
12.7. 搜索 Google
12.7. 搜索 Google
让我们回到这章开始时你看到的那段代码,获得比当前气温更有价值和令人振奋的信息。
Google 提供了一个 SOAP API ,以便通过程序进行 Google 搜索。使用它的前提是,你注册了 Google 网络服务。
过程 12.4. 注册 Google 网络服务
访问 http://www.google.com/apis/ 并创建一个账号。 唯一的需要是提供一个 E-mail 地址。 注册之后,你将通过 E-mail 收到你的 Google API 许可证(license key)。 你需要在调用 Google 搜索函数时使用这个许可证。
还是在 http://www.google.com/apis/ 上,下载 Google 网络 APIs 开发工具包(kit)。它包含着包括 Python 在内的多种语言的样例代码,更重要的是它包含着 WSDL 文件。
解压这个开发工具包并找到 GoogleSearch.wsdl。将这个文件拷贝到你本地驱动器的一个永久地址。在本章后面位置你会用到它。
你有了开发许可证和 Google WSDL 文件之后就可以和 Google 网络服务打交道了。
例 12.12. 内省 Google 网络服务
>>> from SOAPpy import WSDL
>>> server = WSDL.Proxy('/path/to/your/GoogleSearch.wsdl') 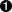 >>> server.methods.keys()
>>> server.methods.keys() 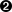 [u'doGoogleSearch', u'doGetCachedPage', u'doSpellingSuggestion']
>>> callInfo = server.methods['doGoogleSearch']
>>> for arg in callInfo.inparams:
[u'doGoogleSearch', u'doGetCachedPage', u'doSpellingSuggestion']
>>> callInfo = server.methods['doGoogleSearch']
>>> for arg in callInfo.inparams:  ... print arg.name.ljust(15), arg.type
key (u'http://www.w3.org/2001/XMLSchema', u'string')
q (u'http://www.w3.org/2001/XMLSchema', u'string')
start (u'http://www.w3.org/2001/XMLSchema', u'int')
maxResults (u'http://www.w3.org/2001/XMLSchema', u'int')
filter (u'http://www.w3.org/2001/XMLSchema', u'boolean')
restrict (u'http://www.w3.org/2001/XMLSchema', u'string')
safeSearch (u'http://www.w3.org/2001/XMLSchema', u'boolean')
lr (u'http://www.w3.org/2001/XMLSchema', u'string')
ie (u'http://www.w3.org/2001/XMLSchema', u'string')
oe (u'http://www.w3.org/2001/XMLSchema', u'string')
... print arg.name.ljust(15), arg.type
key (u'http://www.w3.org/2001/XMLSchema', u'string')
q (u'http://www.w3.org/2001/XMLSchema', u'string')
start (u'http://www.w3.org/2001/XMLSchema', u'int')
maxResults (u'http://www.w3.org/2001/XMLSchema', u'int')
filter (u'http://www.w3.org/2001/XMLSchema', u'boolean')
restrict (u'http://www.w3.org/2001/XMLSchema', u'string')
safeSearch (u'http://www.w3.org/2001/XMLSchema', u'boolean')
lr (u'http://www.w3.org/2001/XMLSchema', u'string')
ie (u'http://www.w3.org/2001/XMLSchema', u'string')
oe (u'http://www.w3.org/2001/XMLSchema', u'string')
| 步入 Google 网络服务很简单:建立一个 WSDL.Proxy 对象并指向到你复制到本地的 Google WSDL 文件。 | |
| 由 WSDL 文件可知,Google 提供三个函数:doGoogleSearch, doGetCachedPage 和 doSpellingSuggestion。顾名思义,执行 Google 搜索并返回结果,获得 Google 最后一次扫描该页时获得的缓存,为基于常见拼写错误提出单词拼写建议。 | |
| doGoogleSearch 函数需要一系列不同类型的参数。注意: WSDL 文件可以告诉你有哪些参数和他们的参数类型,但不能告诉你它们的含义和使用方法。在参数值有限定的情况下,理论上它能够告诉你参数的取值范围,但 Google 的 WSDL 没有那么细化。 WSDL.Proxy 不会变魔术,它只能给你 WSDL 文件中提供的信息。 |
这里简要地列出了 doGoogleSearch 函数的所有参数:
- key —— 你注册 Google 网络服务时获得的 Google API 许可证。
- q —— 你要搜索的词或词组。其语法与 Google 的网站表单处完全相同,你所知道的高级搜索语法和技巧这里完全适用。
- start —— 起始的结果编号。与使用 Google 网页交互搜索时相同,这个函数每次返回10个结果。如果你需要查看 “第二” 页结果则需要将 start 设置为10。
- maxResults —— 返回的结果个数。目前的值是10,当然如果你只对少数返回结果感兴趣或者希望节省网络带宽,也可以定义为返回更少的结果。
- filter —— 如果设置为 True,Google 将会过滤结果中重复的页面。
- restrict —— 这里设置 country 并跟上一个国家代码可以限定只返回特定国家的结果。例如: countryUK 用于在英国搜索页面。你也可以设定 linux, mac 或者 bsd 以便搜索 Google 定义的技术站点组,或者设为 unclesam 来搜索美国政府站点。
- safeSearch —— 如果设置为 True, Google 将会过滤掉色情站点。
- lr (“语言限制”) —— 这里设置语言限定值返回特定语言的站点。
- ie and oe (“输入编码” 和 “输出编码”) —— 不赞成使用,都应该是 utf-8。
例 12.13. 搜索 Google
>>> from SOAPpy import WSDL
>>> server = WSDL.Proxy('/path/to/your/GoogleSearch.wsdl')
>>> key = 'YOUR_GOOGLE_API_KEY'
>>> results = server.doGoogleSearch(key, 'mark', 0, 10, False, "",
... False, "", "utf-8", "utf-8") 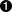 >>> len(results.resultElements)
>>> len(results.resultElements) 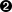 10
>>> results.resultElements[0].URL
10
>>> results.resultElements[0].URL  'http://diveintomark.org/'
>>> results.resultElements[0].title
'dive into <b>mark</b>'
'http://diveintomark.org/'
>>> results.resultElements[0].title
'dive into <b>mark</b>'
| 在设置好 WSDL.Proxy 对象之后,你可以使用十个参数来调用 server.doGoogleSearch。 记住在要使用你注册 Google 网络服务时授权给你自己的 Google API 许可证。 | |
| 有很多的返回信息,但我们还是先来看一下实际的返回结果。它们被存储于 results.resultElements 之中,你可以像使用普通的 Python 列表那样来调用它。 | |
| resultElements 中的每个元素都是一个包含 URL, title, snippet 以及其他属性的对象。基于这一点,你可以使用诸如 dir(results.resultElements[0]) 的普通 Python 自省技术来查看有效属性,或者通过 WSDL proxy 对象查看函数的 outparams。 不同的方法能带给你相同的结果。 |
results 对象中所加载的不仅仅是实际的搜索结果。 它也含有搜索行为自身的信息,比如耗时和总结果数等(尽管只返回了10条结果)。 Google 网页界面中显示了这些信息,通过程序你也同样能获得它们。
例 12.14. 从Google获得次要信息
>>> results.searchTime0.224919 >>> results.estimatedTotalResultsCount
29800000 >>> results.directoryCategories
[<SOAPpy.Types.structType item at 14367400>: {'fullViewableName': 'Top/Arts/Literature/World_Literature/American/19th_Century/Twain,_Mark', 'specialEncoding': ''}] >>> results.directoryCategories[0].fullViewableName 'Top/Arts/Literature/World_Literature/American/19th_Century/Twain,_Mark'
| 这个搜索耗时 0.224919 秒。这不包括用于发送和接收 SOAP XML 文档的时间,仅仅是 Google 在接到搜索请求后执行搜索所花费的时间。 | |
| 总共有接近30,000,000个结果信息,你可以通过以 10 递增地改变 start 参数来重复调用 server.doGoogleSearch 。 | |
| 对于有些请求,Google 还返回一个 Google Directory 中的类别列表。你可以用这些 URLs 到 http://directory.google.com/ 建立到 directory category 页面的链接。 |