
7.2. 个案研究:街道地址
7.2. 个案研究:街道地址
这一系列的例子是由我几年前日常工作中的现实问题启发而来的,当时我需要从一个老化系统中导出街道地址,在将他们导入新的系统之前,进行清理和标准化。(看,我不是只将这些东西堆到一起,他有实际的用处)。这个例子展示我如何处理这个问题。
例 7.1. 在字符串的结尾匹配
>>> s = '100 NORTH MAIN ROAD'
>>> s.replace('ROAD', 'RD.') 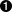 '100 NORTH MAIN RD.'
>>> s = '100 NORTH BROAD ROAD'
>>> s.replace('ROAD', 'RD.')
'100 NORTH MAIN RD.'
>>> s = '100 NORTH BROAD ROAD'
>>> s.replace('ROAD', 'RD.') 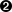 '100 NORTH BRD. RD.'
>>> s[:-4] + s[-4:].replace('ROAD', 'RD.')
'100 NORTH BRD. RD.'
>>> s[:-4] + s[-4:].replace('ROAD', 'RD.')  '100 NORTH BROAD RD.'
>>> import re
'100 NORTH BROAD RD.'
>>> import re  >>> re.sub('ROAD$', 'RD.', s)
>>> re.sub('ROAD$', 'RD.', s) 
 '100 NORTH BROAD RD.'
'100 NORTH BROAD RD.'| 我的目标是将街道地址标准化,'ROAD'通常被略写为'RD.'。乍看起来,我以为这个太简单了,只用字符串的方法replace就可以了。毕竟,所有的数据都已经是大写的了,因此大小写不匹配将不是问题。并且,要搜索的串'ROAD'是一个常量,在这个迷惑的简单例子中,s.replace的确能够胜任。 | |
| 不幸的是,生活充满了特例,并且我很快就意识到这个问题。比如:'ROAD'在地址中出现两次,一次是作为街道名称'BROAD'的一部分,一次是作为'ROAD'本身。replace方法遇到这两处的'ROAD'并没有区别,因此都进行了替换,而我发现地址被破坏掉了。 | |
| 为了解决在地址中出现多次'ROAD'子串的问题,有可能采用类似这样的方法:只在地址的最后四个字符中搜索替换'ROAD'(s[-4:]),忽略字符串的其他部分(s[:-4])。但是,你可能发现这已经变得不方便了。例如,该模式依赖于你要替换的字符串的长度了(如果你要把'STREET'替换为'ST.',你需要利用s[:-6]和s[-6:].replace(...))。你愿意在六月个期间回来调试他们么?我本人是不愿意的。 | |
| 是时候转到正则表达式了。在Python中,所有和正则表达式相关的功能都包含在re模块中。 | |
| 来看第一个参数:'ROAD$'。这个正则表达式非常简单,只有当'ROAD'出现在一个字符串的尾部时才会匹配。字符$表示“字符串的末尾”(还有一个对应的字符,尖号^,表示“字符串的开始”)。 | |
| 利用re.sub函数,对字符串s进行搜索,满足正则表达式'ROAD$'的用'RD.'替换。这样将匹配字符串s末尾的'ROAD',而不会匹配属于单词'ROAD'一部分的'ROAD',这是因为它是出现在s的中间。 |
继续我的清理地址的故事,很快,我发现上面的例子,仅仅匹配地址末尾的'ROAD'不是很好,因为不是所有的地址都包括一个街道的命名;有一些是以街道名结尾的。大部分情况下,不会遇到这种情况,但是,如果街道名称为'BROAD',那么正则表达式将会匹配'BROAD'的一部分为'ROAD',而这并不是我想要的。
例 7.2. 匹配整个单词
>>> s = '100 BROAD'
>>> re.sub('ROAD$', 'RD.', s)
'100 BRD.'
>>> re.sub('\\bROAD$', 'RD.', s) 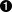 '100 BROAD'
>>> re.sub(r'\bROAD$', 'RD.', s)
'100 BROAD'
>>> re.sub(r'\bROAD$', 'RD.', s) 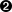 '100 BROAD'
>>> s = '100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD$', 'RD.', s)
'100 BROAD'
>>> s = '100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD$', 'RD.', s)  '100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD\b', 'RD.', s)
'100 BROAD ROAD APT. 3'
>>> re.sub(r'\bROAD\b', 'RD.', s)  '100 BROAD RD. APT 3'
'100 BROAD RD. APT 3'| 我真正想要做的是,当'ROAD'出现在字符串的末尾,并且是作为一个独立的单词时,而不是一些长单词的一部分,才对他进行匹配。为了在正则表达式中表达这个意思,你利用\b,它的含义是“单词的边界必须在这里”。在Python中,由于字符'\'在一个字符串中必须转义这个事实,从而变得非常麻烦。有时候,这类问题被称为“反斜线灾难”,这也是Perl中正则表达式比Python的正则表达式要相对容易的原因之一。另一方面,Perl也混淆了正则表达式和其他语法,因此,如果你发现一个bug,很难弄清楚究竟是一个语法错误,还是一个正则表达式错误。 | |
| 为了避免反斜线灾难,你可以利用所谓的“原始字符串”,只要为字符串添加一个前缀 'r' 就可以了。这将告诉Python,字符串中的所有字符都不转义;'\t'是一个制表符,而r'\t'是一个真正的反斜线字符'\',紧跟着一个字母 't' 。我推荐只要处理正则表达式,就使用原始字符串;否则,事情会很快变得混乱(并且正则表达式自己也会很快被自己搞乱了)。 | |
| (一声叹息),很不幸,我很快发现更多的与我的逻辑相矛盾的例子。在这个例子中,街道地址包含有作为整个单词的'ROAD',但是他不是在末尾,因为地址在街道命名后会有一个房间号。由于'ROAD'不是在每一个字符串的末尾,没有匹配上,因此调用re.sub没有替换任何东西,你获得的知识初始字符串,这也不是我们想要的。 | |
| 为了解决这个问题,我去掉了$字符,加上另一个\b。现在,正则表达式“匹配字符串中作为整个单词出现的'ROAD'了”,不论是在末尾、开始还是中间。 |