《pandas》专题
-
在Pandas中将float64列转换为int64
问题内容: 我试图将列从数据类型转换为使用: 但出现错误: NameError:未定义名称“ int64” 专栏有人数,但其格式为:我知道如何将其更改为? 问题答案: 大熊猫 0.24+的 解决方案,用于转换缺少值的数字: ValueError:无法将非限定值(NA或inf)转换为整数 我认为您需要转换为: 样品: 如果某些S IN列需要他们取代一些(例如)通过,因为的是: 同时检查文档-缺少数据
-
Python3 pandas 操作列表实例详解
本文向大家介绍Python3 pandas 操作列表实例详解,包括了Python3 pandas 操作列表实例详解的使用技巧和注意事项,需要的朋友参考一下 1.首先需要安装pandas, 安装的时候可能由依赖的包需要安装,根据运行时候的提示,缺少哪个库,就pip 安装哪个库。 2.示例代码 总结: 只要学会把excel文件内容读取处理,进行相关的增删修改,最后调用 .to_excel()方法便可以
-
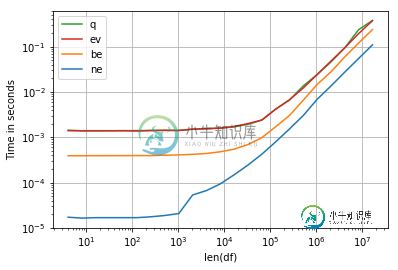 pandas数据框:位置与查询性能
pandas数据框:位置与查询性能问题内容: 我在python中有2个数据框,我想查询数据。 DF1:4M记录x 3列。查询函数比loc函数更有效。 DF2:2K记录x 6列。loc函数的接缝比查询函数更有效。 这两个查询都返回一条记录。通过将相同的操作循环运行10K次来完成仿真。 运行python 2.7和pandas 0.16.0 有什么建议可以提高查询速度? 问题答案: 为了提高性能,可以使用:
-
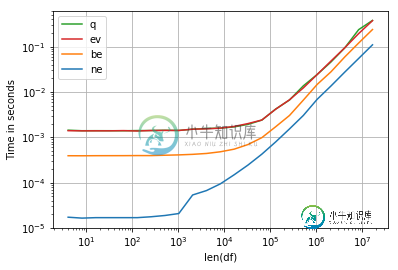 pandas dataframe: loc vs query performance
pandas dataframe: loc vs query performance问题内容: I have 2 dataframes in python that I would like to query for data. DF1: 4M records x 3 columns. The query function seams more efficient than the loc function. DF2: 2K records x 6 columns. The lo
-
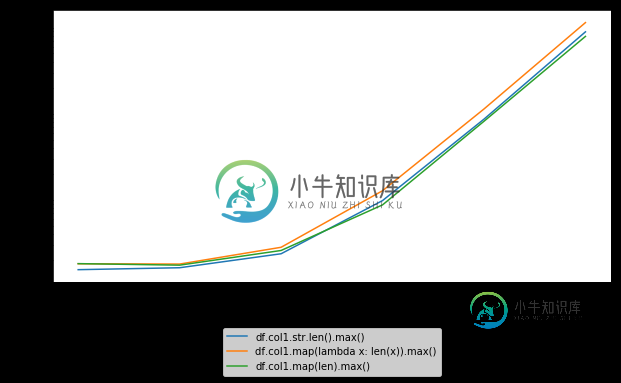 在Pandas数据框列中找到最长字符串的长度
在Pandas数据框列中找到最长字符串的长度问题内容: 有没有比下面的示例更快的方法来找到Pandas DataFrame中最长字符串的长度? 使用IPython的进行计时大约需要10秒钟。 问题答案: DSM的建议似乎是您无需进行一些手动微优化就能获得的最佳效果: 请注意,显式使用该方法似乎并没有多大改进。如果您不熟悉IPython(这是非常方便的语法所来自的地方),我绝对建议您尝试一下,以快速测试此类内容。 更新 添加了屏幕截图:
-
Python Pandas:如何在groupby / transform操作内部向数据框添加全新的列
问题内容: 我想在数据中标记一些分位数,对于DataFrame的每一行,我希望在名为“ xtile”的新列中的条目保持该值。 例如,假设我创建一个像这样的数据框: 假设我编写了自己的函数来计算数组中每个元素的五分位数。我对此有自己的功能,但例如仅参考scipy.stats.mstats.mquantile。 现在,真正的问题是如何使用向数据添加新列。像这样: 接着: 问题是上述代码不会添加新列“
-
如何将模型对象列表转换为pandas数据框?
问题内容: 我有一个此类的对象数组 打印时,数组看起来像这样 我想将其转换为数据帧,以便我可以以更适合我的方式进行操作-进行汇总,计数,求和等。我希望这个数据框看起来像这样: 有没有一种方法可以轻松地使用numpy / pandas来实现,而无需手动处理输入数组? 问题答案: 导致预期结果的代码: 感谢@Serbitar为我指出正确的方向。
-
检查pandas数据框索引中是否存在值
问题内容: 我敢肯定有一种明显的方法可以做到这一点,但现在还不能想到任何光滑的东西。 基本上不是引发异常,而是要获取或查看pandas索引中是否存在值。 我现在工作的是以下内容 问题答案: 这应该可以解决问题
-
Fillna在Python Pandas中的多列中
问题内容: 我有一个混合类型的pandas dataFrame,有些是字符串,有些是数字。我想用“。”替换字符串列中的NAN值,并用0替换浮点数列中的NAN值。 考虑这个小的虚拟示例: 现在,我可以分为三行: 由于这是一个很小的数据帧,因此3行可能没问题。在我的真实示例中(由于数据机密性原因,在此无法共享),我还有更多的字符串列和数字列。所以我最终只为fillna写了很多行。有一种简洁的方法吗?
-
重命名Pandas Groupby函数中的列名[重复]
问题内容: 这个问题已经在这里有了答案 : 使用pandas GroupBy.agg()对同一列进行多次聚合 (3个答案) 去年关闭。 示例数据集: 我想通过和对这个数据集的观察进行分组,并对每个组求和。所以我用了这样的东西… 在使用时,我能够获得“ SQL-like”输出。我的问题是我无法在此处 重命名聚合变量。因此,在SQL中,如果想做上述事情,我会做这样的事情: 正如我们看到的,它很容易让我
-
 pandas处理csv文件的方法步骤
pandas处理csv文件的方法步骤本文向大家介绍pandas处理csv文件的方法步骤,包括了pandas处理csv文件的方法步骤的使用技巧和注意事项,需要的朋友参考一下 一、我的需求 对于这样的一个 csv 表,需要将其 (1)将营业部名称和日期和股票代码进行拼接 (2)对于除了买入金额不同的的数据需要将它们的买入金额相加,每个买入金额乘以买卖序号的符号表示该营业名称对应的买入金额 比如:xx公司,20190731,1,股票1,4
-
Pandas DataFrame的起始索引为1
问题内容: 将Pandas DataFrame写入CSV时,我需要索引从1开始而不是0。 这是一个例子: 产生以下输出: 但是我想要的输出是这样的: 我意识到可以通过在数据帧中添加一列以1为单位的整数序列来完成此操作,但是我对Pandas并不陌生,我想知道是否存在更简洁的方法。 问题答案: 索引是一个对象,默认索引从开始: 您可以使用
-
将pandas.Series直方图保存到文件
问题内容: 在ipython Notebook中,首先创建一个pandas Series对象,然后通过调用实例方法.hist(),浏览器将显示该图。 我想知道如何将该图形保存到文件中(不是通过右键单击另存为,而是脚本中所需的命令)。 问题答案: 使用方法,如下所示: 它不必以结尾结尾,有很多选择。查看文档。 或者,您可以使用该接口,并仅作为函数调用来保存最近创建的图形:
-
如何使Pandas DataFrame列标题全部小写?
问题内容: 我想使我的pandas数据框中的所有列标题都小写 例 如果我有: 我想通过执行以下操作将XRAT更改为xrat: 这样我得到: 我不会提前知道每个列标题的名称。 问题答案: 您可以这样做: 要么 例:
-
基于Pandas读取csv文件Error的总结
本文向大家介绍基于Pandas读取csv文件Error的总结,包括了基于Pandas读取csv文件Error的总结的使用技巧和注意事项,需要的朋友参考一下 OSError:报错1 分析:Error在于_setup_parser_source ,说明文件压根没有读到,导致该原因一般为文件路径出现问题,检查是否有中文,中文有时会导致该问题 解决方案: 1、修改文件路径名为全英文包括文件名 2、在文件名