, 30: 1, 31: 1, 32: 0, 33: 0, 34: 0, 35: 1, 36: 0, 37: 0, 38: 0, 39: 0, 40: 0, 41: 0, 42: 0, 43: 0, 44: 0, 45: 0, 46: 0, 47: 0, 48: 1, 49: 0}, 'X3': {0: 0, 1: 0, 2: 1, 3: 1, 4: 1, 5: 0, 6: 0, 7: 0, 8: 0, 9: 1, 10: 0, 11: 0, 12: 1, 13: 0, 14: 0, 15: 0, 16: 1, 17: 0, 18: 1, 19: 1, 20: 1, 21: 1, 22: 1, 23: 0, 24: 0, 25: 1, 26: 0, 27: 1, 28: 1, 29: 0, 30: 0, 31: 0, 32: 1, 33: 1, 34: 1, 35: 0, 36: 1, 37: 1, 38: 1, 39: 0, 40: 1, 41: 1, 42: 1, 43: 1, 44: 1, 45: 1, 46: 1, 47: 1, 48: 0, 49: 1}, 'X4': {0: 1, 1: 1, 2: 1, 3: 1, 4: 0, 5: 1, 6: 1, 7: 1, 8: 0, 9: 1, 10: 0, 11: 1, 12: 0, 13: 1, 14: 1, 15: 1, 16: 0, 17: 0, 18: 0, 19: 1, 20: 0, 21: 1, 22: 1, 23: 1, 24: 1, 25: 0, 26: 1, 27: 1, 28: 1, 29: 1, 30: 1, 31: 1, 32: 0, 33: 1, 34: 0, 35: 1, 36: 1, 37: 0, 38: 1, 39: 0, 40: 1, 41: 0, 42: 1, 43: 0, 44: 0, 45: 1, 46: 1, 47: 1, 48: 1, 49: 0}, 'X5': {0: -1.6251996907891026, 1: -1.4952824550113089, 2: 0.5929477365851917, 3: 0.5188383985894559, 4: 0.8379329230408614, 5: -1.459754180360659, 6: -1.3954747896019781, 7: -1.4228738797414382, 8: 0.7961049502619677, 9: 0.5969844287269782, 10: 0.6254616540670719, 11: -1.1973174138607352, 12: 0.6743779844553507, 13: -1.3773048616218415, 14: -1.5502881165079259, 15: -1.410649926526345, 16: 0.966418551153225, 17: 0.8413042649713098, 18: 0.5947398261267023, 19: 0.5285211133411081, 20: 0.8154880527487283, 21: 0.685523955516477, 22: 0.7052301139466511, 23: 0.5694387744666269, 24: -1.3660759251156689, 25: 0.7376392137717523, 26: -1.2965881798979835, 27: 0.3247985508699227, 28: 0.8492845744063385, 29: -1.3631982627466268, 30: -1.5593937453283628, 31: -1.5647378670163918, 32: 0.7184017737689418, 33: 0.5401478202493889, 34: 0.8549277265014412, 35: -1.4324174459510242, 36: 0.5699907448414805, 37: 0.5278269967299144, 38: 0.6544095431196703, 39: 0.9956765313323911, 40: 0.49341021793456574, 41: 0.8777030715347666, 42: 0.5628001790223106, 43: 0.6932468790071539, 44: 0.5944907552098264, 45: 0.6628094310909329, 46: 0.660678722318602, 47: 0.68454503898171, 48: -1.5961965190965848, 49: 0.7606527604851616}, 'X6': {0: 0, 1: 0, 2: 0, 3: 0, 4: 1, 5: 0, 6: 0, 7: 0, 8: 1, 9: 0, 10: 1, 11: 0, 12: 1, 13: 0, 14: 0, 15: 0, 16: 1, 17: 1, 18: 1, 19: 0, 20: 1, 21: 0, 22: 0, 23: 0, 24: 0, 25: 1, 26: 0, 27: 0, 28: 0, 29: 0, 30: 0, 31: 0, 32: 1, 33: 0, 34: 1, 35: 0, 36: 0, 37: 1, 38: 0, 39: 1, 40: 0, 41: 1, 42: 0, 43: 1, 44: 1, 45: 0, 46: 0, 47: 0, 48: 0, 49: 1}, 'X7': {0: 0, 1: 0, 2: 1, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0, 13: 0, 14: 0, 15: 0, 16: 0, 17: 0, 18: 0, 19: 0, 20: 0, 21: 1, 22: 0, 23: 1, 24: 0, 25: 0, 26: 0, 27: 0, 28: 1, 29: 0, 30: 0, 31: 0, 32: 0, 33: 1, 34: 0, 35: 0, 36: 1, 37: 0, 38: 1, 39: 0, 40: 1, 41: 0, 42: 0, 43: 0, 44: 0, 45: 1, 46: 0, 47: 1, 48: 0, 49: 0}})
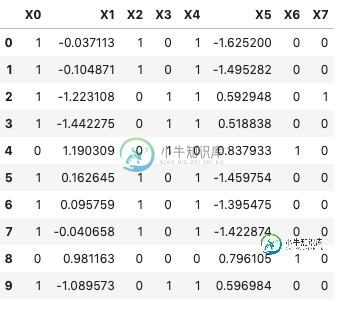
使用这样的数据集,我想根据不同的条件进行分组,例如:
df1 = df[(df['X0'] == 0) & (df['X2'] == 0)]
df2 = df[(df['X0'] == 1) & (df['X3'] == 1)]
df3 = df[(df['X0'] == 1) & (df['X4'] == 1)]
df4 = df[(df['X0'] == 1) & (df['X7'] == 0)]
df5 = df[(df['X2'] == 1) & (df['X6'] == 0)]
df6 = df[(df['X2'] == 1) & (df['X4'] == 1)]
df7 = df[(df['X2'] == 1) & (df['X3'] == 0)]
df8 = df[(df['X3'] == 1) & (df['X7'] == 0)]
df9 = df[(df['X3'] == 1) & (df['X6'] == 1)]
df10 = df[(df['X7'] == 1) & (df['X2'] == 0)]
在这一步中,我将每个数据帧缩减为一行,为此,我有一些想法,一个简单的方法是获取每个数据帧的平均值,但问题是有些列是分类的,有些是连续的,为了获取整个数据帧的平均值,我将分类列转换为freq count列:
cat_columns = ['X0', 'X2', 'X3', 'X4', 'X6', 'X7']
def add_freq(df, column_name):
for col in cat_columns:
df[f'{col}_freq'] = df[col].map(df[col].value_counts())
df = df.drop(col, axis = 1)
return df
all_groups = [df1, df2, df3, df4, df5,
df6, df7, df8, df9, df10]
all_freq_df = [add_freq(group, cat_columns) for group in all_groups]
对于每个df组,如下所示:
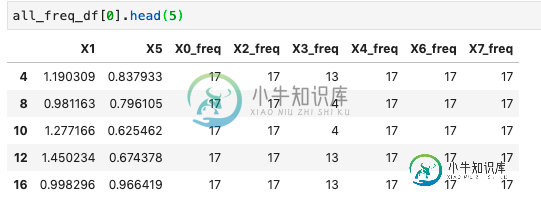
现在我可以取平均值并将数据帧减少到一行:
all_mean_df = [pd.DataFrame(group.mean()).T for group in all_freq_df]
在单个数据帧中包含所有缩减的行:
all_groups = pd.concat(all_mean_df).reset_index(drop=True)
最终的精简行数据框如下所示,其中每一行代表精简的数据框组:
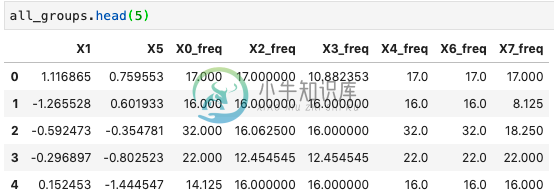
我想在这个简化的数据集中找到异常值,我尝试使用zscore查找异常值,例如:
from scipy import stats
all_groups[(np.abs(stats.zscore(all_groups)) < 3).all(axis=1)]
但它似乎不起作用。我觉得必须有一种不太复杂的方法来做到这一点,但我一直被如何进行所困扰。
如何将这些组缩减为单行,并在缩减后的数据集中找到异常值?
共有3个答案

由于不知道这些数据代表什么,这就更难了,所以我不得不尝试和探索。
我使用groupby和均值来减少行
dfx = pd.DataFrame()
for idx,group in enumerate(groups):
group = group.groupby(cat_columns).mean().reset_index()
group['group'] = 'df' + str(idx+1).zfill(2)
dfx = pd.concat([dfx, group])
我想象二进制列是输入的,十进制是输出的,所以我pivot将它们变成一行
创建名为输入的新列:
dfx['input'] = dfx[cat_columns].apply(lambda x: ''.join(x), axis=1)
旋转所需列并调整名称:
dfx.drop(cat_columns, axis=1, inplace=True)
dfxp = dfx.pivot(index='group', columns='input', values=['X1', 'X5'])
dfxp = dfxp.reset_index().fillna(0)
dfxp.columns = ['_'.join(x) for x in dfxp.columns]
使用PCA减少列数
from sklearn.decomposition import PCA
dft = PCA(n_components=2, svd_solver='full').fit_transform(dfxp.drop(columns = 'group_'))
dft = pd.DataFrame(dft, columns=['x', 'y'], index=dfxp.group_).reset_index()
px.scatter(dft, x='x', y='y', color='group_', title='t-SNE', height=600, width=600)
df7似乎是异常值。
感谢阅读:)

在高斯分布的实践中:超出平均值/-3*st.dev.的数据情况被视为异常值(超出99.7%的分布范围)。。。因此,对于高斯分布
data= df[col].values
_mean, _std = np.mean(data), np.std(data)
border = _std * 3
lower, upper = _mean - border, _mean + border
# outliers
outliers = [x for x in data if x < lower or x > upper]
有了数据——对于你需要的每一列的范围,都被作为循环使用——P.S.有时甚至可以使用4个st.dev.(覆盖99.9%的分布),但是1个st.dev.只有68%,2个st.dev-95%。。。所以,确定你真正需要什么

得到平均值和标准值。我们需要在每列上循环,得到平均值和标准值,然后设置我们接受的该列的最大值和最小值。
# Storring mean and std for every col as a tuple, 0 index for max value,
# and 1 for min value
outliers = []
for col in df.columns:
mean = np.mean(df[col].values)
std = np.std(df[col].std)
# You can play with the max and min below !
outliers.append((mean + std, mean - std))
# Then you have the list of tuples, with each tuple representing the max and min value you accept the column (index related).
-
本文向大家介绍pandas数据分组groupby()和统计函数agg()的使用,包括了pandas数据分组groupby()和统计函数agg()的使用的使用技巧和注意事项,需要的朋友参考一下 数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据
-
我有一个数据帧,并且我使用了从它到的几个列: 通过上面的方式,我几乎得到了我需要的表(数据帧)。缺少的是一个额外的列,该列包含每个组中的行数。换句话说,我有均值,但我也想知道有多少数字是用来得到这些均值的。例如,在第一组中有8个值,在第二组中有10个值,依此类推。
-
问题内容: 我有一个带有timeindex和3列的数据帧,其中包含3D矢量的坐标: 我想对也返回向量的每一行应用转换 但是如果我这样做: 我最后得到了一个以元组为元素的熊猫系列。这是因为apply将在不解压的情况下获取myfunc的结果。如何更改myfunc,以便获得具有3列的新df? 编辑: 以下所有解决方案均有效。Series解决方案确实允许使用列名,而List解决方案的执行速度似乎更快。 问
-
问题内容: df = pd.DataFrame({‘A’ : [‘foo’, ‘bar’, ‘foo’, ‘bar’, ‘foo’, ‘bar’, ‘foo’, ‘foo’], ‘B’ : [‘one’, ‘one’, ‘two’, ‘three’, ‘two’, ‘two’, ‘one’, ‘three’], ‘C’ : [np.nan, ‘bla2’, np.nan, ‘bla3’, np.n
-
问题内容: 我有以下形式的数据: 组内的非空值始终相同。我想对每个组(如果存在)的非空值进行一次计数,然后找到每个值的总数。 我目前正在以以下方式(笨拙和低效)进行此操作: 我敢肯定,有一种方法可以更干净地执行此操作,而无需使用循环,但是我似乎无法解决问题。任何帮助将非常感激。 问题答案: 我认为您可以使用: 的另一种解决方案,然后创建new by ,将其重塑为by和last :
-
我来自SQL环境,正在学习Python Pandas中的一些内容。我有一个关于分组和聚合的问题。 假设我按年龄类别对数据集进行分组,并计算不同的类别。在MSSQL中,我会这样写: 结果集是一个带有两列的“普通”表,第二列我命名为Count。 当我想在Pandas中进行等效时,groupby对象的格式不同。所以现在我必须重置索引,并在下面一行中重命名列。我的代码如下所示: 我的问题是,这是否可以一次