
15.3. 重构
15.3. 重构
全面的单元测试带来的最大好处不是你的全部测试用例最终通过时的成就感;也不是被责怪破坏了别人的代码时能够证明自己的自信。最大的好处是单元测试给了你自由去无情地重构。
重构是在可运行代码的基础上使之更良好工作的过程。 通常,“更好”意味着“更快”,也可能意味着 “使用更少的内存”,或者 “使用更少的磁盘空间”,或者仅仅是“更优雅的代码”。 不管对你,对你的项目意味什么,在你的环境中,重构对任何程序的长期良性运转都是重要的。
这里, “更好” 意味着 “更快”。更具体地说, fromRoman 函数可以更快,关键在于那个丑陋的、用于验证罗马数字有效性的正则表达式。尝试不用正则表达式去解决是不值得的(这样做很难,而且可能也快不了多少),但可以通过预编译正则表达式使函数提速。
例 15.10. 编译正则表达式
>>> import re >>> pattern = '^M?M?M?$' >>> re.search(pattern, 'M')<SRE_Match object at 01090490> >>> compiledPattern = re.compile(pattern)
>>> compiledPattern <SRE_Pattern object at 00F06E28> >>> dir(compiledPattern)
['findall', 'match', 'scanner', 'search', 'split', 'sub', 'subn'] >>> compiledPattern.search('M')
<SRE_Match object at 01104928>
| 这是你曾在 re.search 中看到的语法。 把一个正则表达式作为字符串(pattern)并用这个字符串来匹配('M')。 如果能够匹配,函数返回 一个 match 对象,可以用来确定匹配的部分和如何匹配的。 | |
| 这里是一个新的语法: re.compile 把一个正则表达式作为字符串参数接受并返回一个 pattern 对象。注意这里没去匹配字符串。编译正则表达式和以特定字符串('M')进行匹配不是一回事,所牵扯的只是正则表达式本身。 | |
| re.compile 返回已编译的 pattern 对象有几个值得关注的功能:包括了几个 re 模块直接提供的功能(比如: search 和 sub)。 | |
| 用 'M' 作参数来调用已编译的 pattern 对象的 search 函数与用正则表达式和字符串 'M' 调用 re.search 可以得到相同的结果,只是快了很多。(事实上,re.search 函数仅仅将正则表达式编译,然后为你调用编译后的 pattern 对象的 search 方法。) |
| 在需要多次使用同一个正则表达式的情况下,应该将它进行编译以获得一个 pattern 对象,然后直接调用这个 pattern 对象的方法。 | |
例 15.11. roman81.py 中已编译的正则表达式
这个文件可以在例子目录下的 py/roman/stage8/ 目录中找到。
如果您还没有下载本书附带的例子程序, 可以 下载本程序和其他例子程序。
# toRoman and rest of module omitted for clarity
romanNumeralPattern = \
re.compile('^M?M?M?M?(CM|CD|D?C?C?C?)(XC|XL|L?X?X?X?)(IX|IV|V?I?I?I?)$') 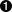 def fromRoman(s):
"""convert Roman numeral to integer"""
if not s:
raise InvalidRomanNumeralError, 'Input can not be blank'
if not romanNumeralPattern.search(s):
def fromRoman(s):
"""convert Roman numeral to integer"""
if not s:
raise InvalidRomanNumeralError, 'Input can not be blank'
if not romanNumeralPattern.search(s): 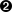 raise InvalidRomanNumeralError, 'Invalid Roman numeral: %s' % s
result = 0
index = 0
for numeral, integer in romanNumeralMap:
while s[index:index+len(numeral)] == numeral:
result += integer
index += len(numeral)
return result
raise InvalidRomanNumeralError, 'Invalid Roman numeral: %s' % s
result = 0
index = 0
for numeral, integer in romanNumeralMap:
while s[index:index+len(numeral)] == numeral:
result += integer
index += len(numeral)
return result
| 看起来很相似,但实质却有很大改变。 romanNumeralPattern 不再是一个字符串了,而是一个由 re.compile 返回的 pattern 对象。 | |
| 这意味着你可以直接调用 romanNumeralPattern 的方法。这比每次调用 re.search 要快很多。 模块被首次导入(import)之时,正则表达式被一次编译并存储于 romanNumeralPattern。 之后每次调用 fromRoman 时,你可以立刻以正则表达式匹配输入的字符串,而不需要在重复背后的这些编译的工作。 |
那么编译正则表达式可以提速多少呢? 你自己来看吧:
例 15.12. 用 romantest81.py 测试 roman81.py 的结果
.............---------------------------------------------------------------------- Ran 13 tests in 3.385s
OK
| 有一点说明一下:这里,我在运行单元测试时没有使用 -v 选项,因此输出的也不再是每个测试完整的 doc string,而是用一个圆点来表示每个通过的测试。(失败的测试标用 F 表示, 发生错误则用 E 表示, 你仍旧可以获得失败和错误的完整追踪信息以便查找问题所在。) | |
| 运行 13 个测试耗时 3.385 秒,与之相比是没有预编译正则表达式时的 3.685秒。这是一个 8% 的整体提速,记住单元测试的大量时间实际上花在做其他工作上。(我单独测试了正则表达式部分的耗时,不考虑单元测试的其他环节,正则表达式编译可以让匹配 search 平均提速 54% 。)小小修改还真是值得。 | |
| 对了,不必顾虑什么,预先编译正则表达式并没有破坏什么,你刚刚证实这一点。 |
我还想做另外一个性能优化工作。就正则表达式语法的复杂性而言,通常有不止一种方法来构造相同的表达式是不会令人惊讶的。 在 comp.lang.python 上对该模块进行一些讨论后,有人建议我使用 {m,n} 语法来查找可选重复字符。
例 15.13. roman82.py
这个文件可以在例子目录下的 py/roman/stage8/ 目录中找到。
如果您还没有下载本书附带的例子程序, 可以 下载本程序和其他例子程序。
# rest of program omitted for clarity
#old version
#romanNumeralPattern = \
# re.compile('^M?M?M?M?(CM|CD|D?C?C?C?)(XC|XL|L?X?X?X?)(IX|IV|V?I?I?I?)$')
#new version
romanNumeralPattern = \
re.compile('^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$') 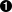
| 你已经将 M?M?M?M? 替换为 M{0,4}。 它们的含义相同: “匹配 0 到 4 个 M 字符”。 类似地, C?C?C? 改成了 C{0,3} (“匹配 0 到 3 个 C 字符”) 接下来的 X 和 I 也一样。 |
这样的正则表达简短一些 (虽然可读性不太好)。 核心问题是,是否能加快速度?
例 15.14. 以 romantest82.py 测试 roman82.py 的结果
............. ---------------------------------------------------------------------- Ran 13 tests in 3.315sOK
| 总体而言, 这种正则表达使单元测试提速 2%。 这不太令人振奋,但记住 search 函数只是整体单元测试的一个小部分,很多时间花在了其他方面。 (我另外的测试表明这个应用了新语法的正则表达式使 search 函数提速 11% 。) 通过预先编译和使用新语法重写可以使正则表达式的性能提升超过 60%,另单元测试的整体性能提升超过 10%. | |
| 比任何的性能提升更重要的是模块仍然运转完好。 这便是我早先提到的自由:自由地调整、修改或者重写任何部分并且保证在此过程中没有把事情搞得一团糟。 这并不是给只是为了调整代码而无休止地调整以许可,你有很切实的目标(“让 fromRoman 更快”),而且你可以实现这个目标,不会因为考虑在改动过程中是否会引入新的 Bug 而有所迟疑。 |
还有另外一个我想做的调整,我保证这是最后一个,之后我会停下来,让这个模块歇歇。就像你多次看到的,正则表达式越晦涩难懂越快,我可不想在六个月内再回头试图维护它。是呀!测试用例通过了,我便知道它工作正常,但如果我搞不懂它是如何工作的,添加新功能,修正新 Bug,或者维护它都将变得很困难。 正如你在 第 7.5 节 “松散正则表达式”, 看到的, Python 提供了逐行注释你的逻辑的方法。
例 15.15. roman83.py
该文件可以在例子目录下的 py/roman/stage8/ 目录中找到。
如果您还没有下载本书附带的例子程序, 可以 下载本程序和其他例子程序。
# rest of program omitted for clarity
#old version
#romanNumeralPattern = \
# re.compile('^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$')
#new version
romanNumeralPattern = re.compile('''
^ # beginning of string
M{0,4} # thousands - 0 to 4 M's
(CM|CD|D?C{0,3}) # hundreds - 900 (CM), 400 (CD), 0-300 (0 to 3 C's),
# or 500-800 (D, followed by 0 to 3 C's)
(XC|XL|L?X{0,3}) # tens - 90 (XC), 40 (XL), 0-30 (0 to 3 X's),
# or 50-80 (L, followed by 0 to 3 X's)
(IX|IV|V?I{0,3}) # ones - 9 (IX), 4 (IV), 0-3 (0 to 3 I's),
# or 5-8 (V, followed by 0 to 3 I's)
$ # end of string
''', re.VERBOSE) 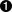
| re.compile 函数的第二个参数是可选的,这个参数通过一个或一组选项设置来控制预编译正则表达式的多样化选项。这里你指定了 re.VERBOSE 选项,告诉 Python 正则表达式里有行内的注释。注释和他们周围的空白不会被认做正则表达式的一部分,在编译正则表达式时 re.compile 函数会忽略它们。这个新 “verbose” 版本与老版本完全一样,只是更具可读性。 |
例 15.16. 用 romantest83.py 测试 roman83.py 的结果
............. ---------------------------------------------------------------------- Ran 13 tests in 3.315sOK
| 新 “verbose” 版本和老版本的运行速度一样。 事实上, 编译的 pattern 对象也一样,因为 re.compile 函数剔除掉所有你添加的内容。 | |
| 新 “verbose” 版本可以通过所有老版本通过的测试。 什么都没有改变,但在六个月后重读该模块的程序员却有了理解功能如何实现的机会。 |