
Underscore源码分析

几年前就有人说javascript是最被低估一种编程语言,自从nodejs出来后,全端(All Stack/Full Stack)概念日渐兴起,现在恐怕没人再敢低估它了。javascrip是一种类C的语言,有C语言基础就能大体理解javascript的代码,但是作为一种脚本语言,javascript的灵活性是C所远远不及的,这也会造成学习上的一些困难。
一、集合
1.首先是几个迭代的方法。
_.each = _.forEach = function(obj, iteratee, context) {
iteratee = optimizeCb(iteratee, context);
var i, length;
if (isArrayLike(obj)) {
for (i = 0, length = obj.length; i < length; i++) {
iteratee(obj[i], i, obj);
}
} else {
var keys = _.keys(obj);
for (i = 0, length = keys.length; i < length; i++) {
iteratee(obj[keys[i]], keys[i], obj);
}
}
// 链式调用
return obj;
};
ES为数组同样添加了原生的forEach()方法。不同的是这里的each(forEach)方法可以对所有集合使用,函数接受三个参数(集合、迭代函数、执行环境)。
optimizeCb函数根据迭代函数参数个数的不同为不同的迭代方法绑定了相应的执行环境,forEach迭代函数同样接受三个参数(值,索引,集合)。
接下来就是for循环调用迭代函数了。
_.map中一种更优雅的判断isArrayLike的实现方式:(只用一个for循环)
var keys = !isArrayLike(obj) && _.keys(obj),
length = (keys || obj).length,
results = Array(length);
for (var index = 0; index < length; index++) {
var currentKey = keys ? keys[index] : index;
results[index] = iteratee(obj[currentKey], currentKey, obj);
}
return results;
// 合理使用&&、||、?:可以大大减少代码量
还有两个特别的地方:
•将集合分成了类数组集合和对象集合。使用了isArrayLike函数:
// js的最大精确整数
var MAX_ARRAY_INDEX = Math.pow(2, 53) - 1;
var isArrayLike = function(collection) {
var length = collection != null && collection.length;
return typeof length == 'number' && length >= 0 && length <= MAX_ARRAY_INDEX;
}; // 如果集合有Length属性且为数字并且大于0小于最大的精确整数,则判定是类数组
•使用了_.keys函数,Object同样有原生的keys函数,用于返回一个集合obj可被枚举的属性数组。实现比较简单,for in加上hasOwnProperty()方法。
--------------------------------------------------------------------------------
_.map,_.reduce方法原理类似.
_.find函数和Array.some()类似,不同的是返回的是第一个使迭代结果为真的那个元素,而不是Array.some()那样返回布尔值。
_.find = _.detect = function(obj, predicate, context) {
var key;
if (isArrayLike(obj)) {
key = _.findIndex(obj, predicate, context);
} else {
key = _.findKey(obj, predicate, context);
}
if (key !== void 0 && key !== -1) return obj[key];
};
function createIndexFinder(dir) {
return function(array, predicate, context) {
predicate = cb(predicate, context);
var length = array != null && array.length;
// 如果dir为1,index为0,index+=1,index正序循环
// 如果dir 为-1,index为length-1,index += -1反序循环
// 判断循环条件则用了index >= 0 && index < length方法兼顾两种循环方式
var index = dir > 0 ? 0 : length - 1;
for (; index >= 0 && index < length; index += dir) {
if (predicate(array[index], index, array)) return index;
}
return -1;
};
}
_.findIndex = createIndexFinder(1);
_.findLastIndex = createIndexFinder(-1);
值得借鉴的地方是这里的一个for循环能够根据传入的参数不同配置不同的循环顺序。
1.集合中的其他方法基本都是基于迭代方法来实现的。
_.max = function(obj, iteratee, context) {
var result = -Infinity, lastComputed = -Infinity,
value, computed;
if (iteratee == null && obj != null) {
obj = isArrayLike(obj) ? obj : _.values(obj);
for (var i = 0, length = obj.length; i < length; i++) {
value = obj[i];
if (value > result) {
result = value;
}
}
} else {
iteratee = cb(iteratee, context);
_.each(obj, function(value, index, list) {
computed = iteratee(value, index, list);
if (computed > lastComputed || computed === -Infinity && result === -Infinity) {
result = value;
lastComputed = computed;
}
});
}
return result;
};
max方法用于寻找集合中的最大值,通过循环list中的所有项,然后比较当前项和结果项,如果当前项大于结果,则将其赋给结果项,最后返回结果项。
2.集合转换为数组
_.toArray = function(obj) {
if (!obj) return [];
// 如果是数组,采用了Array.prototype.slice.call(this,obj)这种方法
if (_.isArray(obj)) return slice.call(obj);
// 类数组对象,这里没有采用Slice方法,而是利用.map对集合进行迭代,从而返回一个数组。 _.identity该方法传入的值和返回的值相等。(主要用于迭代)
if (isArrayLike(obj)) return _.map(obj, _.identity);
// 普通对象,则返回由属性值组成的数组。
return _.values(obj);
};
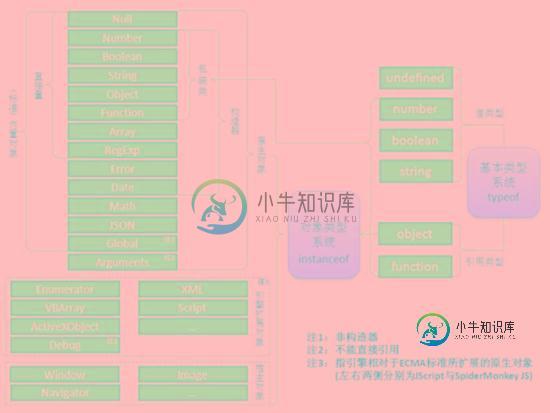
数据类型
STL需要对vector、list等进行区分是因为不同的数据结构需要或者可以进行不同的实现,但underscore里面Collections和Arrays分开是什么道理呢?这也要从javascript的数据类型说起,看下图。
-
underscore Underscore 提供了一系列有用的函数,用来操作数组,对象,和函数。每个Meteor APP都包含underscore包,因为框架大量使用了underscore。
-
前面我们已经讲过了,JavaScript是函数式编程语言,支持高阶函数和闭包。函数式编程非常强大,可以写出非常简洁的代码。例如Array的map()和filter()方法: 'use strict'; var a1 = [1, 4, 9, 16]; var a2 = a1.map(Math.sqrt); // [1, 2, 3, 4] var a3 = a2.filter((x) => { ret
-
这一节我们来看看requests是如何发送一个request的,这一节内容可能比较多,有很多底层代码,我自己也看的头疼,建议阅读前先喝瓶酸奶以保持轻松的心情。如果你准备好了,请往下看。 我们在Pycharm中按住win点击get,会来到get方法的源码: def get(url, params=None, **kwargs): r"""Sends a GET request. :
-
传统习惯 上高清无码自制大图: 不需要理解图中各个类的功能, 大致扫一眼留一下印象。 State组件中有三个比较重要的地方,一个是State这个结构, 一个是BlockExector,还有一个是Store。 我们先看State结构。 它代表了区块的状态。 看一下它的详情数据结构: type State struct { //链ID 整个链中都是不会变化的 ChainID strin
-
基本组件说明 P2P模块涉及的最重要的组件如上图所示, 上述的UML图并没有列出某个类的所有属性和方法,只是列举了我认为比较重要的部分。 第一眼看到上面的类图我猜应该是什么也看不出来。 再仔细看我想依然是云山雾绕不知道整个P2P的流程。 所以类图只是给大家一个基本的组件印象。让大家能大致猜测一下各个组件的功能。 现在我们不妨按着上面的类图去大胆猜一猜上述的各个组件的功能。 我们先从Switch这个
-
老规矩,先上图。 内存池的作用简而言之就是为了保存从其他peer或者自身受到的还未被打包的交易。 我们看一下mempool的文件夹。 所以我们关注的内存池的源码其实只有mempool.go和reactor.go文件。 从源文件名称应该可以看出来MemPool的成员方法是在mempool.go文件中, 和peer信息信息的交互应该是在reactor.go文件中的。 在mempool.go文件中看到这