
基本统计
MLlib支持RDD[Vector]列的概括统计,它通过调用Statistics的colStats方法实现。colStats返回一个MultivariateStatisticalSummary对象,这个对象包含列式的最大值、最小值、均值、方差等等。
下面是一个应用例子:
import org.apache.spark.mllib.linalg.Vectorimport org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}val observations: RDD[Vector] = ... // an RDD of Vectors// Compute column summary statistics.val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)println(summary.mean) // a dense vector containing the mean value for each columnprintln(summary.variance) // column-wise varianceprintln(summary.numNonzeros) // number of nonzeros in each column
下面我们具体看看colStats方法的实现。
def colStats(X: RDD[Vector]): MultivariateStatisticalSummary = {new RowMatrix(X).computeColumnSummaryStatistics()}
上面的代码非常明显,利用传人的RDD创建RowMatrix对象,利用方法computeColumnSummaryStatistics统计指标。
def computeColumnSummaryStatistics(): MultivariateStatisticalSummary = {val summary = rows.treeAggregate(new MultivariateOnlineSummarizer)((aggregator, data) => aggregator.add(data),(aggregator1, aggregator2) => aggregator1.merge(aggregator2))updateNumRows(summary.count)summary}
上面的代码调用了RDD的treeAggregate方法,treeAggregate是聚合方法,它迭代处理RDD中的数据,其中,(aggregator, data) => aggregator.add(data)处理每条数据,将其添加到MultivariateOnlineSummarizer,(aggregator1, aggregator2) => aggregator1.merge(aggregator2)将不同分区的MultivariateOnlineSummarizer对象汇总。所以上述代码实现的重点是add方法和merge方法。它们都定义在MultivariateOnlineSummarizer中。
我们先来看add代码。
@Since("1.1.0")def add(sample: Vector): this.type = add(sample, 1.0)private[spark] def add(instance: Vector, weight: Double): this.type = {if (weight == 0.0) return thisif (n == 0) {n = instance.sizecurrMean = Array.ofDim[Double](n)currM2n = Array.ofDim[Double](n)currM2 = Array.ofDim[Double](n)currL1 = Array.ofDim[Double](n)nnz = Array.ofDim[Double](n)currMax = Array.fill[Double](n)(Double.MinValue)currMin = Array.fill[Double](n)(Double.MaxValue)}val localCurrMean = currMeanval localCurrM2n = currM2nval localCurrM2 = currM2val localCurrL1 = currL1val localNnz = nnzval localCurrMax = currMaxval localCurrMin = currMininstance.foreachActive { (index, value) =>if (value != 0.0) {if (localCurrMax(index) < value) {localCurrMax(index) = value}if (localCurrMin(index) > value) {localCurrMin(index) = value}val prevMean = localCurrMean(index)val diff = value - prevMeanlocalCurrMean(index) = prevMean + weight * diff / (localNnz(index) + weight)localCurrM2n(index) += weight * (value - localCurrMean(index)) * difflocalCurrM2(index) += weight * value * valuelocalCurrL1(index) += weight * math.abs(value)localNnz(index) += weight}}weightSum += weightweightSquareSum += weight * weighttotalCnt += 1this}
这段代码使用了在线算法来计算均值和方差。根据文献【1】的介绍,计算均值和方差遵循如下的迭代公式:
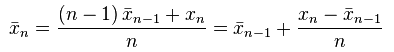
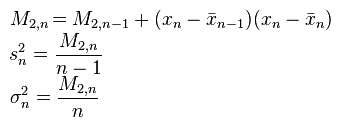
在上面的公式中,x表示样本均值,s表示样本方差,delta表示总体方差。MLlib实现的是带有权重的计算,所以使用的迭代公式略有不同,参考文献【2】。

merge方法相对比较简单,它只是对两个MultivariateOnlineSummarizer对象的指标作合并操作。
def merge(other: MultivariateOnlineSummarizer): this.type = {if (this.weightSum != 0.0 && other.weightSum != 0.0) {totalCnt += other.totalCntweightSum += other.weightSumweightSquareSum += other.weightSquareSumvar i = 0while (i < n) {val thisNnz = nnz(i)val otherNnz = other.nnz(i)val totalNnz = thisNnz + otherNnzif (totalNnz != 0.0) {val deltaMean = other.currMean(i) - currMean(i)// merge mean togethercurrMean(i) += deltaMean * otherNnz / totalNnz// merge m2n together,不单纯是累加currM2n(i) += other.currM2n(i) + deltaMean * deltaMean * thisNnz * otherNnz / totalNnz// merge m2 togethercurrM2(i) += other.currM2(i)// merge l1 togethercurrL1(i) += other.currL1(i)// merge max and mincurrMax(i) = math.max(currMax(i), other.currMax(i))currMin(i) = math.min(currMin(i), other.currMin(i))}nnz(i) = totalNnzi += 1}} else if (weightSum == 0.0 && other.weightSum != 0.0) {this.n = other.nthis.currMean = other.currMean.clone()this.currM2n = other.currM2n.clone()this.currM2 = other.currM2.clone()this.currL1 = other.currL1.clone()this.totalCnt = other.totalCntthis.weightSum = other.weightSumthis.weightSquareSum = other.weightSquareSumthis.nnz = other.nnz.clone()this.currMax = other.currMax.clone()this.currMin = other.currMin.clone()}this}
这里需要注意的是,在线算法的并行化实现是一种特殊情况。例如样本集X分到两个不同的分区,分别为X_A和X_B,那么它们的合并需要满足下面的公式:
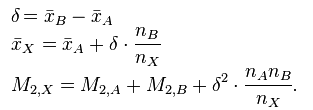
依靠文献【3】我们可以知道,样本方差的无偏估计由下面的公式给出:
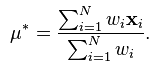
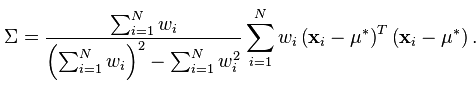
所以,真实的样本均值和样本方差通过下面的代码实现。
override def mean: Vector = {val realMean = Array.ofDim[Double](n)var i = 0while (i < n) {realMean(i) = currMean(i) * (nnz(i) / weightSum)i += 1}Vectors.dense(realMean)}override def variance: Vector = {val realVariance = Array.ofDim[Double](n)val denominator = weightSum - (weightSquareSum / weightSum)// Sample variance is computed, if the denominator is less than 0, the variance is just 0.if (denominator > 0.0) {val deltaMean = currMeanvar i = 0val len = currM2n.lengthwhile (i < len) {realVariance(i) = (currM2n(i) + deltaMean(i) * deltaMean(i) * nnz(i) *(weightSum - nnz(i)) / weightSum) / denominatori += 1}}Vectors.dense(realVariance)}
参考文献
【1】Algorithms for calculating variance