
7.6. 个案研究: 解析电话号码
7.6. 个案研究: 解析电话号码
迄今为止,你主要是匹配整个模式,不论是匹配上,还是没有匹配上。但是正则表达式还有比这更为强大的功能。当一个模式确实匹配上时,你可以获取模式中特定的片断,你可以发现具体匹配的位置。
这个例子来源于我遇到的另一个现实世界的问题,也是在以前的工作中遇到的。问题是:解析一个美国电话号码。客户要能(在一个单一的区域中)输入任何数字,然后存储区号,干线号,电话号和一个可选的独立的分机号到公司数据库里。为此,我通过网络找了很多正则表达式的例子,但是没有一个能够完全满足我的要求。
这里列举了我必须能够接受的电话号码:
- 800-555-1212
- 800 555 1212
- 800.555.1212
- (800) 555-1212
- 1-800-555-1212
- 800-555-1212-1234
- 800-555-1212x1234
- 800-555-1212 ext. 1234
- work 1-(800) 555.1212 #1234
格式可真够多的!我需要知道区号是800,干线号是555,电话号的其他数字为1212。对于那些有分机好的,我需要知道分机号我为 1234.
让我们完成电话号码解析这个工作,这个例子展示第一步。
例 7.10. 发现数字
>>> phonePattern = re.compile(r'^(\d{3})-(\d{3})-(\d{4})$') 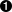 >>> phonePattern.search('800-555-1212').groups()
>>> phonePattern.search('800-555-1212').groups() 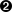 ('800', '555', '1212')
>>> phonePattern.search('800-555-1212-1234')
('800', '555', '1212')
>>> phonePattern.search('800-555-1212-1234')  >>>
>>>
| 通常是从左到右阅读正则表达式,这个正则表达式匹配字符串的开始,接着匹配(\d{3})。\d{3}是什么呢?好吧,{3} 的含义是“精确匹配三个数字”;是曾在前面见到过的{n,m} 语法的一种变形。\d 的含义是 “任何一个数字” (0 到 9)。把它们放大括号中意味着要“精确匹配三个数字位,接着把他们作为一个组保存下来,以便后面的调用”。接着匹配一个连字符,接着是另外一个精确匹配三个数字位的组,接着另外一个连字符,接着另外一个精确匹配四个数字为的组, 接着匹配字符串的结尾。 | |
| 为了访问正则表达式解析过程中记忆下来的多个组,我们使用 search 函数返回对象的groups()函数。这个函数将返回一个元组,元组中的元素就是正则表达式中定义的组。在这个例子中,定义了三个组,第一个组有三个数字位,第二个组有三个数字位,第三个组有四个数字位。 | |
| 这个正则表达式不是最终的答案,因为它不能处理在电话号码结尾有分机号的情况,为此,我们需要扩展这个正则表达式。 |
例 7.11. 发现分机号
>>> phonePattern = re.compile(r'^(\d{3})-(\d{3})-(\d{4})-(\d+)$') 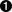 >>> phonePattern.search('800-555-1212-1234').groups()
>>> phonePattern.search('800-555-1212-1234').groups() 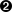 ('800', '555', '1212', '1234')
>>> phonePattern.search('800 555 1212 1234')
('800', '555', '1212', '1234')
>>> phonePattern.search('800 555 1212 1234')  >>>
>>> phonePattern.search('800-555-1212')
>>>
>>> phonePattern.search('800-555-1212')  >>>
>>>
| 这个正则表达式和上一个几乎相同,正像前面的那样,匹配字符串的开始,接着匹配一个有三个数字位的组并记忆下来,接着是一个连字符,接着是一个有三个数字位的组并记忆下来,接着是一个连字符,接着是一个有四个数字位的组并记忆下来。不同的地方是你接着又匹配了另一个连字符,然后是一个有一个或者多个数字位的组并记忆下来,最后是字符串的结尾。 | |
| 函数groups()现在返回一个有四个元素的元组,由于正则表达式中定义了四个记忆的组。 | |
| 不幸的是,这个正则表达式也不是最终的答案,因为它假设电话号码的不同部分是由连字符分割的。如果一个电话号码是由空格符、逗号或者点号分割呢?你需要一个更一般的解决方案来匹配几种不同的分割类型。 | |
| 啊呀!这个正则表达式不仅不能解决你想要的任何问题,反而性能更弱了,因为现在你甚至不能解析一个没有分机号的电话号码了。这根本不是你想要的,如果有分机号,你要知道分机号是什么,如果没有分机号,你仍然想要知道主电话号码的其他部分是什么。 |
下一个例子展示正则表达式处理一个电话号码内部,采用不同分割符的情况。
例 7.12. 处理不同分割符
>>> phonePattern = re.compile(r'^(\d{3})\D+(\d{3})\D+(\d{4})\D+(\d+)$')  >>> phonePattern.search('800 555 1212 1234').groups()
>>> phonePattern.search('800 555 1212 1234').groups()  ('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212-1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212-1234').groups()  ('800', '555', '1212', '1234')
>>> phonePattern.search('80055512121234')
('800', '555', '1212', '1234')
>>> phonePattern.search('80055512121234')  >>>
>>> phonePattern.search('800-555-1212')
>>>
>>> phonePattern.search('800-555-1212')  >>>
>>>
| 当心啦!你首先匹配字符串的开始,接着是一个三个数字位的组,接着是 \D+,这是个什么东西?好吧,\D匹配任意字符,除了数字位,+ 表示“1个或者多个”, 因此\D+ 匹配一个或者多个不是数字位的字符。这就是你替换连字符为了匹配不同分隔符所用的方法。 | |
| 使用\D+ 代替-意味着现在你可以匹配中间是空格符分割的电话号码了。 | |
| 当然,用连字符分割的电话号码也能够被识别。 | |
| 不幸的是,这个正则表达式仍然不是最终答案,因为他假设电话号码一定有分隔符。如果电话号码中间没有空格符或者连字符的情况会怎样哪? | |
| 我的天!这个正则表达式也没有达到我们对于分机号识别的要求。现在你共有两个问题,但是你可以利用相同的技术来解决他们。 |
下一个例子展示正则表达式处理没有分隔符的电话号码的情况。
例 7.13. 处理没有分隔符的数字
>>> phonePattern = re.compile(r'^(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$')  >>> phonePattern.search('80055512121234').groups()
>>> phonePattern.search('80055512121234').groups()  ('800', '555', '1212', '1234')
>>> phonePattern.search('800.555.1212 x1234').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800.555.1212 x1234').groups()  ('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()  ('800', '555', '1212', '')
>>> phonePattern.search('(800)5551212 x1234')
('800', '555', '1212', '')
>>> phonePattern.search('(800)5551212 x1234')  >>>
>>>
| 和上一步相比,你所做的唯一变化就是把所有的+ 变成 *。在电话号码的不同部分之间不再匹配 \D+ ,而是匹配\D*了。还记得 +的含义是“1或者多个”吗? 好的,*的含义是“0或者多个”。因此,现在你应该能够解析没有分割符的电话号码了。 | |
| 你瞧,它真的可以胜任。为什么?首先匹配字符串的开始,接着是一个有三个数字位 (800)的组,接着是0个非数字字符,接着是一个有三个数字位 (555)的组,接着是0个非数字字符,接着是一个有四个数字位 (1212)的组,接着是0个非数字字符,接着是一个有任意数字位 (1234)的组,最后是字符串的结尾。 | |
| 对于其他的变化也能够匹配:比如点号分割符,在分机号前面既有空格符又有 x 符号的情况也能够匹配。 | |
| 最后,你已经解决了长期存在的一个问题:现在分机号是可选的了。如果没有发现分机号,groups() 函数仍然返回一个有四个元素的元组,但是第四个元素只是一个空字符串。 | |
| 我不喜欢做一个坏消息的传递人,此时你还没有完全结束这个问题。还有什么问题呢?当在区号前面还有一个额外的字符时,而正则表达式假设区号是一个字符串的开始,因此不能匹配。这个不是问题,你可以利用相同的技术“0或者多个非数字字符”来跳过区号前面的字符。 |
下一个例子展示如何解决电话号码前面有其他字符的情况。
例 7.14. 处理开始字符
>>> phonePattern = re.compile(r'^\D*(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$')  >>> phonePattern.search('(800)5551212 ext. 1234').groups()
>>> phonePattern.search('(800)5551212 ext. 1234').groups() 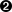 ('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212').groups()  ('800', '555', '1212', '')
>>> phonePattern.search('work 1-(800) 555.1212 #1234')
('800', '555', '1212', '')
>>> phonePattern.search('work 1-(800) 555.1212 #1234')  >>>
>>>
| 这个正则表达式和前面的几乎相同,除了在第一个记忆组(区号)前面匹配\D*,0或者多个非数字字符。注意,此处你没有记忆这些非数字字符(他们没有被括号括起来)。如果你发现他们,只是跳过他们,接着只要匹配上就开始记忆区号。 | |
| 你可以成功的解析电话号码,即使在区号前面有一个左括号。(在区号后面的右括号也已经被处理,它被看成非数字字符分隔符,由第一个记忆组后面的 \D*匹配。) | |
| 进行仔细的检查,保证你没有破坏前面能够匹配的任何情况。由于首字符是完全可选的,这个模式匹配字符串的开始,接着是0个非数字字符,接着是一个有三个数字字符的记忆组(800),接着是1个非数字字符(连字符),接着是一个有三个数字字符的记忆组(555),接着是1个非数字字符(连字符),接着是一个有四个数字字符的记忆组(1212),接着是0个非数字字符,接着是一个有0个数字位的记忆组,最后是字符串的结尾。 | |
| 此处是正则表达式让我产生了找一个硬东西挖出自己的眼睛的冲动。为什么这个电话号码没有匹配上?因为在它的区号前面有一个 1,但是你认为在区号前面的所有字符都是非数字字符(\D*)。 Aargh. |
让我们往回看一下。迄今为止,正则表达式总是从一个字符串的开始匹配。但是现在你看到了,有很多不确定的情况需要你忽略。与其尽力全部匹配他们,还不如全部跳过他们,让我们采用一个不同的方法:根本不显式的匹配字符串的开始。下面的这个例子展示这个方法。
例 7.15. 电话号码,无论何时我都要找到它
>>> phonePattern = re.compile(r'(\d{3})\D*(\d{3})\D*(\d{4})\D*(\d*)$') 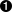 >>> phonePattern.search('work 1-(800) 555.1212 #1234').groups()
>>> phonePattern.search('work 1-(800) 555.1212 #1234').groups() 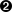 ('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')  ('800', '555', '1212', '')
>>> phonePattern.search('80055512121234')
('800', '555', '1212', '')
>>> phonePattern.search('80055512121234')  ('800', '555', '1212', '1234')
('800', '555', '1212', '1234')
| 注意,在这个正则表达式的开始少了一个^ 字符。你不再匹配字符串的开始了,也就是说,你需要用你的正则表达式匹配整个输入字符串,除此之外没有别的意思了。正则表达式引擎将要努力计算出开始匹配输入字符串的位置,并且从这个位置开始匹配。 | |
| 现在你可以成功解析一个电话号码了,不论这个电话号码的首字符是数字还是不是数字,还是在电话号码不同部分之间加上任意数目的任意类型的分隔符。 | |
| 仔细检查,这个正则表达式仍然工作的很好。 | |
| 还是能够工作。 |
看看一个正则表达式能够失控的多快?回头看看前面的例子,你还能区别他们么?
当你还能够理解这个最终答案的时候(这个正则表达式就是最终答案,即使你发现一种它不能处理的情况,我也真的不想知道它了),在你忘记为什么你这么选择之前,让我们把它写成松散正则表达式的形式。
例 7.16. 解析电话号码(最终版本)
>>> phonePattern = re.compile(r'''
# don't match beginning of string, number can start anywhere
(\d{3}) # area code is 3 digits (e.g. '800')
\D* # optional separator is any number of non-digits
(\d{3}) # trunk is 3 digits (e.g. '555')
\D* # optional separator
(\d{4}) # rest of number is 4 digits (e.g. '1212')
\D* # optional separator
(\d*) # extension is optional and can be any number of digits
$ # end of string
''', re.VERBOSE)
>>> phonePattern.search('work 1-(800) 555.1212 #1234').groups() 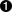 ('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')
('800', '555', '1212', '1234')
>>> phonePattern.search('800-555-1212')  ('800', '555', '1212', '')
('800', '555', '1212', '')
| 除了被分成多行,这个正则表达式和最后一步的那个完全相同,因此他能够解析相同的输入一点也不奇怪。 | |
| 进行最后的仔细检查。很好,仍然工作。你终于完成了这件任务。 |
关于正则表达式的进一步阅读
- Regular Expression HOWTO 讲解正则表达式和如何在Python中使用正则表达式。
- Python Library Reference 概述了re module.