
1.23 多元高斯分布
多元高斯分布
介绍
我们称一个概率密度函数是一个均值为$\mu\in R^n$,协方差矩阵为$\Sigma\in S_{++}^n$的$^1$一个多元正态分布(或高斯分布)(multivariate normal (or Gaussian) distribution), 其随机变量是向量值$X=[X_1\dots X_n]^T$,该概率密度函数$^2$可以通过下式表达:
上一小段上标1,2的说明(详情请点击本行)
1 回顾一下线性代数章节中介绍的$S_{++}^n$是一个对称正定的$n\times n$矩阵空间,定义为: $$ S_{++}^n=\{A\in R^{n\times n}:A=A^T\quad and\quad x^TAx>0\quad for\quad all\quad x\in R^n\quad such\quad that\quad x\neq 0\} $$ 2 在我们的这部分笔记中,不使用$f_X(\bullet)$(如概率论笔记一节所述),而是使用符号$p(\bullet)$代表概率密度函数。
$$p(x;\mu,\Sigma)=\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}} \exp\left(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\right)$$
我们可以将其简写做$X\sim\mathcal{N}(\mu,\Sigma)$。在我们的这部分笔记中,我们描述了多元高斯函数及其一些基本性质。
1. 与单变量高斯函数的关系
回忆一下,一元正态分布(或高斯分布)(univariate normal (or Gaussian) distribution) 的概率密度函数是由下式给出:
$$p(x;\mu,\sigma^2)=\frac 1{\sqrt{2\pi}\sigma}\exp\left(-\frac 1{2\sigma^2}(x-\mu)^2\right)$$
这里,指数函数的自变量$-\frac 1{2\sigma^2}(x-\mu)^2$是关于变量$x$的二次函数。此外,抛物线是向下的,因为二次项的系数是负的。指数函数前面的系数$\frac 1{\sqrt{2\pi}\sigma}$是不依赖$x$的常数。因此,我们可以简单地把这个系数当作保证下面的式子成立的“标准化因子”(normalization factor)。
$$\frac 1{\sqrt{2\pi}\sigma}\int_{-\infin}^{\infin} \exp\left(-\frac 1{2\sigma^2}(x-\mu)^2\right)=1$$
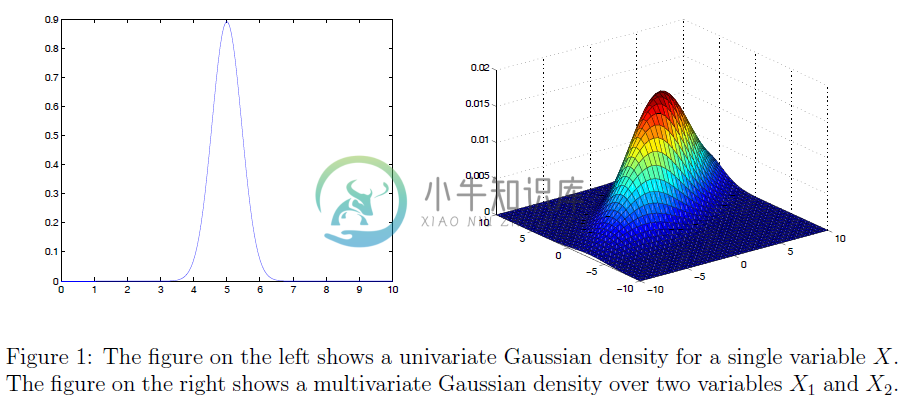
在多元高斯概率密度函数的情况下,指数函数的自变量$-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)$是一个以向量$x$为变量的二次形(quadratic form)。因为$\Sigma$是正定矩阵,并且任何正定矩阵的逆也是正定矩阵,所以对于任何非零向量$z$,有$z\Sigma^Tz>0$。这就表明了对于任何满足$x\neq\mu$的向量,有:
$$(x-\mu)^T\Sigma^{-1}(x-\mu)>0 \ -\frac 12(x-\mu)^T\Sigma^{-1}(x-\mu)<0$$
就像在单变量的情况下类似,这里你可以把指数函数的参数看成是一个开口向下的二次碗,指数函数前面的系数(即,$\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}$)是一个比单变量情况下更复杂的一种形式。但是,它仍然不依赖于$x$,因此它只是一个用来保证下面的式子成立的标准化因子:
$$\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}\int{-\infin}^{\infin}\int{-\infin}^{\infin}\dots\int_{-\infin}^{\infin}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))dx_1dx_2\dots dx_n=1$$
2. 协方差矩阵
协方差矩阵的概念对于理解多元高斯分布是至关重要的。回忆一下,对于一对随机变量$X$和$Y$,它们的协方差定义为:
$$Cov[X,Y]=E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y]$$
当处理多个变量时,协方差矩阵提供了一种简洁的方法来表达所有变量对的协方差。特别注意我们通常协方差矩阵表示成一个$n\times n$的矩阵$\Sigma$,其中第$(i,j)$个元素代表$Cov[X_i,Y_j]$。
下面的命题(其证明见附录A.1)给出了描述随机向量$X$的协方差矩阵的另一种方法:
命题 1. 对于任意一个具有均值为$\mu$的随机向量为$X$的协方差矩阵$\Sigma$如下:
$$\Sigma=E[(X-\mu)(X-\mu)^T]=E[XX^T]-\mu\mu^T$$
在多元高斯分布的定义中,我们要求协方差矩阵$\Sigma$是对称正定矩阵(即,$\Sigma\in S_{++}^n$)。为什么存在这种限制?如下面命题所示,任意随机向量的协方差矩阵都必须是对称正半定的:
命题 2. 假如$\Sigma$是关于随机向量$X$的协方差矩阵。则$\Sigma$是对称半正定矩阵。
证明。$\Sigma$的对称性直接来源于它的定义。然后对于任意向量$z\in R^n$我们可以观察到:
$$\begin{aligned} z^T\Sigma z &= \sum{i=1}^n\sum{j=1}^n(\Sigma{ij}z_iz_j)\qquad\qquad &(2) \ &= \sum{i=1}^n\sum{j=1}^n(Cov[X_i,X_j]\cdot z_iz_j) \ &= \sum{i=1}^n\sum{j=1}^n(E[(X_i-E[X_i])(X_j-E[X_j])] \cdot z_iz_j) \ &= E\left[\sum{i=1}^n\sum_{j=1}^n(X_i-E[X_i])(X_j-E[X_j])\cdot z_iz_j\right]&(3) \end{aligned}$$
这里,$(2)$式由二次形式的展开公式(参见线性代数部分章节)得到,$(3)$式由期望的线性性质得到(参见概率章节)。
想要要完成证明,请注意括号内的量是形式$\sum{i=1}^n\sum{j=1}^nx_ix_jz_iz_j=(x^Tz)^2\ge 0$(见问题设定#1)。因此,期望中的量总是非负的,即得到期望本身必须是非负的。我们可以断定$z^T\Sigma z\ge 0$
从上面的命题可以推出,为了使$\Sigma$成为一个有效的协方差矩阵,其必须是对称正半定的。然而,为了使$\Sigma^{-1}$存在(如多元高斯密度的定义所要求的),则$\Sigma$必须是可逆的,因此是满秩的。由于任何满秩对称正半定矩阵必然是对称正定的,因此$\Sigma$必然是对称正定的。
3. 对角协方差矩阵的情况
为了直观地理解多元高斯函数是什么,考虑一个简单的$n=2$并且协方差矩阵$\Sigma$是对角阵的例子,即:
$$x=\begin{bmatrix}x_1\x_2\end{bmatrix}\qquad\qquad \mu=\begin{bmatrix}\mu_1\\mu_2\end{bmatrix}\qquad\qquad \Sigma=\begin{bmatrix}\sigma_1^2&0\0&\sigma_2^2\end{bmatrix}$$
在这种情况下,多元高斯概率密度函数的形式如下:
$$\begin{aligned} p(x;\mu,\Sigma) &=\frac{1}{2\pi\begin{vmatrix}\sigma_1^2&0\0&\sigma_2^2\end{vmatrix}^{1/2}} \exp\left(-\frac{1}{2}\begin{bmatrix}x_1-\mu_1\x_2-\mu_2\end{bmatrix}^T\begin{bmatrix}\sigma_1^2&0\0&\sigma_2^2\end{bmatrix}^{-1}\begin{bmatrix}x_1-\mu_1\x_2-\mu_2\end{bmatrix}\right) \ &= \frac 1{2\pi(\sigma_1^2\cdot \sigma_2^2-0\cdot 0)^{1/2}}\exp\left(-\frac{1}{2}\begin{bmatrix}x_1-\mu_1\x_2-\mu_2\end{bmatrix}^T\begin{bmatrix}\frac 1{\sigma_1^2}&0\0&\frac 1{\sigma_2^2}\end{bmatrix}^{-1}\begin{bmatrix}x_1-\mu_1\x_2-\mu_2\end{bmatrix}\right) \end{aligned}$$
其中我们使用了一个$2\times 2$矩阵$^3$的行列式的显式公式,并且使用了一个对角矩阵的逆就是通过取每个对角元素的倒数来得到的事实。之后可得:
3 即$\begin{vmatrix}a&b\c&d\end{vmatrix}=ad-bc$
$$\begin{aligned} p(x;\mu,\Sigma) &=\frac{1}{2\pi\sigma_1\sigma_2} \exp\left(-\frac{1}{2}\begin{bmatrix}x_1-\mu_1\x_2-\mu_2\end{bmatrix}^T\begin{bmatrix}\frac 1{\sigma_1^2}(x_1-\mu_1)\\frac 1{\sigma_2^2}(x_2-\mu_2)\end{bmatrix}\right) \ &= \frac{1}{2\pi\sigma_1\sigma_2} \exp\left(-\frac 1{2\sigma_1^2}(x_1-\mu_1)^2-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2\right) \ &= \frac{1}{\sqrt{2\pi}\sigma_1} \exp\left(-\frac 1{2\sigma_1^2}(x_1-\mu_1)^2\right)\cdot \frac{1}{\sqrt{2\pi}\sigma_2} \exp\left(-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2\right) \end{aligned}$$
最后一个等式是两个独立的高斯概率函数函数的乘积,其中一个具有均值$\mu_1$,方差$\sigma_1^2$。另一个具有均值$\mu_2$,方差$\sigma_2^2$。
更一般地,我们可以证明$n$维具有为均值$\mu\in R^n$,对角协方差矩阵为$\sigma=diag(\sigma_1^2,\sigma_2^2,\dots,\sigma_n^2)$高斯概率密度函数等于$n$个独立的随机变量分别是均值为$\mu_i$,方差为$\sigma_i^2$的高斯概率密度函数的乘积。
4. 等高线
从概念上理解多元高斯函数的另一种方法是理解其等高线的形状。对于一个函数$f:R^2\rightarrow R$,等高线集合数学表达形式如下:
$${x\in R^2:f(x)=c}$$
其中$c\in R$。$^4$
4 等高线通常也称为等值线(level curves)。 更一般地说,函数的一组水平集(level set) $f:R^2\rightarrow R$是一个对于一些$c\in R$形式为${x\in R^2:f(x)=c}$的集合。
4.1 等高线的型状
多元高斯函数的等高线是什么样的?和之前一样,我们考虑$n = 2$,协方差矩阵$\Sigma$是对角阵的情况,即:
$$x=\begin{bmatrix}x_1\x_2\end{bmatrix}\qquad\qquad \mu=\begin{bmatrix}\mu_1\\mu_2\end{bmatrix}\qquad\qquad \Sigma=\begin{bmatrix}\sigma_1^2&0\0&\sigma_2^2\end{bmatrix}$$
正如我们在上一节所展示的那样,有:
$$p(x;\mu,\Sigma) = \frac{1}{2\pi\sigma_1\sigma_2} \exp\left(-\frac 1{2\sigma_1^2}(x_1-\mu_1)^2-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2\right)\qquad\qquad(4)$$
现在,让我们考虑由所有点组成的水平集,其中对于某个常数$c\in R$来说$p(x;\mu,\sigma)=c$。 特别的,考虑所有$x_1,x_2\in R$的集合,比如:
$$\begin{aligned} c&=\frac{1}{2\pi\sigma_1\sigma_2} \exp\left(-\frac 1{2\sigma_1^2}(x_1-\mu_1)^2-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2\right) \ 2\pi c\sigma_1\sigma_2 &= \exp\left(-\frac 1{2\sigma_1^2}(x_1-\mu_1)^2-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2\right) \ log(2\pi c\sigma_1\sigma_2) &= -\frac 1{2\sigma_1^2}(x_1-\mu_1)^2-\frac 1{2\sigma_2^2}(x_2-\mu_2)^2 \ log(\frac 1{2\pi c\sigma_1\sigma_2}) &= \frac 1{2\sigma_1^2}(x_1-\mu_1)^2+\frac 1{2\sigma_2^2}(x_2-\mu_2)^2 \ 1 &= \frac {(x_1-\mu_1)^2}{2\sigma_1^2log(\frac 1{2\pi c\sigma_1\sigma_2})}+\frac {(x_2-\mu_2)^2}{2\sigma_2^2log(\frac 1{2\pi c\sigma_1\sigma_2})} \end{aligned}$$
定义:
$$r_1= \sqrt{2\sigma_1^2log(\frac 1{2\pi c\sigma_1\sigma_2})}\qquad\qquad r_2= \sqrt{2\sigma_2^2log(\frac 1{2\pi c\sigma_1\sigma_2})}$$
之后可得:
$$1 = (\frac {x_1-\mu_1}{r_1})^2+(\frac {x_2-\mu_2}{r_2})^2\qquad\qquad (5)$$
方程$(5)$在高中解析几何中应该很熟悉:它是一个轴向椭圆(axis-aligned ellipse) 的方程,其中心是$(\mu_1,\mu_2)$,并且$x_1$轴的长度是$2r_1$,$x_2$轴的长度是$2r_2$!
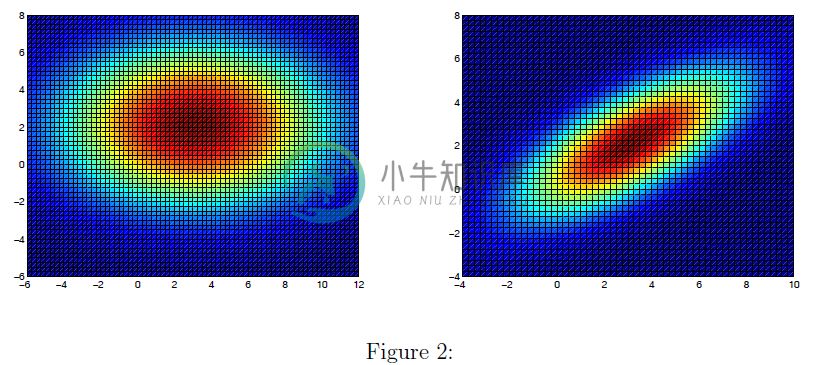 左边的图显示了一个热图,它表示具有均值为$\mu=\begin{bmatrix}3\2\end{bmatrix}$,对角协方差矩阵为$\Sigma=\begin{bmatrix}25&0\0&9\end{bmatrix}$的轴向多元高斯函数的概率密度函数值。注意到这个高斯分布的中心点为$(3,2)$,等高线均为椭圆形,长/短轴长之比为$5:3$。右边的图显示了一个热图,该图表示了一个非轴向对齐的具有平均值为$\mu=\begin{bmatrix}3\2\end{bmatrix}$协方差矩阵为$\Sigma=\begin{bmatrix}25&5\5&5\end{bmatrix}$的多元高斯概率密度函数值。这里,椭圆再次以$(3,2)$为中心,但现在通过线性变换旋转了主轴和副主轴。
左边的图显示了一个热图,它表示具有均值为$\mu=\begin{bmatrix}3\2\end{bmatrix}$,对角协方差矩阵为$\Sigma=\begin{bmatrix}25&0\0&9\end{bmatrix}$的轴向多元高斯函数的概率密度函数值。注意到这个高斯分布的中心点为$(3,2)$,等高线均为椭圆形,长/短轴长之比为$5:3$。右边的图显示了一个热图,该图表示了一个非轴向对齐的具有平均值为$\mu=\begin{bmatrix}3\2\end{bmatrix}$协方差矩阵为$\Sigma=\begin{bmatrix}25&5\5&5\end{bmatrix}$的多元高斯概率密度函数值。这里,椭圆再次以$(3,2)$为中心,但现在通过线性变换旋转了主轴和副主轴。
4.2 轴的长度
为了更好地理解等值线的形状是如何随着多元高斯分布的方差变化的,也许我们会对当$c$等于高斯密度峰值高度的为分数$1/e$时的$r_1$和$r_2$的值感兴趣。
首先,观察式$(4)$式的最大值出现在$x_1=\mu_1,x_2=\mu_2$。将这些值代入式$(4)$,我们看到高斯密度的峰值高度为$\frac 1{2\pi\sigma_1\sigma_2}$。
其次,我们将等式中的$r_1,r_2$的变量$c$替换为$c=\frac 1e(\frac 1{2\pi\sigma_1\sigma_2})$可以得到:
$$r_1= \sqrt{2\sigma_1^2log(\frac 1{2\pi \sigma_1\sigma_2\cdot \frac 1e(\frac 1{2\pi\sigma_1\sigma_2})})}=\sigma_1\sqrt2 \ r_2= \sqrt{2\sigma_2^2log(\frac 1{2\pi c\sigma_1\sigma_2\cdot \frac 1e(\frac 1{2\pi\sigma_1\sigma_2})})}=\sigma_2\sqrt2$$
从上式可以得出,轴的长度需要达到高斯概率密度函数锋值高度的$1/e$,该高斯概率密度函数在第$i$个维度上与标准差$\sigma_i$成正比增长。直观地说,这是有道理的:某个随机变量$x_i$的方差越小,在那个维度高斯分布的峰值越“紧密”,因此半径$r_i$越小。
4.3 非对角、高维的情况
显然,上面的推导依赖于$\Sigma$是对角矩阵的假设。然而,在非对角的情况下,情况并没有发生太大的变化。等高线不是一个轴向对齐的椭圆,而是简单地旋转椭圆(rotated ellipses)。 此外,在$n$维情况下,水平集形成的几何结构称为$R^n$的椭球(ellipsoids)。
5. 线性变换的解释
在最后几节中,我们主要关注如何提供一个多元高斯分布与对角协方差矩阵的直观感觉。特别的,我们发现一个具有对角协方差矩阵的$n$维多元高斯分布可以被简单地看作是$n$个独立的随机变量分别是均值为$\mu_i$,方差是$\sigma_i^2$高斯分布的乘积。在本节中,我们将更深入地探讨并提供一个当协方差矩阵不是对角阵时多元高斯分布的定量解释。
本节的关键结果是以下定理(参见附录A.2中的证明)。
定理 1 给定$X\sim\mathcal{N}(\mu,\Sigma)$,其中$\mu\in R^n,\Sigma\in S_{++}^n$。则存在矩阵$B\in R^{n\times n}$如果我们定义$Z=B^{-1}(X-\mu)$,则满足$Z\sim\mathcal{N}(0,I)$。
为了理解这个定理的意义,注意到如果$Z\sim\mathcal{N}(0,I)$,则利用第$4$节的分析,$Z$可以看作是$n$个独立标准正态随机变量的集合(即,$Z_i\sim\mathcal{N}(0,1)$)。进一步,如果$Z=B^{-1}(X-\mu)$,则根据简单的代数知识可得$X=BZ+\mu$。
因此,该定理表明:任何具有多元高斯分布的随机变量$X$都可以解释为对$n$个独立标准正态随机变量$(Z)$集合进行线性变换$(X=BZ+\mu)$的结果。
附录 A.1
证明。我们证明了$(1)$中的两个等式中的第一个等式;另一个等式的证明是相似的。
$$\begin{aligned} \Sigma &= \begin{bmatrix}Cov[X_1,X_1]&\dots&Cov[X_1,X_n]\\vdots&\ddots&\vdots\Cov[X_n,X_1]&\dots&Cov[X_n,X_n]\end{bmatrix} \ &= \begin{bmatrix}E[(X_1-\mu_1)^2]&\dots&E[(X_1-\mu_1)(X_n-\mu_n)]\\vdots&\ddots&\vdots\E[(X_n-\mu_n)(X_1-\mu_1)]&\dots&E[(X_n-\mu_n)^2]\end{bmatrix} \ &= E\begin{bmatrix}(X_1-\mu_1)^2&\dots&(X_1-\mu_1)(X_n-\mu_n)\\vdots&\ddots&\vdots\(X_n-\mu_n)(X_1-\mu_1)&\dots&(X_n-\mu_n)^2\end{bmatrix} &(6) \ &= E\begin{bmatrix}\begin{bmatrix}X_1-\mu_1\\vdots\X_n-\mu_n\end{bmatrix}[X_1-\mu_1\dots X_n-\mu_n]\end{bmatrix} &(7) \ &= E[(X-\mu)(X-\mu)^T] \end{aligned}$$
这里,公式中的$(6)$由“一个矩阵的期望仅仅是通过取每一项的分量期望而得到的矩阵”得到。同样,公式中的$(7)$由“对于任何向量$z\in R^n$,下面的式子成立”而得到。
$$zz^T=\begin{bmatrix}z_1\z_2\\vdots\z_n\end{bmatrix}[z_1\quad z_2\quad\dots z_n]=\begin{bmatrix}z_1z_1&z_1z_2&\dots&z_1z_n\z_2z_1&z_2z_2&\dots&z_2z_n\\vdots&\vdots&\ddots&\vdots\z_nz_1&z_nz_2&\dots&z_nz_n\end{bmatrix}$$
附录 A.2
我们重申以下定理:
定理 1 给定$X\sim\mathcal{N}(\mu,\Sigma)$,其中$\mu\in R^n,\Sigma\in S_{++}^n$。则存在矩阵$B\in R^{n\times n}$如果我们定义$Z=B^{-1}(X-\mu)$,则满足$Z\sim\mathcal{N}(0,I)$。
这个定理的推导需要一些高级线性代数和概率论,仅学习本课程内容的话可以跳过。我们的论点将由两部分组成。首先,对于某个可逆矩阵$B$,我们会证明协方差矩阵$\Sigma$可以因式分解为$\Sigma=BB^T$。其次,我们将根据关系$Z=B^{-1}(X-\mu)$执行从变量$X$到另一个向量值随机变量$Z$的变量“换元(change-of-variable)”。
第一步:分解协方差矩阵。 :回忆一下线性代数$^5$笔记中对称矩阵的两个性质:
5 参见“对称矩阵的特征值和特征向量”一节。
- 任意实对称矩阵$A\in R^{n\times n}$总是可以表示为$A=U\Lambda U^T$,其中$U$是一个满秩正交矩阵,其中$A$的特征向量作为它的列。$\Lambda$是一个包含$A$的特征值的对角矩阵。
- 如果A是对称正定的,它的所有特征值都是正的。
因为协方差矩阵$\Sigma$是正定的,使用第一个性质,我们可以对于一些适当定义的矩阵$U,\Lambda$写出$\Sigma=U\Lambda U^T$。利用第二个性质,我们可以定义$\Lambda^{1/2}\in R^{n\times n}$是一个对角矩阵,它的元素是对应来自于$\Lambda$元素的平方根。因为$\Lambda=\Lambda^{1/2}(\Lambda^{1/2})^T$,我们可得:
$$\Sigma=U\Lambda U^T=U\Lambda^{1/2}(\Lambda^{1/2})^TU^T=U\Lambda^{1/2}(U\Lambda^{1/2})^T=BB^T$$
其中$B=U\Lambda^{1/2}$。$^6$那么在这种情况下$\Sigma^{-1}=B^{-T}B^{-1}$,所以我们可以把多元高斯函数的密度的标准公式重写为:
6 为了证明B是可逆的,只要观察到$U$是可逆矩阵,并且将$U$右乘一个对角矩阵(没有零对角元素)将重新排列它的列,但不会改变它的秩。
$$p(x;\mu,\Sigma)=\frac{1}{(2\pi)^{n/2}|BB^T|^{1/2}} \exp\left(-\frac{1}{2}(x-\mu)^TB^{-T}B^{-1}(x-\mu)\right)\qquad\qquad(8)$$
第二步:变量替换。 现在,定义向量值随机变量$Z=B^{-1}(X-\mu)$。概率论的一个基本公式是有关向量值随机变量的变量变换公式,我们在概率论的讲义中没有介绍这个公式。
假设$X=[X_1\dots X_n]^T\in R^n$是联合概率密度函数$f_X:R^n\rightarrow R$的向量值随机变量。如果$Z=H(X)\in R^n$,其中$H$是一个一个双射的可微函数,则$Z$是一个联合概率密度函数$f_Z:R^n\rightarrow R$,其中:
$$f_Z(z)=f_X(x)\cdot\begin{vmatrix}det\begin{pmatrix}\begin{bmatrix}\frac {\partial x_1}{\partial z_1}&\dots&\frac {\partial x_1}{\partial z_n}\\vdots&\ddots&\vdots\\frac{\partial x_n}{\partial z_1}&\dots&\frac{\partial x_n}{\partial z_n}\end{bmatrix}\end{pmatrix}\end{vmatrix}$$
使用变量变换公式,我们可以证明(经过一些我们将跳过的代数运算)向量变量$Z$的联合概率密度如下:
$$p_Z(z)=\frac 1{(2\pi)^{n/2}}\exp\left(-\frac 12z^Tz\right)\qquad \qquad (9)$$