
聚类 - LDA(隐式狄利克雷分布)
LDA是一种概率主题模型:隐式狄利克雷分布(Latent Dirichlet Allocation,简称LDA)。LDA是2003年提出的一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出。
通过分析一些文档,我们可以抽取出它们的主题(分布),根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
举一个简单的例子,比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习的方式,获取每个主题Topic对应的词语,如下图所示:
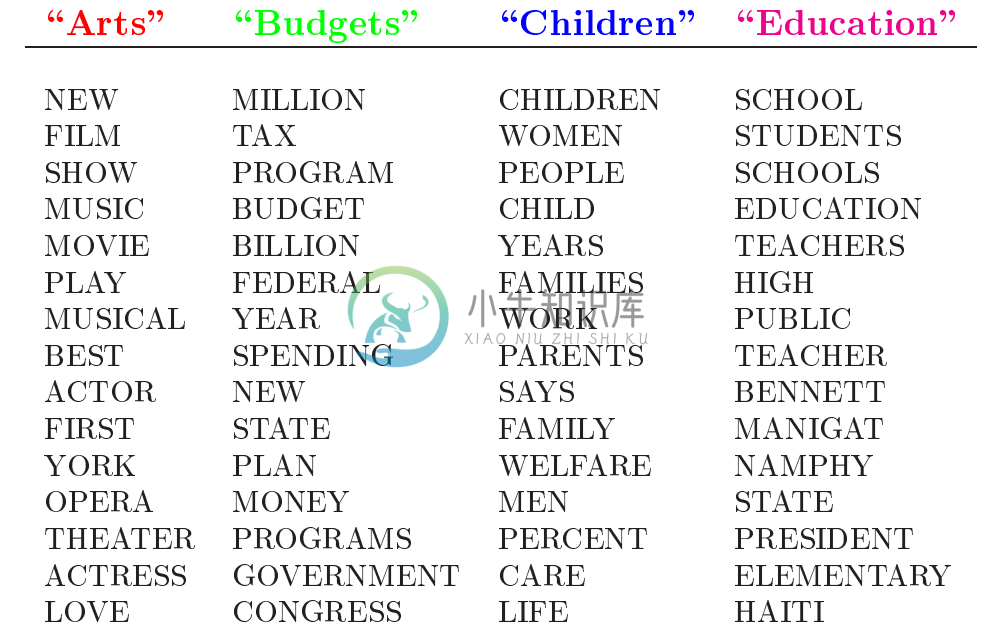
然后以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断的重复这两步,最终生成如下图所示的一篇文章(不同颜色的词语分别表示不同主题)。

我们看到一篇文章后,往往会推测这篇文章是如何生成的,我们通常认为作者会先确定几个主题,然后围绕这几个主题遣词造句写成全文。LDA要干的事情就是根据给定的文档,判断它的主题分布。在LDA模型中,生成文档的过程有如下几步:
从狄利克雷分布$\alpha$中生成文档i的主题分布$\theta_{i}$ ;
从主题的多项式分布$\theta{i}$中取样生成文档i第j个词的主题$Z{i,j}$ ;
从狄利克雷分布$\eta$中取样生成主题$Z{i,j}$对应的词语分布$\beta{i,j}$ ;
从词语的多项式分布$\beta{i,j}$中采样最终生成词语$W{i,j}$ .
LDA的图模型结构如下图所示:
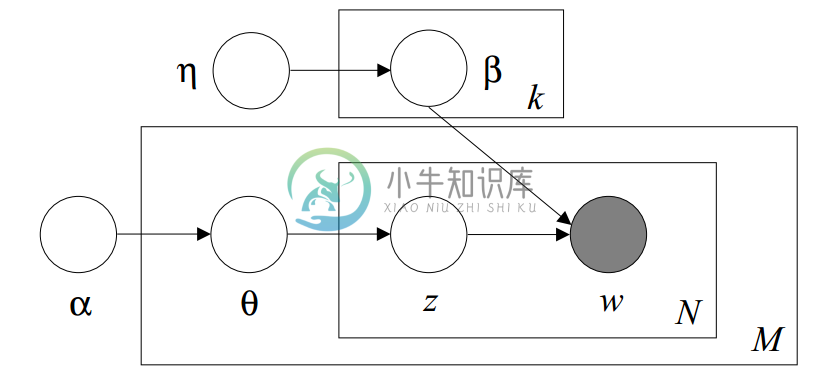
LDA会涉及很多数学知识,后面的章节我会首先介绍LDA涉及的数学知识,然后在这些数学知识的基础上详细讲解LDA的原理。
1 数学预备
1.1 Gamma函数
在高等数学中,有一个长相奇特的Gamma函数
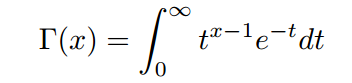
通过分部积分,可以推导gamma函数有如下递归性质
通过该递归性质,我们可以很容易证明,gamma函数可以被当成阶乘在实数集上的延拓,具有如下性质
1.2 Digamma函数
如下函数被称为Digamma函数,它是Gamma函数对数的一阶导数
这是一个很重要的函数,在涉及Dirichlet分布相关的参数的极大似然估计时,往往需要用到这个函数。Digamma函数具有如下一个漂亮的性质
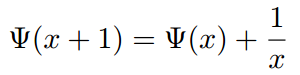
1.3 二项分布(Binomial distribution)
二项分布是由伯努利分布推出的。伯努利分布,又称两点分布或0-1分布,是一个离散型的随机分布,其中的随机变量只有两类取值,即0或者1。二项分布是重复n次的伯努利试验。简言之,只做一次实验,是伯努利分布,重复做了n次,是二项分布。二项分布的概率密度函数为:
对于k=1,2,…,n,其中C(n,k)是二项式系数(这就是二项分布的名称的由来)
1.4 多项分布
多项分布是二项分布扩展到多维的情况。多项分布是指单次试验中的随机变量的取值不再是0-1,而是有多种离散值可能(1,2,3...,k)。比如投掷6个面的骰子实验,N次实验结果服从K=6的多项分布。其中:
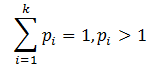
多项分布的概率密度函数为:
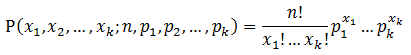
1.5 Beta分布
1.5.1 Beta分布
首先看下面的问题1(问题1到问题4都取自于文献【1】)。
问题1:

为解决这个问题,可以尝试计算$x_{(k)}$落在区间[x,x+delta x]的概率。首先,把[0,1]区间分成三段[0,x),[x,x+delta x],(x+delta x,1],然后考虑下简单的情形:即假设n个数中只有1个落在了区间[x,x+delta x]内,由于这个区间内的数X(k)是第k大的,所以[0,x)中应该有k−1个数,(x+delta x,1]这个区间中应该有n−k个数。
如下图所示:
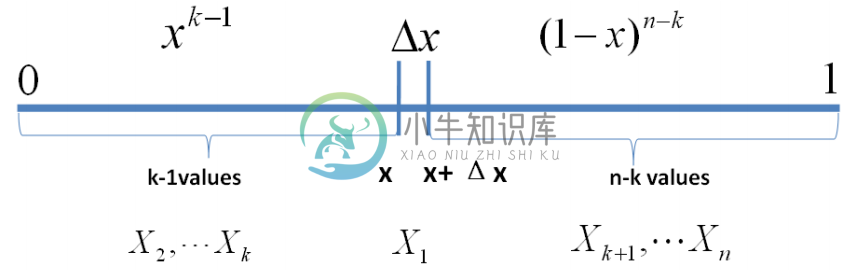
上述问题可以转换为下述事件E:
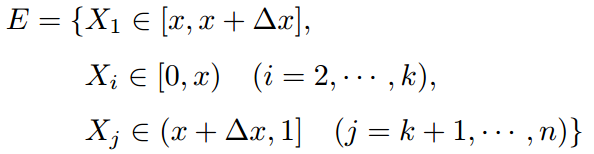
对于上述事件E,有:

其中,o(delta x)表示delta x的高阶无穷小。显然,由于不同的排列组合,即n个数中有一个落在[x,x+delta x]区间的有n种取法,余下n−1个数中有k−1个落在[0,x)的有C(n-1,k-1)种组合。所以和事件E等价的事件一共有nC(n-1,k-1)个。
文献【1】中证明,只要落在[x,x+delta x]内的数字超过一个,则对应的事件的概率就是o(delta x)。所以$x_{(k)}$的概率密度函数为:
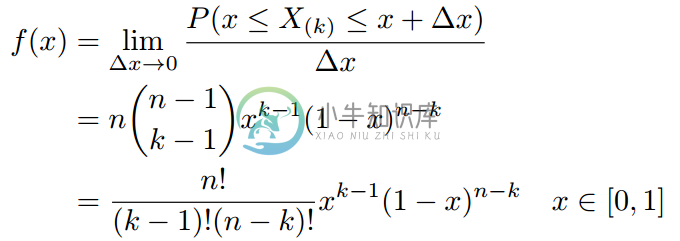
利用Gamma函数,我们可以将f(x)表示成如下形式:
在上式中,我们用alpha=k,beta=n-k+1替换,可以得到beta分布的概率密度函数
1.5.2 共轭先验分布
什么是共轭呢?轭的意思是束缚、控制。共轭从字面上理解,则是共同约束,或互相约束。在贝叶斯概率理论中,如果后验概率P(z|x)和先验概率p(z)满足同样的分布,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
1.5.3 Beta-Binomial 共轭
我们在问题1的基础上增加一些观测数据,变成问题2:

第2步的条件可以用另外一句话来表述,即“Yi中有m1个比X(k)小,m2个比X(k)大”,所以X(k)是$X{(1)},X{(2)},…,X{(n)};Y{(1)},Y{(2)},…,Y{(m)}$中k+m1大的数。
根据1.5.1的介绍,我们知道事件p服从beta分布,它的概率密度函数为:
按照贝叶斯推理的逻辑,把以上过程整理如下:
1、p是我们要猜测的参数,我们推导出
p的分布为f(p)=Beta(p|k,n-k+1),称为p的先验分布2、根据
Yi中有m1个比p小,有m2个比p大,Yi相当是做了m次伯努利实验,所以m1服从二项分布B(m,p)3、在给定了来自数据提供
(m1,m2)知识后,p的后验分布变为f(p|m1,m2)=Beta(p|k+m1,n-k+1+m2)
贝叶斯估计的基本过程是:
先验分布 + 数据的知识 = 后验分布
以上贝叶斯分析过程的简单直观的表示就是:
Beta(p|k,n-k+1) + BinomCount(m1,m2) = Beta(p|k+m1,n-k+1+m2)
更一般的,对于非负实数alpha和beta,我们有如下关系
Beta(p|alpha,beta) + BinomCount(m1,m2) = Beta(p|alpha+m1,beta+m2)
针对于这种观测到的数据符合二项分布,参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomial共轭。换言之,Beta分布是二项式分布的共轭先验概率分布。二项分布和Beta分布是共轭分布意味着,如果我们为二项分布的参数p选取的先验分布是Beta分布,那么以p为参数的二项分布用贝叶斯估计得到的后验分布仍然服从Beta分布。
1.6 Dirichlet 分布
1.6.1 Dirichlet 分布
Dirichlet分布,是beta分布在高维度上的推广。Dirichlet分布的的密度函数形式跟beta分布的密度函数类似:
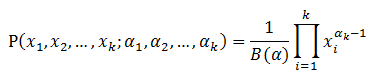
其中
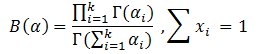
至此,我们可以看到二项分布和多项分布很相似,Beta分布和Dirichlet分布很相似。并且Beta分布是二项式分布的共轭先验概率分布。那么Dirichlet分布呢?Dirichlet分布是多项式分布的共轭先验概率分布。下文来论证这点。
1.6.2 Dirichlet-Multinomial 共轭
在1.5.3章问题2的基础上,我们更进一步引入问题3:

类似于问题1的推导,我们可以容易推导联合分布。为了简化计算,我们取x3满足x1+x2+x3=1,x1和x2是变量。如下图所示。

概率计算如下:

于是我们得到联合分布为:
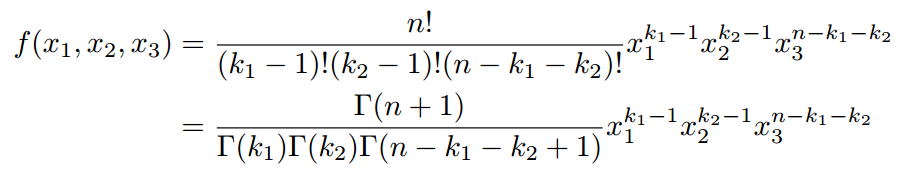
观察上述式子的最终结果,可以看出上面这个分布其实就是3维形式的Dirichlet分布。令alpha1=k1,alpha2=k2,alpha3=n-k1-k2+1,分布密度函数可以写为:
为了论证Dirichlet分布是多项式分布的共轭先验概率分布,在上述问题3的基础上再进一步,提出问题4。

为了方便计算,我们记
根据问题中的信息,我们可以推理得到p1,p2在X;Y这m+n个数中分别成为了第k1+m1,k1+k2+m1+m2大的数。后验分布p应该为
同样的,按照贝叶斯推理的逻辑,可将上述过程整理如下:
1 我们要猜测参数
P=(p1,p2,p3),其先验分布为Dir(p|k);2 数据
Yi落到三个区间[0,p1),[p1,p2],(p2,1]的个数分别是m1,m2,m3,所以m=(m1,m2,m3)服从多项分布Mult(m|p);3 在给定了来自数据提供的知识
m后,p的后验分布变为Dir(P|k+m)
上述贝叶斯分析过程的直观表述为:
Dir(p|k) + Multcount(m) = Dir(p|k+m)
针对于这种观测到的数据符合多项分布,参数的先验分布和后验分布都是Dirichlet分布的情况,就是Dirichlet-Multinomial共轭。这意味着,如果我们为多项分布的参数p选取的先验分布是Dirichlet分布,那么以p为参数的多项分布用贝叶斯估计得到的后验分布仍然服从Dirichlet分布。
1.7 Beta和Dirichlet分布的一个性质
如果p=Beta(t|alpha,beta),那么
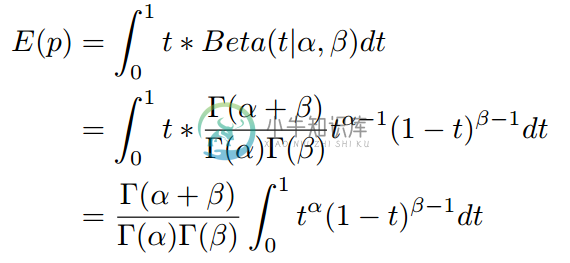
上式右边的积分对应到概率分布Beta(t|alpha+1,beta),对于这个分布,我们有
把上式带人E(p)的计算式,可以得到:
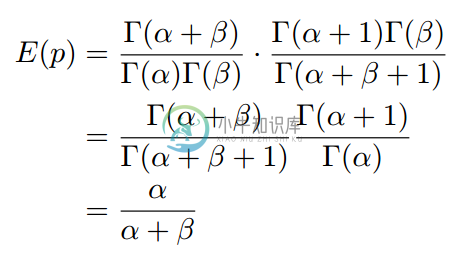
这说明,对于Beta分布的随机变量,其期望可以用上式来估计。Dirichlet分布也有类似的结论。对于p=Dir(t|alpha),有
这个结论在后文的推导中会用到。
1.8 总结
LDA涉及的数学知识较多,需要认真体会,以上大部分的知识来源于文献【1,2,3】,如有不清楚的地方,参见这些文献以了解更多。
2 主题模型LDA
在介绍LDA之前,我们先介绍几个基础模型:Unigram model、mixture of unigrams model、pLSA model。为了方便描述,首先定义一些变量:
- 1
w表示词,V表示所有词的个数 - 2
z表示主题,k表示主题的个数 - 3 $D=(W{1},W{2},…,W_{M})$表示语料库,
M表示语料库中的文档数。 - 4 $W=(w{1},w{2},…,w_{N})$表示文档,
N表示文档中词的个数。
2.1 一元模型(Unigram model)
对于文档$W=(w{1},w{2},…,w{N})$ ,用$p(w{n})$表示$w_{n}$的先验概率,生成文档W的概率为:
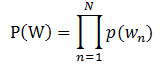
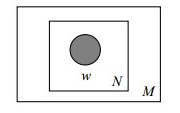
其图模型为(图中被涂色的w表示可观测变量,N表示一篇文档中总共N个单词,M表示M篇文档):
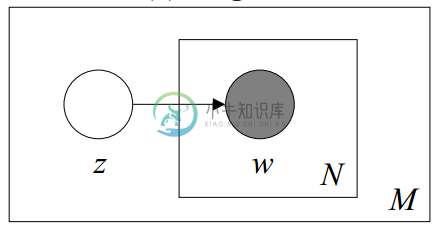
2.2 混合一元模型(Mixture of unigrams model)
该模型的生成过程是:给某个文档先选择一个主题Z,再根据该主题生成文档,该文档中的所有词都来自一个主题。生成文档的概率为:
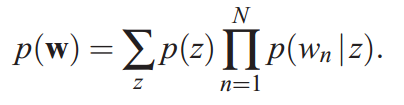
其图模型为(图中被涂色的w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档):
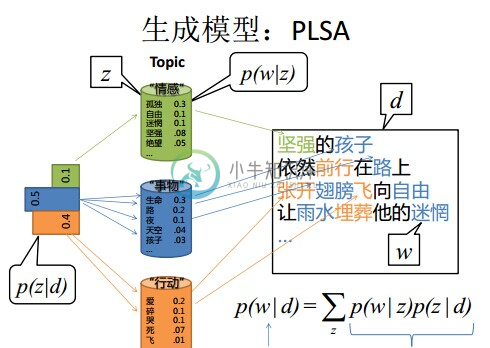
2.3 pLSA模型
在混合一元模型中,假定一篇文档只由一个主题生成,可实际中,一篇文章往往有多个主题,只是这多个主题各自在文档中出现的概率大小不一样。在pLSA中,假设文档由多个主题生成。下面通过一个投色子的游戏(取自文献【2】的例子)说明pLSA生成文档的过程。
首先,假定你一共有K个可选的主题,有V个可选的词。假设你每写一篇文档会制作一颗K面的“文档-主题”骰子(扔此骰子能得到K个主题中的任意一个),和K个V面的“主题-词项”骰子(每个骰子对应一个主题,K个骰子对应之前的K个主题,且骰子的每一面对应要选择的词项,V个面对应着V个可选的词)。
比如可令K=3,即制作1个含有3个主题的“文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令V = 3,制作3个有着3面的“主题-词项”骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
其次,每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。先扔“文档-主题”的骰子,假设以一定的概率得到的主题是:教育,所以下一步便是扔教育主题筛子,以一定的概率得到教育主题筛子对应的某个词大学。
上面这个投骰子产生词的过程简化一下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如可能选取教育主题的概率是0.5,选取经济主题的概率是0.3,选取交通主题的概率是0.2,那么这3个主题的概率分布便是
{教育:0.5,经济:0.3,交通:0.2},我们把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。同样的,从主题分布中随机抽取出教育主题后,依然面对着3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如大学这个词被选中的概率是0.5,老师这个词被选中的概率是0.3,课程被选中的概率是0.2,那么这3个词的概率分布便是
{大学:0.5,老师:0.3,课程:0.2},我们把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。所以,选主题和选词都是两个随机的过程,先从主题分布
{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
上述过程抽象出来即是pLSA的文档生成模型。在这个过程中,我们并未关注词和词之间的出现顺序,所以pLSA是一种词袋模型。定义如下变量:
$(z{1},z{2},…,z_{k})$表示隐藏的主题;
$P(d_{i})$表示海量文档中某篇文档被选中的概率;
$P(w{j}|d{i})$表示词$w{j}$在文档$d{i}$中出现的概率;针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率;
$P(z{k}|d{i})$表示主题$z{k}$在文档$d{i}$中出现的概率;
$P(w{j}|z{k})$表示词$w{j}$在主题$z{k}$中出现的概率。与主题关系越密切的词其条件概率越大。
我们可以按照如下的步骤得到“文档-词项”的生成模型:
1 按照$P(d{i})$选择一篇文档$d{i}$ ;
2 选定文档$d{i}$之后,从主题分布中按照概率$P(z{k}|d_{i})$选择主题;
3 选定主题后,从词分布中按照概率$P(w{j}|z{k})$选择一个词。
利用看到的文档推断其隐藏的主题(分布)的过程,就是主题建模的目的:自动地发现文档集中的主题(分布)。文档d和单词w是可被观察到的,但主题z却是隐藏的。如下图所示(图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档)。
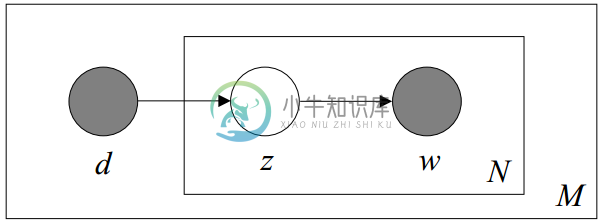
上图中,文档d和词w是我们得到的样本,可观测得到,所以对于任意一篇文档,其$P(w{j}|d{i})$是已知的。根据这个概率可以训练得到文档-主题概率以及主题-词项概率。即:
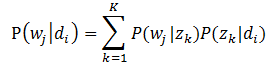
故得到文档中每个词的生成概率为:
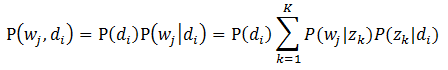
$P(d{i})$可以直接得出,而$P(z{k}|d{i})$和$P(w{j}|z{k})$未知,所以
$\theta=(P(z{k}|d{i}),P(w{j}|z_{k}))$就是我们要估计的参数,我们要最大化这个参数。因为该待估计的参数中含有隐变量z,所以我们可以用EM算法来估计这个参数。
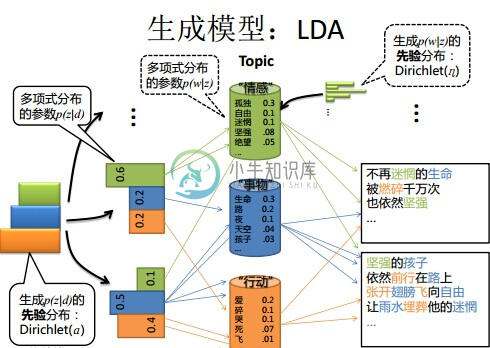
2.4 LDA模型
LDA的不同之处在于,pLSA的主题的概率分布P(z|d)是一个确定的概率分布,也就是虽然主题z不确定,但是z符合的概率分布是确定的,比如符合某个多项分布,这个多项分布的各参数是确定的。
但是在LDA中,这个多项分布都是不确定的,这个多项式分布又服从一个狄利克雷先验分布(Dirichlet prior)。即LDA就是pLSA的贝叶斯版本,正因为LDA被贝叶斯化了,所以才会加两个先验参数。
LDA模型中一篇文档生成的方式如下所示:
1 按照$P(d{i})$选择一篇文档$d{i}$ ;
2 从狄利克雷分布$\alpha$中生成文档$d{i}$的主题分布$\theta{i}$ ;
3 从主题的多项式分布$\theta{i}$中取样生成文档$d{i}$第
j个词的主题$Z_{i,j}$ ;4 从狄利克雷分布$\eta$中取样生成主题$Z{i,j}$对应的词语分布$\beta{i,j}$ ;
5 从词语的多项式分布$\beta{i,j}$中采样最终生成词语$W{i,j}$
从上面的过程可以看出,LDA在pLSA的基础上,为主题分布和词分布分别加了两个Dirichlet先验。
拿之前讲解pLSA的例子进行具体说明。如前所述,在pLSA中,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
在LDA中,选主题和选词依然都是两个随机的过程。但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不能确定,因为它是随机的可变化的。
但再怎么变化,也依然服从一定的分布,主题分布和词分布由Dirichlet先验确定。
举个文档d产生主题z的例子。
在pLSA中,给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示:
在pLSA中,主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的,而LDA的主题分布和词分布是不固定的。LDA为提供了两个Dirichlet先验参数,Dirichlet先验为某篇文档随机抽取出主题分布和词分布。
给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6,而主题分布到底是哪个取值集合我们不确定,但其先验分布是dirichlet分布,所以可以从无穷多个主题分布中按照dirichlet先验随机抽取出某个主题分布出来。如下图所示
LDA在pLSA的基础上给两参数$P(z{k}|d{i})$和$P(w{j}|z{k})$加了两个先验分布的参数。这两个分布都是Dirichlet分布。
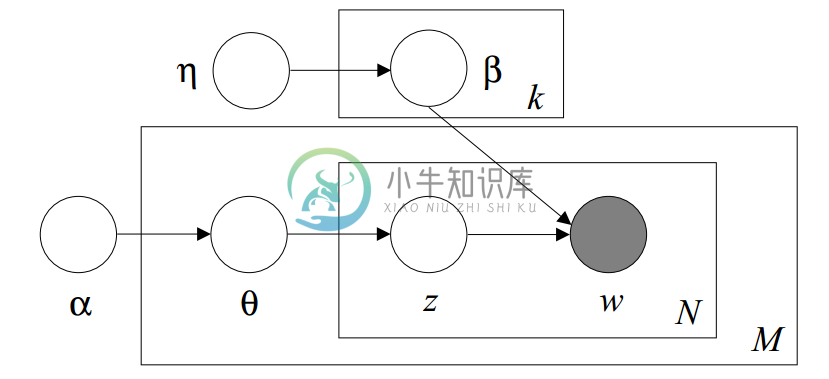
下面是LDA的图模型结构:
3 LDA 参数估计
spark实现了2个版本的LDA,这里分别叫做Spark EM LDA(见文献【3】【4】)和Spark Online LDA(见文献【5】)。它们使用同样的数据输入,但是内部的实现和依据的原理完全不同。Spark EM LDA使用GraphX实现的,通过对图的边和顶点数据的操作来训练模型。而Spark Online LDA采用抽样的方式,每次抽取一些文档训练模型,通过多次训练,得到最终模型。在参数估计上,Spark EM LDA使用gibbs采样原理估计模型参数,Spark Online LDA使用贝叶斯变分推断原理估计参数。在模型存储上,Spark EM LDA将训练的主题-词模型存储在GraphX图顶点上,属于分布式存储方式。Spark Online使用矩阵来存储主题-词模型,属于本地模型。通过这些差异,可以看出Spark EM LDA和Spark Online LDA的不同之处,同时他们各自也有各自的瓶颈。Spark EM LDA在训练时shuffle量相当大,严重拖慢速度。而Spark Online LDA使用矩阵存储模型,矩阵规模直接限制训练文档集的主题数和词的数目。另外,Spark EM LDA每轮迭代完毕后更新模型,Spark Online LDA每训练完抽样的文本更新模型,因而Spark Online LDA模型更新更及时,收敛速度更快。
3.1 变分EM算法
变分贝叶斯算法的详细信息可以参考文献【9】。
在上文中,我们知道LDA将变量theta和phi(为了方便起见,我们将上文LDA图模型中的beta改为了phi)看做随机变量,并且为theta添加一个超参数为alpha的Dirichlet先验,为phi添加一个超参数为eta的Dirichlet先验来估计theta和phi的最大后验(MAP)。
可以通过最优化最大后验估计来估计参数。我们首先来定义几个变量:
- 下式的
gamma表示词为w,文档为j时,主题为k的概率,如公式 (3.1.1)
$N_{wj}$表示词
w在文档j中出现的次数;$N_{wk}$表示词
w在主题k中出现的次数,如公式 (3.1.2)
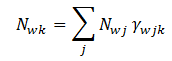
- $N_{kj}$表示主题
k在文档j中出现的次数,如公式 (3.1.3)
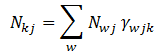
- $N_{k}$表示主题
k中包含的词出现的总次数,如公式 (3.1.4)
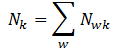
- $N_{j}$表示文档
j中包含的主题出现的总次数,如公式 (3.1.5)
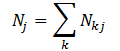
根据文献【4】中2.2章节的介绍,我们可以推导出如下更新公式 (3.1.6) ,其中alpha和eta均大于1:
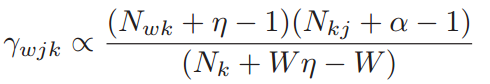
收敛之后,最大后验估计可以得到公式 (3.1.7):
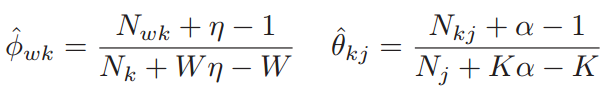
变分EM算法的流程如下:
1 初始化状态,即随机初始化$N{wk}$和$N{kj}$
2 E-步,对每一个
(文档,词汇)对i,计算$P(z{i}|w{i},d_{i})$,更新gamma值3 M-步,计算隐藏变量
phi和theta。即计算$N{wk}$和$N{kj}$4 重复以上2、3两步,直到满足最大迭代数
第4.2章会从代码层面说明该算法的实现流程。
3.2 在线学习算法
3.2.1 批量变分贝叶斯
在变分贝叶斯推导(VB)中,根据文献【3】,使用一种更简单的分布q(z,theta,beta)来估计真正的后验分布,这个简单的分布使用一组自由变量(free parameters)来定义。
通过最大化对数似然的一个下界(Evidence Lower Bound (ELBO))来最优化这些参数,如下公式 (3.2.1)
最大化ELBO就是最小化q(z,theta,beta)和p(z,theta,beta|w,alpha,eta)的KL距离。根据文献【3】,我们将q因式分解为如下 (3.2.2) 的形式:
后验z通过phi来参数化,后验theta通过gamma来参数化,后验beta通过lambda来参数化。为了简单描述,我们把lambda当作“主题”来看待。公式 (3.2.2) 分解为如下 (3.2.3) 形式:
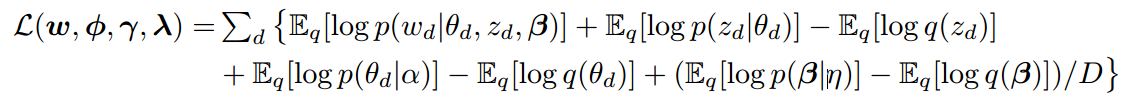
我们现在将上面的期望扩展为变分参数的函数形式。这反映了变分目标只依赖于$n_{dw}$ ,即词w出现在文档d中的次数。当使用VB算法时,文档可以通过它们的词频来汇总(summarized),如公式 (3.2.4)
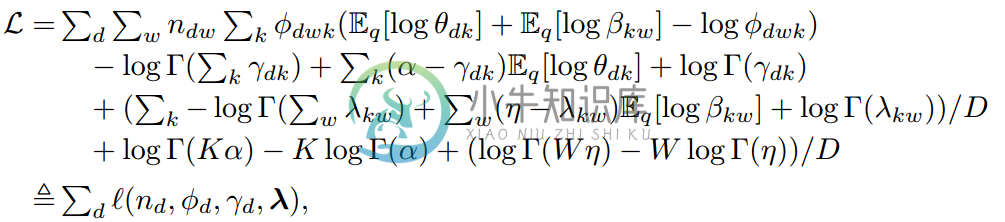
上面的公式中,W表示词的数量,D表示文档的数量。l表示文档d对ELBO所做的贡献。L可以通过坐标上升法来最优化,它的更新公式如 (3.2.5):
log(theta)和log(beta)的期望通过下面的公式 (3.2.6) 计算:
通过EM算法,我们可以将这些更新分解成E-步和M-步。E-步固定lambda来更新gamma和phi;M-步通过给定phi来更新lambda。批VB算法的过程如下 (算法1) 所示:

3.2.2 在线变分贝叶斯
批量变分贝叶斯算法需要固定的内存,并且比吉布斯采样更快。但是它仍然需要在每次迭代时处理所有的文档,这在处理大规模文档时,速度会很慢,并且也不适合流式数据的处理。
文献【5】提出了一种在线变分推导算法。设定gamma(n_d,lambda)和phi(n_d,lambda)分别表示gamma_d和phi_d的值,我们的目的就是设定phi来最大化下面的公式 (3.2.7)
我们在 算法2 中介绍了在线VB算法。因为词频的第t个向量$n_{t}$是可观察的,我们在E-步通过固定lambda来找到gamma_t和phi_t的局部最优解。
然后,我们计算lambda_cap。如果整个语料库由单个文档重复D次组成,那么这样的lambda_cap设置是最优的。之后,我们通过lambda之前的值以及lambda_cap来更新lambda。我们给lambda_cap设置的权重如公式 (3.2.8) 所示:
在线VB算法的实现流程如下 算法2 所示

那么在在线VB算法中,alpha和eta是如何更新的呢?参考文献【8】提供了计算方法。给定数据集,dirichlet参数的可以通过最大化下面的对数似然来估计
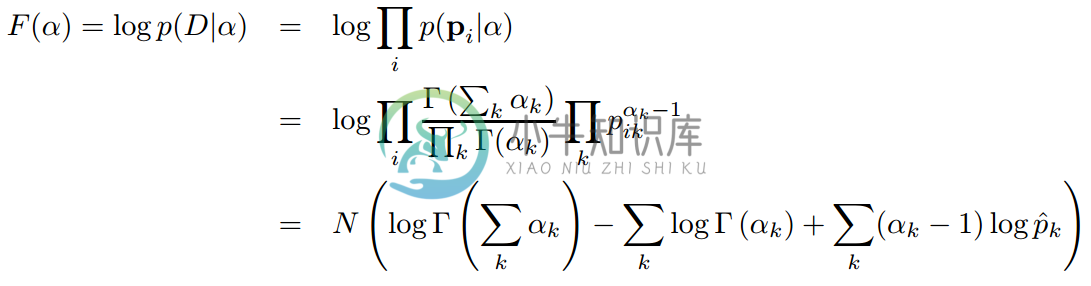
其中,
有多种方法可以最大化这个目标函数,如梯度上升,Newton-Raphson等。Spark使用Newton-Raphson方法估计参数,更新alpha。Newton-Raphson提供了一种参数二次收敛的方法,
它一般的更新规则如下公式 (3.3.3) :
其中,H表示海森矩阵。对于这个特别的对数似然函数,可以应用Newton-Raphson去解决高维数据,因为它可以在线性时间求出海森矩阵的逆矩阵。一般情况下,海森矩阵可以用一个对角矩阵和一个元素都一样的矩阵的和来表示。
如下公式 (3.3.4) ,Q是对角矩阵,C11是元素相同的一个矩阵。
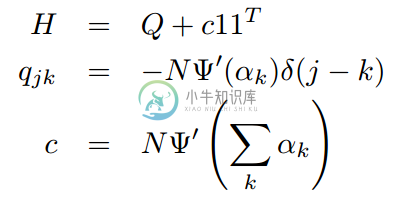
为了计算海森矩阵的逆矩阵,我们观察到,对任意的可逆矩阵Q和非负标量c,有下列式子 (3.3.5):

因为Q是对角矩阵,所以Q的逆矩阵可以很容易的计算出来。所以Newton-Raphson的更新规则可以重写为如下 (3.3.6) 的形式
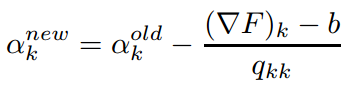
其中b如下公式 (3.3.7),
4 LDA代码实现
4.1 LDA使用实例
我们从官方文档【6】给出的使用代码为起始点来详细分析LDA的实现。
import org.apache.spark.mllib.clustering.{LDA, DistributedLDAModel}import org.apache.spark.mllib.linalg.Vectors// 加载和处理数据val data = sc.textFile("data/mllib/sample_lda_data.txt")val parsedData = data.map(s => Vectors.dense(s.trim.split(' ').map(_.toDouble)))// 为文档编号,编号唯一。List((id,vector)....)val corpus = parsedData.zipWithIndex.map(_.swap).cache()// 主题个数为3val ldaModel = new LDA().setK(3).run(corpus)val topics = ldaModel.topicsMatrixfor (topic <- Range(0, 3)) {print("Topic " + topic + ":")for (word <- Range(0, ldaModel.vocabSize)) { print(" " + topics(word, topic)); }println()}
以上代码主要做了两件事:加载和切分数据、训练模型。在样本数据中,每一行代表一篇文档,经过处理后,corpus的类型为List((id,vector)*),一个(id,vector)代表一篇文档。将处理后的数据传给org.apache.spark.mllib.clustering.LDA类的run方法,
就可以开始训练模型。run方法的代码如下所示:
def run(documents: RDD[(Long, Vector)]): LDAModel = {val state = ldaOptimizer.initialize(documents, this)var iter = 0val iterationTimes = Array.fill[Double](maxIterations)(0)while (iter < maxIterations) {val start = System.nanoTime()state.next()val elapsedSeconds = (System.nanoTime() - start) / 1e9iterationTimes(iter) = elapsedSecondsiter += 1}state.getLDAModel(iterationTimes)}
这段代码首先调用initialize方法初始化状态信息,然后循环迭代调用next方法直到满足最大的迭代次数。在我们没有指定的情况下,迭代次数默认为20。需要注意的是,ldaOptimizer有两个具体的实现类EMLDAOptimizer和OnlineLDAOptimizer,它们分别表示使用EM算法和在线学习算法实现参数估计。在未指定的情况下,默认使用EMLDAOptimizer。
4.2 变分EM算法的实现
在spark中,使用GraphX来实现EMLDAOptimizer,这个图是有两种类型的顶点的二分图。这两类顶点分别是文档顶点(Document vertices)和词顶点(Term vertices)。
文档顶点文档顶点
ID编号从0递增,保存长度为k(主题个数)的向量词顶点使用
{-1, -2, ..., -vocabSize}来索引,词顶点编号从-1递减,保存长度为k(主题个数)的向量边(
edges)对应词出现在文档中的词频。边的方向是document -> term,并且根据document进行分区
我们可以根据3.1节中介绍的算法流程来解析源代码。
4.2.1 初始化状态
spark在EMLDAOptimizer的initialize方法中实现初始化功能。包括初始化Dirichlet参数alpha和eta、初始化边、初始化顶点以及初始化图。
//对应超参数alphaval docConcentration = lda.getDocConcentration//对应超参数etaval topicConcentration = lda.getTopicConcentrationthis.docConcentration = if (docConcentration == -1) (50.0 / k) + 1.0 else docConcentrationthis.topicConcentration = if (topicConcentration == -1) 1.1 else topicConcentration
上面的代码初始化了超参数alpha和eta,根据文献【4】,当alpha未指定时,初始化其为(50.0 / k) + 1.0,其中k表示主题个数。当eta未指定时,初始化其为1.1。
//对于每个文档,为每一个唯一的Term创建一个(Document->Term)的边val edges: RDD[Edge[TokenCount]] = docs.flatMap { case (docID: Long, termCounts: Vector) =>// Add edges for terms with non-zero counts.termCounts.toBreeze.activeIterator.filter(_._2 != 0.0).map { case (term, cnt) =>//文档id,termindex,词频Edge(docID, term2index(term), cnt)}}//term2index将term转为{-1, -2, ..., -vocabSize}索引private[clustering] def term2index(term: Int): Long = -(1 + term.toLong)
上面的这段代码处理每个文档,对文档中每个唯一的Term(词)创建一个边,边的格式为(文档id,词索引,词频)。词索引为{-1, -2, ..., -vocabSize}。
//创建顶点val docTermVertices: RDD[(VertexId, TopicCounts)] = {val verticesTMP: RDD[(VertexId, TopicCounts)] =edges.mapPartitionsWithIndex { case (partIndex, partEdges) =>val random = new Random(partIndex + randomSeed)partEdges.flatMap { edge =>val gamma = normalize(BDV.fill[Double](k)(random.nextDouble()), 1.0)//此处的sum是DenseVector,gamma*N_wjval sum = gamma * edge.attr//srcId表示文献id,dstId表是词索引Seq((edge.srcId, sum), (edge.dstId, sum))}}verticesTMP.reduceByKey(_ + _)}
上面的代码创建顶点。我们为每个主题随机初始化一个值,即gamma是随机的。sum为gamma * edge.attr,这里的edge.attr即N_wj,所以sum用gamma * N_wj作为顶点的初始值。
this.graph = Graph(docTermVertices, edges).partitionBy(PartitionStrategy.EdgePartition1D)
上面的代码初始化Graph并通过文档分区。
4.2.2 E-步:更新gamma
val eta = topicConcentrationval W = vocabSizeval alpha = docConcentrationval N_k = globalTopicTotalsval sendMsg: EdgeContext[TopicCounts, TokenCount, (Boolean, TopicCounts)] => Unit =(edgeContext) => {// 计算 N_{wj} gamma_{wjk}val N_wj = edgeContext.attr// E-STEP: 计算 gamma_{wjk} 通过N_{wj}来计算//此处的edgeContext.srcAttr为当前迭代的N_kj , edgeContext.dstAttr为当前迭代的N_wk,//后面通过M-步,会更新这两个值,作为下一次迭代的当前值val scaledTopicDistribution: TopicCounts =computePTopic(edgeContext.srcAttr, edgeContext.dstAttr, N_k, W, eta, alpha) *= N_wjedgeContext.sendToDst((false, scaledTopicDistribution))edgeContext.sendToSrc((false, scaledTopicDistribution))}
上述代码中,W表示词数,N_k表示所有文档中,出现在主题k中的词的词频总数,后续的实现会使用方法computeGlobalTopicTotals来更新这个值。N_wj表示词w出现在文档j中的词频数,为已知数。E-步就是利用公式 (3.1.6) 去更新gamma。
代码中使用computePTopic方法来实现这个更新。edgeContext通过方法sendToDst将scaledTopicDistribution发送到目标顶点,
通过方法sendToSrc发送到源顶点以便于后续的M-步更新的N_kj和N_wk。下面我们看看computePTopic方法。
private[clustering] def computePTopic(docTopicCounts: TopicCounts,termTopicCounts: TopicCounts,totalTopicCounts: TopicCounts,vocabSize: Int,eta: Double,alpha: Double): TopicCounts = {val K = docTopicCounts.lengthval N_j = docTopicCounts.dataval N_w = termTopicCounts.dataval N = totalTopicCounts.dataval eta1 = eta - 1.0val alpha1 = alpha - 1.0val Weta1 = vocabSize * eta1var sum = 0.0val gamma_wj = new Array[Double](K)var k = 0while (k < K) {val gamma_wjk = (N_w(k) + eta1) * (N_j(k) + alpha1) / (N(k) + Weta1)gamma_wj(k) = gamma_wjksum += gamma_wjkk += 1}// normalizeBDV(gamma_wj) /= sum}
这段代码比较简单,完全按照公式 (3.1.6) 表示的样子来实现。val gamma_wjk = (N_w(k) + eta1) * (N_j(k) + alpha1) / (N(k) + Weta1)就是实现的更新逻辑。
4.2.3 M-步:更新phi和theta
// M-STEP: 聚合计算新的 N_{kj}, N_{wk} counts.val docTopicDistributions: VertexRDD[TopicCounts] =graph.aggregateMessages[(Boolean, TopicCounts)](sendMsg, mergeMsg).mapValues(_._2)
我们由公式 (3.1.7) 可知,更新隐藏变量phi和theta就是更新相应的N_kj和N_wk。聚合更新使用aggregateMessages方法来实现。请参考文献【7】来了解该方法的作用。
4.3 在线变分算法的代码实现
4.3.1 初始化状态
在线学习算法首先使用方法initialize方法初始化参数值
override private[clustering] def initialize(docs: RDD[(Long, Vector)],lda: LDA): OnlineLDAOptimizer = {this.k = lda.getKthis.corpusSize = docs.count()this.vocabSize = docs.first()._2.sizethis.alpha = if (lda.getAsymmetricDocConcentration.size == 1) {if (lda.getAsymmetricDocConcentration(0) == -1) Vectors.dense(Array.fill(k)(1.0 / k))else {require(lda.getAsymmetricDocConcentration(0) >= 0,s"all entries in alpha must be >=0, got: $alpha")Vectors.dense(Array.fill(k)(lda.getAsymmetricDocConcentration(0)))}} else {require(lda.getAsymmetricDocConcentration.size == k,s"alpha must have length k, got: $alpha")lda.getAsymmetricDocConcentration.foreachActive { case (_, x) =>require(x >= 0, s"all entries in alpha must be >= 0, got: $alpha")}lda.getAsymmetricDocConcentration}this.eta = if (lda.getTopicConcentration == -1) 1.0 / k else lda.getTopicConcentrationthis.randomGenerator = new Random(lda.getSeed)this.docs = docs// 初始化变分分布 q(beta|lambda)this.lambda = getGammaMatrix(k, vocabSize)this.iteration = 0this}
根据文献【5】,alpha和eta的值大于等于0,并且默认为1.0/k。上文使用getGammaMatrix方法来初始化变分分布q(beta|lambda)。
private def getGammaMatrix(row: Int, col: Int): BDM[Double] = {val randBasis = new RandBasis(new org.apache.commons.math3.random.MersenneTwister(randomGenerator.nextLong()))//初始化一个gamma分布val gammaRandomGenerator = new Gamma(gammaShape, 1.0 / gammaShape)(randBasis)val temp = gammaRandomGenerator.sample(row * col).toArraynew BDM[Double](col, row, temp).t}
getGammaMatrix方法使用gamma分布初始化一个随机矩阵。
4.3.2 更新参数
override private[clustering] def next(): OnlineLDAOptimizer = {//返回文档集中采样的子集//默认情况下,文档可以被采样多次,且采样比例是0.05val batch = docs.sample(withReplacement = sampleWithReplacement, miniBatchFraction,randomGenerator.nextLong())if (batch.isEmpty()) return thissubmitMiniBatch(batch)}
以上的next方法首先对文档进行采样,然后调用submitMiniBatch对采样的文档子集进行处理。下面我们详细分解submitMiniBatch方法。
- 1 计算
log(beta)的期望,并将其作为广播变量广播到集群中
val expElogbeta = exp(LDAUtils.dirichletExpectation(lambda)).t//广播变量val expElogbetaBc = batch.sparkContext.broadcast(expElogbeta)//参数alpha是dirichlet参数private[clustering] def dirichletExpectation(alpha: BDM[Double]): BDM[Double] = {val rowSum = sum(alpha(breeze.linalg.*, ::))val digAlpha = digamma(alpha)val digRowSum = digamma(rowSum)val result = digAlpha(::, breeze.linalg.*) - digRowSumresult}
上述代码调用exp(LDAUtils.dirichletExpectation(lambda))方法实现参数为lambda的log beta的期望。实现原理参见公式 (3.2.6)。
- 2 计算
phi以及gamma,即 算法2 中的E-步
//对采样文档进行分区处理val stats: RDD[(BDM[Double], List[BDV[Double]])] = batch.mapPartitions { docs =>//val nonEmptyDocs = docs.filter(_._2.numNonzeros > 0)val stat = BDM.zeros[Double](k, vocabSize)var gammaPart = List[BDV[Double]]()nonEmptyDocs.foreach { case (_, termCounts: Vector) =>val ids: List[Int] = termCounts match {case v: DenseVector => (0 until v.size).toListcase v: SparseVector => v.indices.toList}val (gammad, sstats) = OnlineLDAOptimizer.variationalTopicInference(termCounts, expElogbetaBc.value, alpha, gammaShape, k)stat(::, ids) := stat(::, ids).toDenseMatrix + sstatsgammaPart = gammad :: gammaPart}Iterator((stat, gammaPart))}
上面的代码调用OnlineLDAOptimizer.variationalTopicInference实现 算法2 中的E-步,迭代计算phi和gamma。
private[clustering] def variationalTopicInference(termCounts: Vector,expElogbeta: BDM[Double],alpha: breeze.linalg.Vector[Double],gammaShape: Double,k: Int): (BDV[Double], BDM[Double]) = {val (ids: List[Int], cts: Array[Double]) = termCounts match {case v: DenseVector => ((0 until v.size).toList, v.values)case v: SparseVector => (v.indices.toList, v.values)}// 初始化变分分布 q(theta|gamma)val gammad: BDV[Double] = new Gamma(gammaShape, 1.0 / gammaShape).samplesVector(k) // K//根据公式(3.2.6)计算 E(log theta)val expElogthetad: BDV[Double] = exp(LDAUtils.dirichletExpectation(gammad)) // Kval expElogbetad = expElogbeta(ids, ::).toDenseMatrix // ids * K//根据公式(3.2.5)计算phi,这里加1e-100表示并非严格等于val phiNorm: BDV[Double] = expElogbetad * expElogthetad :+ 1e-100 // idsvar meanGammaChange = 1Dval ctsVector = new BDV[Double](cts) // ids// 迭代直至收敛while (meanGammaChange > 1e-3) {val lastgamma = gammad.copy//依据公式(3.2.5)计算gammagammad := (expElogthetad :* (expElogbetad.t * (ctsVector :/ phiNorm))) :+ alpha//根据更新的gamma,计算E(log theta)expElogthetad := exp(LDAUtils.dirichletExpectation(gammad))// 更新phiphiNorm := expElogbetad * expElogthetad :+ 1e-100//计算两次gamma的差值meanGammaChange = sum(abs(gammad - lastgamma)) / k}val sstatsd = expElogthetad.asDenseMatrix.t * (ctsVector :/ phiNorm).asDenseMatrix(gammad, sstatsd)}
- 3 更新
lambda
val statsSum: BDM[Double] = stats.map(_._1).reduce(_ += _)val gammat: BDM[Double] = breeze.linalg.DenseMatrix.vertcat(stats.map(_._2).reduce(_ ++ _).map(_.toDenseMatrix): _*)val batchResult = statsSum :* expElogbeta.t// 更新lambda和alphaupdateLambda(batchResult, (miniBatchFraction * corpusSize).ceil.toInt)
updateLambda方法实现 算法2 中的M-步,更新lambda。实现代码如下:
private def updateLambda(stat: BDM[Double], batchSize: Int): Unit = {// 根据公式(3.2.8)计算权重val weight = rho()// 更新lambda,其中stat * (corpusSize.toDouble / batchSize.toDouble)+eta表示rho_caplambda := (1 - weight) * lambda +weight * (stat * (corpusSize.toDouble / batchSize.toDouble) + eta)}// 根据公式(3.2.8)计算rhoprivate def rho(): Double = {math.pow(getTau0 + this.iteration, -getKappa)}
- 4 更新
alpha
private def updateAlpha(gammat: BDM[Double]): Unit = {//计算rhoval weight = rho()val N = gammat.rows.toDoubleval alpha = this.alpha.toBreeze.toDenseVector//计算log p_hatval logphat: BDM[Double] = sum(LDAUtils.dirichletExpectation(gammat)(::, breeze.linalg.*)) / N//计算梯度为N(-phi(alpha)+log p_hat)val gradf = N * (-LDAUtils.dirichletExpectation(alpha) + logphat.toDenseVector)//计算公式(3.3.4)中的c,trigamma表示gamma函数的二阶导数val c = N * trigamma(sum(alpha))//计算公式(3.3.4)中的qval q = -N * trigamma(alpha)//根据公式(3.3.7)计算bval b = sum(gradf / q) / (1D / c + sum(1D / q))val dalpha = -(gradf - b) / qif (all((weight * dalpha + alpha) :> 0D)) {alpha :+= weight * dalphathis.alpha = Vectors.dense(alpha.toArray)}}
5 参考文献
【1】LDA数学八卦
【2】通俗理解LDA主题模型
【3】Latent Dirichlet Allocation
【4】On Smoothing and Inference for Topic Models
【5】Online Learning for Latent Dirichlet Allocation
【6】Spark官方文档
【8】Maximum Likelihood Estimation of Dirichlet Distribution Parameters