
最优化算法 - 拟牛顿法
设f(x)是二次可微实函数,又设$x^{(k)}$是f(x)一个极小点的估计,我们把f(x)在$x^{(k)}$处展开成Taylor级数,
并取二阶近似。
上式中最后一项的中间部分表示f(x)在$x^{(k)}$处的Hesse矩阵。对上式求导并令其等于0,可以的到下式:
设Hesse矩阵可逆,由上式可以得到牛顿法的迭代公式如下 (1.1)
值得注意 , 当初始点远离极小点时,牛顿法可能不收敛。原因之一是牛顿方向不一定是下降方向,经迭代,目标函数可能上升。此外,即使目标函数下降,得到的点也不一定是沿牛顿方向最好的点或极小点。
因此,我们在牛顿方向上增加一维搜索,提出阻尼牛顿法。其迭代公式是 (1.2):
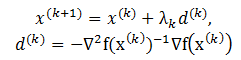
其中,lambda是由一维搜索(参考文献【1】了解一维搜索)得到的步长,即满足
2 拟牛顿法
2.1 拟牛顿条件
前面介绍了牛顿法,它的突出优点是收敛很快,但是运用牛顿法需要计算二阶偏导数,而且目标函数的Hesse矩阵可能非正定。为了克服牛顿法的缺点,人们提出了拟牛顿法,它的基本思想是用不包含二阶导数的矩阵近似牛顿法中的Hesse矩阵的逆矩阵。
由于构造近似矩阵的方法不同,因而出现不同的拟牛顿法。
下面分析怎样构造近似矩阵并用它取代牛顿法中的Hesse矩阵的逆。上文 (1.2) 已经给出了牛顿法的迭代公式,为了构造Hesse矩阵逆矩阵的近似矩阵$H_{(k)}$ ,需要先分析该逆矩阵与一阶导数的关系。
设在第k次迭代之后,得到$x^{(k+1)}$ ,我们将目标函数f(x)在点$x^{(k+1)}$展开成Taylor级数,
并取二阶近似,得到
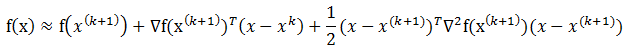
由此可知,在$x^{(k+1)}$附近有,
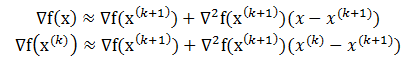
记
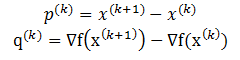
则有
又设Hesse矩阵可逆,那么上式可以写为如下形式。
这样,计算出p和q之后,就可以通过上面的式子估计Hesse矩阵的逆矩阵。因此,为了用不包含二阶导数的矩阵$H{(k+1)}$取代牛顿法中Hesse矩阵的逆矩阵,有理由令$H{(k+1)}$满足公式 (2.1) :
公式(2.1)称为拟牛顿条件。
2.2 秩1校正
当Hesse矩阵的逆矩阵是对称正定矩阵时,满足拟牛顿条件的矩阵$H{(k)}$也应该是对称正定矩阵。构造这样近似矩阵的一般策略是,$H{(1)}$取为任意一个n阶对称正定矩阵,通常选择n阶单位矩阵I,然后通过修正$H{(k)}$给定$H{(k+1)}$。
令,
秩1校正公式写为如下公式(2.2)形式。
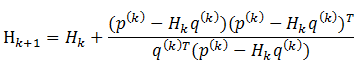
2.3 DFP算法
著名的DFP方法是Davidon首先提出,后来又被Feltcher和Powell改进的算法,又称为变尺度法。在这种方法中,定义校正矩阵为公式 (2.3)
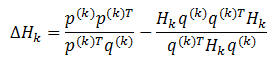
那么得到的满足拟牛顿条件的DFP公式如下 (2.4)
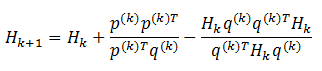
查看文献【1】,了解DFP算法的计算步骤。
2.4 BFGS算法
前面利用拟牛顿条件 (2.1) 推导出了DFP公式 (2.4) 。下面我们用不含二阶导数的矩阵$B_{(k+1)}$近似Hesse矩阵,从而给出另一种形式的拟牛顿条件 (2.5) :
将公式 (2.1) 的H换为B,p和q互换正好可以得到公式 (2.5) 。所以我们可以得到B的修正公式 (2.6) :
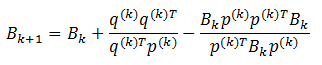
这个公式称关于矩阵B的BFGS修正公式,也称为DFP公式的对偶公式。设$B_{(k+1)}$可逆,由公式 (2.1) 以及 (2.5) 可以推出:
这样可以得到关于H的BFGS公式为下面的公式 (2.7):
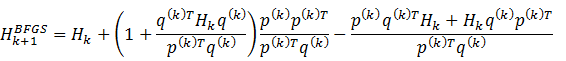
这个重要公式是由Broyden,Fletcher,Goldfard和Shanno于1970年提出的,所以简称为BFGS。数值计算经验表明,它比DFP公式还好,因此目前得到广泛应用。
2.5 L-BFGS(限制内存BFGS)算法
在BFGS算法中,仍然有缺陷,比如当优化问题规模很大时,矩阵的存储和计算将变得不可行。为了解决这个问题,就有了L-BFGS算法。L-BFGS即Limited-memory BFGS。L-BFGS的基本思想是只保存最近的m次迭代信息,从而大大减少数据的存储空间。对照BFGS,重新整理一下公式:
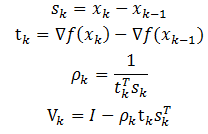
之前的BFGS算法有如下公式(2.8)

那么同样有
将该式子带入到公式(2.8)中,可以推导出如下公式
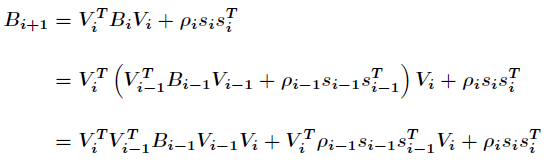
假设当前迭代为k,只保存最近的m次迭代信息,按照上面的方式迭代m次,可以得到如下的公式(2.9)
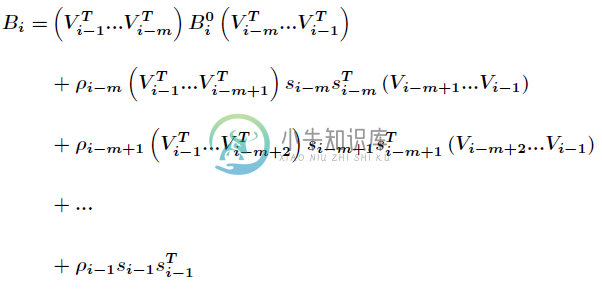
上面迭代的最终目的就是找到k次迭代的可行方向,即
为了求可行方向r,可以使用two-loop recursion算法来求。该算法的计算过程如下,算法中出现的y即上文中提到的t:

算法L-BFGS的步骤如下所示。

2.6 OWL-QN算法
2.6.1 L1 正则化
在机器学习算法中,使用损失函数作为最小化误差,而最小化误差是为了让我们的模型拟合我们的训练数据,此时,
若参数过分拟合我们的训练数据就会有过拟合的问题。正则化参数的目的就是为了防止我们的模型过分拟合训练数据。此时,我们会在损失项之后加上正则化项以约束模型中的参数:
J(x) = l(x) + r(x)
公式右边的第一项是损失函数,用来衡量当训练出现偏差时的损失,可以是任意可微凸函数(如果是非凸函数该算法只保证找到局部最优解)。
第二项是正则化项。用来对模型空间进行限制,从而得到一个更“简单”的模型。
根据对模型参数所服从的概率分布的假设的不同,常用的正则化一般有L2正则化(模型参数服从Gaussian分布)、L1正则化(模型参数服从Laplace分布)以及它们的组合形式。
L1正则化的形式如下
J(x) = l(x) + C ||x||_{1}
L2正则化的形式如下
J(x) = l(x) + C ||x||_{2}
L1正则化和L2正则化之间的一个最大区别在于前者可以产生稀疏解,这使它同时具有了特征选择的能力,此外,稀疏的特征权重更具有解释意义。如下图:
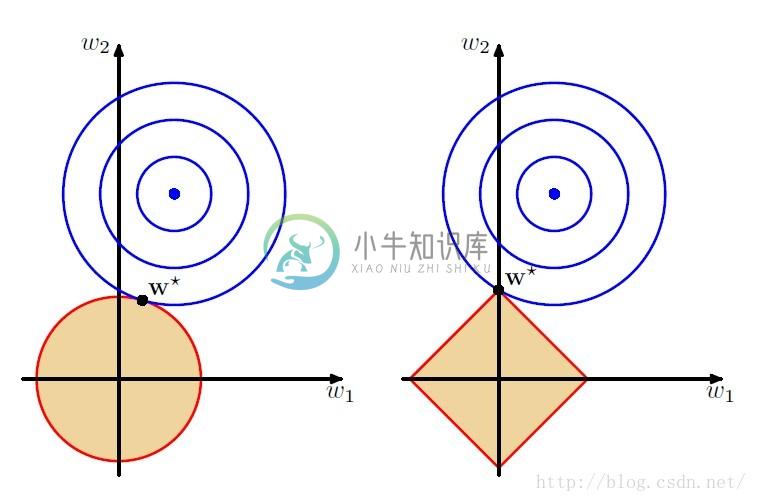
图左侧是L2正则,右侧为L1正则。当模型中只有两个参数,即$w_1$和$w_2$时,L2正则的约束空间是一个圆,而L1正则的约束空间为一个正方形,这样,基于L1正则的约束会产生稀疏解,即图中某一维($w_2$)为0。
而L2正则只是将参数约束在接近0的很小的区间里,而不会正好为0(不排除有0的情况)。对于L1正则产生的稀疏解有很多的好处,如可以起到特征选择的作用,因为有些维的系数为0,说明这些维对于模型的作用很小。
这里有一个问题是,L1正则化项不可微,所以无法像求L-BFGS那样去求。微软提出了OWL-QN(Orthant-Wise Limited-Memory Quasi-Newton)算法,该算法是基于L-BFGS算法的可用于求解L1正则的算法。
简单来讲,OWL-QN算法是指假定变量的象限确定的条件下使用L-BFGS算法来更新,同时,使得更新前后变量在同一个象限中(使用映射来满足条件)。
2.6.2 OWL-QN算法的具体过程
- 1 次微分
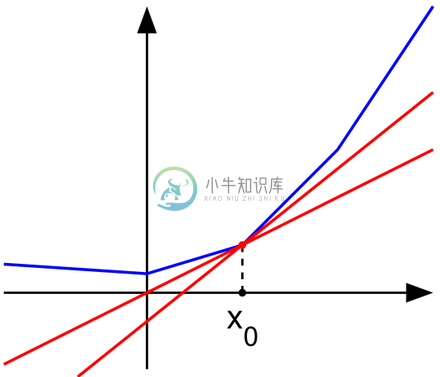
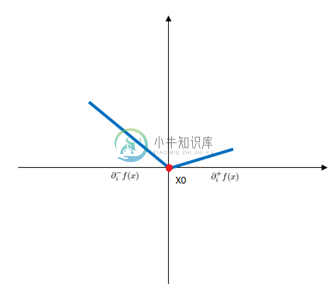
设$f:I\rightarrow R$是一个实变量凸函数,定义在实数轴上的开区间内。这种函数不一定是处处可导的,例如绝对值函数$f(x)=|x|$。但是,从下面的图中可以看出(也可以严格地证明),对于定义域中的任何$x_0$,我们总可以作出一条直线,它通过点($x_0$, $f(x_0)$),并且要么接触f的图像,要么在它的下方。
这条直线的斜率称为函数的次导数。推广到多元函数就叫做次梯度。
凸函数$f:I\rightarrow R$在点$x_0$的次导数,是实数c使得:
对于所有I内的x。我们可以证明,在点$x_0$的次导数的集合是一个非空闭区间$[a, b]$,其中a和b是单侧极限。
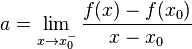
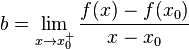
它们一定存在,且满足$a \leqslant b$。所有次导数的集合$[a, b]$称为函数f在$x_0$的次微分。
- 2 伪梯度
利用次梯度的概念推广了梯度,定义了一个符合上述原则的伪梯度,求一维搜索的可行方向时用伪梯度来代替L-BFGS中的梯度。
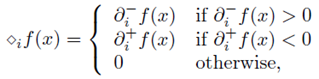
其中
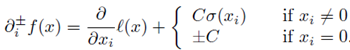
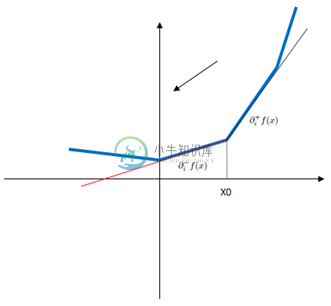
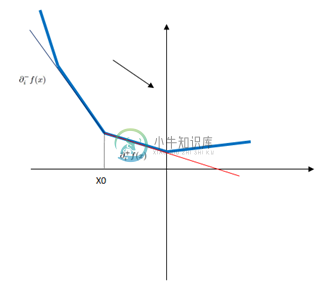
我们要如何理解这个伪梯度呢?对于不是处处可导的凸函数,可以分为下图所示的三种情况。
左侧极限小于0:
右侧极限大于0:
其它情况:
结合上面的三幅图表示的三种情况以及伪梯度函数公式,我们可以知道,伪梯度函数保证了在$x_0$处取得的方向导数是最小的。
- 3 映射
有了函数的下降的方向,接下来必须对变量的所属象限进行限制,目的是使得更新前后变量在同一个象限中,定义函数:$\pi: \mathbb{R}^{n} \rightarrow \mathbb{R}^{n}$
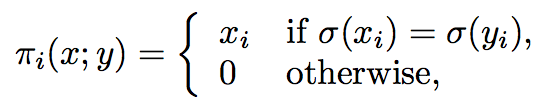
上述函数$\pi$直观的解释是若$x$和$y$在同一象限则取$x$,若两者不在同一象限中,则取0。
- 4 线搜索
上述的映射是防止更新后的变量的坐标超出象限,而对坐标进行的一个约束,具体的约束的形式如下:
其中$x^{k} + \alpha p _{k}$是更新公式,$\zeta$表示$x^k$所在的象限,$p^k$表示伪梯度下降的方向,它们具体的形式如下:
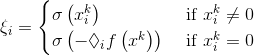
上面的公式中,$v^k$为负伪梯度方向,$d^k = H_{k}v^{k}$。
选择$\alpha$的方式有很多种,在OWL-QN中,使用了backtracking line search的一种变种。选择常数$\beta, \gamma \subset (0,1)$,对于$n=0,1,2,…$,使得
$\alpha = \beta^{n}$满足:
- 5 算法流程

与L-BFGS相比,第一步用伪梯度代替梯度,第二、三步要求一维搜索不跨象限,也就是迭代前的点与迭代后的点处于同一象限,第四步要求估计Hessian矩阵时依然使用损失函数的梯度。
3 源码解析
3.1 BreezeLBFGS
spark Ml调用breeze中实现的BreezeLBFGS来解最优化问题。
val optimizer = new BreezeLBFGS[BDV[Double]]($(maxIter), 10, $(tol))val states =optimizer.iterations(new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector)
下面重点分析lbfgs.iterations的实现。
def iterations(f: DF, init: T): Iterator[State] = {val adjustedFun = adjustFunction(f)infiniteIterations(f, initialState(adjustedFun, init)).takeUpToWhere(_.converged)}//调用infiniteIterations,其中State是一个样本类def infiniteIterations(f: DF, state: State): Iterator[State] = {var failedOnce = falseval adjustedFun = adjustFunction(f)//无限迭代Iterator.iterate(state) { state => try {//1 选择梯度下降方向val dir = chooseDescentDirection(state, adjustedFun)//2 计算步长val stepSize = determineStepSize(state, adjustedFun, dir)//3 更新权重val x = takeStep(state,dir,stepSize)//4 利用CostFun.calculate计算损失值和梯度val (value,grad) = calculateObjective(adjustedFun, x, state.history)val (adjValue,adjGrad) = adjust(x,grad,value)val oneOffImprovement = (state.adjustedValue - adjValue)/(state.adjustedValue.abs max adjValue.abs max 1E-6 * state.initialAdjVal.abs)//5 计算s和tval history = updateHistory(x,grad,value, adjustedFun, state)//6 只保存m个需要的s和tval newAverage = updateFValWindow(state, adjValue)failedOnce = falsevar s = State(x,value,grad,adjValue,adjGrad,state.iter + 1, state.initialAdjVal, history, newAverage, 0)val improvementFailure = (state.fVals.length >= minImprovementWindow && state.fVals.nonEmpty && state.fVals.last > state.fVals.head * (1-improvementTol))if(improvementFailure)s = s.copy(fVals = IndexedSeq.empty, numImprovementFailures = state.numImprovementFailures + 1)s} catch {case x: FirstOrderException if !failedOnce =>failedOnce = truelogger.error("Failure! Resetting history: " + x)state.copy(history = initialHistory(adjustedFun, state.x))case x: FirstOrderException =>logger.error("Failure again! Giving up and returning. Maybe the objective is just poorly behaved?")state.copy(searchFailed = true)}}}
看上面的代码注释,它的流程可以分五步来分析。
3.1.1 选择梯度下降方向
protected def chooseDescentDirection(state: State, fn: DiffFunction[T]):T = {state.history * state.grad}
这里的*是重写的方法,它的实现如下:
def *(grad: T) = {val diag = if(historyLength > 0) {val prevStep = memStep.headval prevGradStep = memGradDelta.headval sy = prevStep dot prevGradStepval yy = prevGradStep dot prevGradStepif(sy < 0 || sy.isNaN) throw new NaNHistorysy/yy} else {1.0}val dir = space.copy(grad)val as = new Array[Double](m)val rho = new Array[Double](m)//第一次递归for(i <- 0 until historyLength) {rho(i) = (memStep(i) dot memGradDelta(i))as(i) = (memStep(i) dot dir)/rho(i)if(as(i).isNaN) {throw new NaNHistory}axpy(-as(i), memGradDelta(i), dir)}dir *= diag//第二次递归for(i <- (historyLength - 1) to 0 by (-1)) {val beta = (memGradDelta(i) dot dir)/rho(i)axpy(as(i) - beta, memStep(i), dir)}dir *= -1.0dir}}
非常明显,该方法就是实现了上文提到的two-loop recursion算法。
3.1.2 计算步长
protected def determineStepSize(state: State, f: DiffFunction[T], dir: T) = {val x = state.xval grad = state.gradval ff = LineSearch.functionFromSearchDirection(f, x, dir)val search = new StrongWolfeLineSearch(maxZoomIter = 10, maxLineSearchIter = 10) // TODO: Need good default values here.val alpha = search.minimize(ff, if(state.iter == 0.0) 1.0/norm(dir) else 1.0)if(alpha * norm(grad) < 1E-10)throw new StepSizeUnderflowalpha}
这一步对应L-BFGS的步骤的Step 5,通过一维搜索计算步长。
3.1.3 更新权重
protected def takeStep(state: State, dir: T, stepSize: Double) = state.x + dir * stepSize
这一步对应L-BFGS的步骤的Step 5,更新权重。
3.1.4 计算损失值和梯度
protected def calculateObjective(f: DF, x: T, history: History): (Double, T) = {f.calculate(x)}
这一步对应L-BFGS的步骤的Step 7,使用传人的CostFun.calculate方法计算梯度和损失值。并计算出s和t。
3.1.5 计算s和t,并更新history
//计算s和tprotected def updateHistory(newX: T, newGrad: T, newVal: Double, f: DiffFunction[T], oldState: State): History = {oldState.history.updated(newX - oldState.x, newGrad :- oldState.grad)}//添加新的s和t,并删除过期的s和tprotected def updateFValWindow(oldState: State, newAdjVal: Double):IndexedSeq[Double] = {val interm = oldState.fVals :+ newAdjValif(interm.length > minImprovementWindow) interm.drop(1)else interm}
3.2 BreezeOWLQN
BreezeOWLQN的实现与BreezeLBFGS的实现主要有下面一些不同点。
3.2.1 选择梯度下降方向
override protected def chooseDescentDirection(state: State, fn: DiffFunction[T]) = {val descentDir = super.chooseDescentDirection(state.copy(grad = state.adjustedGradient), fn)// The original paper requires that the descent direction be corrected to be// in the same directional (within the same hypercube) as the adjusted gradient for proof.// Although this doesn't seem to affect the outcome that much in most of cases, there are some cases// where the algorithm won't converge (confirmed with the author, Galen Andrew).val correctedDir = space.zipMapValues.map(descentDir, state.adjustedGradient, { case (d, g) => if (d * g < 0) d else 0.0 })correctedDir}
此处调用了BreezeLBFGS的chooseDescentDirection方法选择梯度下降的方向,然后调整该下降方向为正确的方向(方向必须一致)。
3.2.2 计算步长$\alpha$
override protected def determineStepSize(state: State, f: DiffFunction[T], dir: T) = {val iter = state.iterval normGradInDir = {val possibleNorm = dir dot state.gradpossibleNorm}val ff = new DiffFunction[Double] {def calculate(alpha: Double) = {val newX = takeStep(state, dir, alpha)val (v, newG) = f.calculate(newX) // 计算梯度val (adjv, adjgrad) = adjust(newX, newG, v) // 调整梯度adjv -> (adjgrad dot dir)}}val search = new BacktrackingLineSearch(state.value, shrinkStep= if(iter < 1) 0.1 else 0.5)val alpha = search.minimize(ff, if(iter < 1) .5/norm(state.grad) else 1.0)alpha}
takeStep方法用于更新参数。
// projects x to be on the same orthant as y// this basically requires that x'_i = x_i if sign(x_i) == sign(y_i), and 0 otherwise.override protected def takeStep(state: State, dir: T, stepSize: Double) = {val stepped = state.x + dir * stepSizeval orthant = computeOrthant(state.x, state.adjustedGradient)space.zipMapValues.map(stepped, orthant, { case (v, ov) =>v * I(math.signum(v) == math.signum(ov))})}
calculate方法用于计算梯度,adjust方法用于调整梯度。
// Adds in the regularization stuff to the gradientoverride protected def adjust(newX: T, newGrad: T, newVal: Double): (Double, T) = {var adjValue = newValval res = space.zipMapKeyValues.mapActive(newX, newGrad, {case (i, xv, v) =>val l1regValue = l1reg(i)require(l1regValue >= 0.0)if(l1regValue == 0.0) {v} else {adjValue += Math.abs(l1regValue * xv)xv match {case 0.0 => {val delta_+ = v + l1regValue //计算左导数val delta_- = v - l1regValue //计算右导数if (delta_- > 0) delta_- else if (delta_+ < 0) delta_+ else 0.0}case _ => v + math.signum(xv) * l1regValue}}})adjValue -> res}
参考文献
【1】陈宝林,最优化理论和算法
【2】Updating Quasi-Newton Matrices with Limited Storage
【3】On the Limited Memory BFGS Method for Large Scale Optimization
【4】L-BFGS算法
【5】BFGS算法