
10.5. 通过节点类型创建独立的处理句柄 Creating separate handlers by node type
10.5. 通过节点类型创建独立的处理句柄 Creating separate handlers by node type
第三个有用的 XML 处理技巧是将你的代码基于节点类型和元素名称分散到逻辑函数中。解析后的 XML 文档是由各种类型的节点组成的,每一个都是通过 Python 对象表示的。文档本身的根层次通过一个Document对象表示。Document还包含了一个或者多个Element对象(for actual XML tags),其中的每一个可以包含其它的Element对象,Text对象(for bits of text),或者Comment对象(for embedded comments)。 Python 使编写分离每个节点类型逻辑的分发器非常容易。
例 10.17. 已解析 XML 对象的类名
>>> from xml.dom import minidom
>>> xmldoc = minidom.parse('kant.xml') 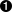 >>> xmldoc
<xml.dom.minidom.Document instance at 0x01359DE8>
>>> xmldoc.__class__
>>> xmldoc
<xml.dom.minidom.Document instance at 0x01359DE8>
>>> xmldoc.__class__ 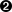 <class xml.dom.minidom.Document at 0x01105D40>
>>> xmldoc.__class__.__name__
<class xml.dom.minidom.Document at 0x01105D40>
>>> xmldoc.__class__.__name__  'Document'
'Document'| 暂时假设kant.xml在当前目录中。 | |
| 正如你在第 9.2 节 “包”中看到的,解析 XML 文档返回的对象是一个Document对象,就像在xml.dom包的minidom.py中定义的一样。又如你在第 5.4 节 “类的实例化”中看到的,__class__是每个 Python 对象的一个内置属性。 | |
| 此外,__name__是每个 Python 类的内置属性,是一个字符串。这个字符串并不神秘;它和你在定义类时输入的类名相同。(参见第 5.3 节 “类的定义”。) |
好,现在你能够得到任何特定 XML 节点的类名了(因为每个 XML 节点都是以一个 Python 对象表示的)。你怎样才能利用这点来分离解析每个节点类型的逻辑呢?答案就是 getattr,你第一次见它是在第 4.4 节 “通过 getattr 获取对象引用”中。
例 10.18. parse, 一个通用的 XML 节点分发器
def parse(self, node):
parseMethod = getattr(self, "parse_%s" % node.__class__.__name__) 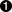
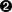 parseMethod(node)
parseMethod(node) 
| First off, 注意你正在基于传入节点(在node参数中)的类名构造一个较大的字符串。所以如果你传入一个Document节点,你就构造了字符串'parse_Document',其它类同于此。 | |
| 现在你可以把这个字符串当作一个函数名称,然后通过 getattr 得到函数自身的引用。 | |
| 最后,你可以调用函数并将节点自身作为参数传入。下一个例子将展示每个函数的定义。 |
例 10.19. parse分发者调用的函数
def parse_Document(self, node):  self.parse(node.documentElement)
def parse_Text(self, node):
self.parse(node.documentElement)
def parse_Text(self, node):  text = node.data
if self.capitalizeNextWord:
self.pieces.append(text[0].upper())
self.pieces.append(text[1:])
self.capitalizeNextWord = 0
else:
self.pieces.append(text)
def parse_Comment(self, node):
text = node.data
if self.capitalizeNextWord:
self.pieces.append(text[0].upper())
self.pieces.append(text[1:])
self.capitalizeNextWord = 0
else:
self.pieces.append(text)
def parse_Comment(self, node):  pass
def parse_Element(self, node):
pass
def parse_Element(self, node):  handlerMethod = getattr(self, "do_%s" % node.tagName)
handlerMethod(node)
handlerMethod = getattr(self, "do_%s" % node.tagName)
handlerMethod(node)| parse_Document只会被调用一次,因为在一个 XML 文档中只有一个Document节点,并且在已解析 XML 的表示中只有一个Document对象。它只是turn around并解析语法文件的根元素。 | |
| parse_Text 在节点表示文本时被调用。这个函数本身做某种特殊处理,自动将句子的第一个单词进行大写处理,而不是简单的将表示的文本追加到一个列表中。 | |
| parse_Comment 只有一个pass,因为你并不关心语法文件中嵌入的注释。但是注意,你还是要定义这个函数并显式的让它不做任何事情。如果这个函数不存在,通用parse函数在遇到一个注释的时候,会执行失败,因为它试图找到并不存在的parse_Comment函数。为每个节点类型定义独立的函数,甚至你不要使用的,将会使通用parse函数保持简单和沉默。 | |
| parse_Element方法其实本身就是一个分发器,它基于元素的标记名称。这个基本概念是相同的:使用元素的区别(它们的标记名称)然后针对每一个分发到一个独立的函数。你构建了一个类似于'do_xref'的字符串(对<xref>标记而言),找到这个名称的函数,并调用它。对其它的标记名称在解析语法文件的时候都可以找到类似的函数(<p>标记,<choice>标记)。 |
在这个例子中,分发函数parse和parse_Element只是找到相同类中的其它方法。如果你进行的处理过程很复杂(或者你有很多不同的标记名称),你可以将代码分散到独立的模块中,然后使用动态导入的方式导入每个模块并调用你需要的任何函数。动态导入将在第 16 章 有效编程(Functional Programming)中介绍。