
Pandas/Python在读取3.2 GB文件时内存峰值

因此,我一直在尝试使用pandas<code>read_csv。
所以作为选择
> < li>
我尝试定义< code>dtype以避免将数据作为字符串保存在内存中,但看到了类似的行为。
尝试numpy read csv,以为我会得到一些不同的结果,但肯定是错误的。
试着一行一行地读也遇到了同样的问题,但是真的很慢。
我最近转到了python 3,所以认为那里可能有一些bug,但在python2 Panda上看到了类似的结果。
问题中的文件是来自kaggle竞赛grupo bimbo的train.csv文件
系统信息:
内存:16GB,处理器:i7 8核
如果你还想知道什么,请告诉我。
谢谢:)
编辑1:这是一个内存峰值!不是泄漏(对不起,我的错。)
编辑2:csv文件的示例
Semana,Agencia_ID,Canal_ID,Ruta_SAK,Cliente_ID,Producto_ID,Venta_uni_hoy,Venta_hoy,Dev_uni_proxima,Dev_proxima,Demanda_uni_equil
3,1110,7,3301,15766,1212,3,25.14,0,0.0,3
3,1110,7,3301,15766,1216,4,33.52,0,0.0,4
3,1110,7,3301,15766,1238,4,39.32,0,0.0,4
3,1110,7,3301,15766,1240,4,33.52,0,0.0,4
3,1110,7,3301,15766,1242,3,22.92,0,0.0,3
编辑3:在文件74180465中对行进行编号
其他然后一个简单的pd.read_csv('filename',low_memory=False)
我已经试过了
from numpy import genfromtxt
my_data = genfromtxt('data/train.csv', delimiter=',')
UPDATE下面的代码刚刚工作,但我仍然想深入了解这个问题,一定有什么问题。
import pandas as pd
import gc
data = pd.DataFrame()
data_iterator = pd.read_csv('data/train.csv', chunksize=100000)
for sub_data in data_iterator:
data.append(sub_data)
gc.collect()
编辑:一段有效的代码。感谢所有的帮助,我添加了python而不是numpy的数据类型,把我的数据类型搞砸了。有一次,我修复了以下代码的工作方式。
dtypes = {'Semana': pd.np.int8,
'Agencia_ID':pd.np.int8,
'Canal_ID':pd.np.int8,
'Ruta_SAK':pd.np.int8,
'Cliente_ID':pd.np.int8,
'Producto_ID':pd.np.int8,
'Venta_uni_hoy':pd.np.int8,
'Venta_hoy':pd.np.float16,
'Dev_uni_proxima':pd.np.int8,
'Dev_proxima':pd.np.float16,
'Demanda_uni_equil':pd.np.int8}
data = pd.read_csv('data/train.csv', dtype=dtypes)
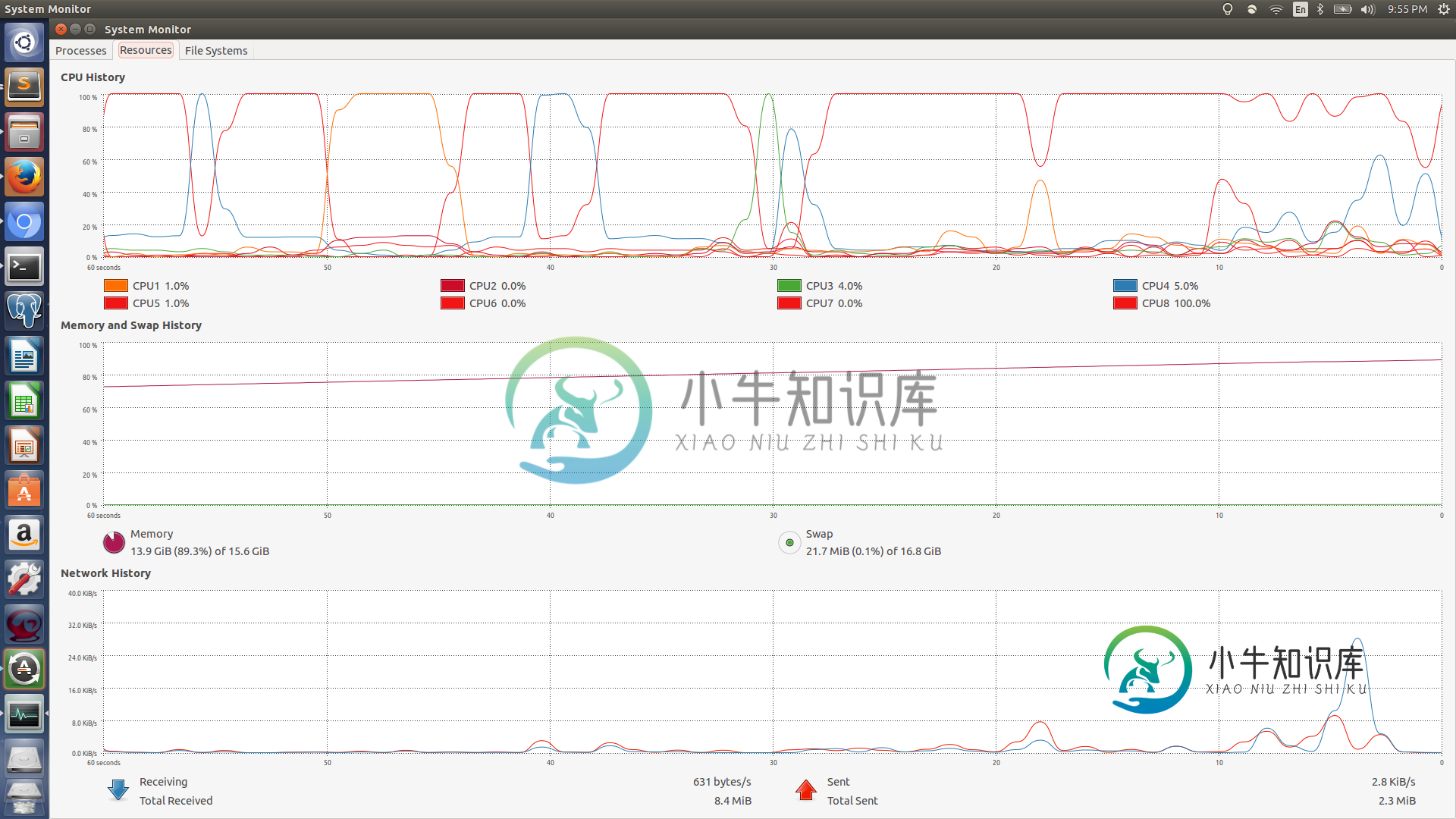
这将内存消耗降至略低于4Gb
共有2个答案

根据第二个图表,看起来好像有一段短暂的时间,你的计算机会额外分配 4.368 GB 的内存,这大约是 3.2 GB 数据集的大小(假设开销为 1GB,这可能是一个延伸)。
我试图找到一个可能发生这种情况的地方,但并不十分成功。如果你有动力的话,也许你能找到它。这是我走的路:
这行内容如下:
def read(self, nrows=None):
if nrows is not None:
if self.options.get('skip_footer'):
raise ValueError('skip_footer not supported for iteration')
ret = self._engine.read(nrows)
这里,_engine引用PythonParser。
这反过来又调用_get_lines()。
这将调用数据源。
它看起来像是以字符串的形式从一些相对标准的东西(见这里)读入的,比如TextIOWrapper。
因此,事情是作为标准文本读入和转换,这解释了缓慢的斜坡。
尖峰呢?我认为这可以用这些行来解释:
ret = self._engine.read(nrows)
if self.options.get('as_recarray'):
return ret
# May alter columns / col_dict
index, columns, col_dict = self._create_index(ret)
df = DataFrame(col_dict, columns=columns, index=index)
ret成为数据帧的所有组件。
_create_index()将ret拆分为以下组件:
def _create_index(self, ret):
index, columns, col_dict = ret
return index, columns, col_dict
到目前为止,一切都可以通过引用来完成,而对<code>DataFrame()
因此,如果我的理论是正确的,< code>DataFrame()要么在某个地方复制数据,要么< code>_engine.read()在我所确定的路径上的某个地方这样做。

以文本形式存储在内存中的文件不像压缩二进制格式那样紧凑,但在数据方面相对紧凑。如果它是一个简单的ascii文件,除了任何文件头信息,每个字符只有1个字节。Python字符串具有类似的关系,其中内部Python内容有一些开销,但每个额外的字符只添加1个字节(使用<code>__sizeof_
>>> s = '3,1110,7,3301,15766,1212,3,25.14,0,0.0,3\r\n'
>>> l = [3,1110,7,3301,15766,1212,3,25.14,0,0.0,3]
>>> s.__sizeof__()
75
>>> l.__sizeof__()
128
一点测试(假设<code>__sizeof_
import numpy as np
import pandas as pd
s = '1,2,3,4,5,6,7,8,9,10'
print ('string: '+str(s.__sizeof__())+'\n')
l = [1,2,3,4,5,6,7,8,9,10]
print ('list: '+str(l.__sizeof__())+'\n')
a = np.array([1,2,3,4,5,6,7,8,9,10])
print ('array: '+str(a.__sizeof__())+'\n')
b = np.array([1,2,3,4,5,6,7,8,9,10], dtype=np.dtype('u1'))
print ('byte array: '+str(b.__sizeof__())+'\n')
df = pd.DataFrame([1,2,3,4,5,6,7,8,9,10])
print ('dataframe: '+str(df.__sizeof__())+'\n')
返回:
string: 53
list: 120
array: 136
byte array: 106
dataframe: 152
-
主要内容:CSV文件读取,json读取文件,SQL数据库读取当使用 Pandas 做数据分析的时,需要读取事先准备好的数据集,这是做数据分析的第一步。Panda 提供了多种读取数据的方法: read_csv() 用于读取文本文件 read_json() 用于读取 json 文件 read_sql_query() 读取 sql 语句的, 本节将对上述方法做详细介绍。 CSV文件读取 CSV 又称逗号分隔值文件,是一种简单的文件格式,以特定的结构来排列表格数据
-
问题内容: 对此有很多问题,但是对于如何将xlsb文件读入熊猫还没有简单的答案。是否有捷径可寻? 问题答案: 随着pandas-的发布,增加了对二进制Excel文件的支持。 笔记: 您将需要升级熊猫- 您将需要安装-
-
我正在运行一个程序,可以处理30000个类似的文件。他们中的一些人正在停止并产生这个错误...
-
问题内容: 当我写这篇文章时,我尝试使用Pandas处理大型CSV文件。 它会引发“ pandas.parser.CParserError:错误标记数据。C错误:内存不足” wc -l表示有13822117行,我需要在此csv文件数据帧上进行汇总,有没有办法处理其他然后拆分CSV成几个文件,并编写代码以合并结果?有什么建议吗?谢谢 输入是这样的: 所需的输出是这样的: 如果数据集较小,则可以使用下
-
问题内容: 我正在运行一个程序,正在处理30,000个类似文件。他们中有随机数正在停止并产生此错误… 这些文件的源/创建都来自同一位置。纠正此错误以继续导入的最佳方法是什么? 问题答案: 可以选择处理不同格式的文件。我主要使用,或者替代地阅读,并且通常用于。 您还可以使用而不是的多个选项(请参阅python docs,也可能会遇到许多其他编码)。 请参阅相关的文档, 有关文件的文档示例以及有关SO
-
问题内容: 我有一个200kb的文件,可以在多个页面中使用,但是在每个页面上我只需要该文件的1-2行,那么如果我知道行号,该如何只读取这些行呢? 例如,如果我只需要第十行,那么我就不想将所有行(仅第十行)加载到内存中。 对不起,我的英语不好! 问题答案: 除非您知道该行的偏移量,否则您将需要读取该点之前的每一行。您可以通过使用循环遍历文件来丢弃旧的行(不需要的行)。 可能更好的解决方案是使用数据库