《pandas》专题
-
在pandas df中返回列名称的最有效方法
问题内容: 我有一个 包含4个不同的。对于每一个孤单一个重要性的多数民众赞成。我想回到的地方是显示。因此,对于以下内容,我想在标记值为2时返回名称。 输出: 原来如此 我通过这样做 然后更改行。但这不是很有效。 我也希望将输出从 问题答案: 用途: 要么, 或者,作为列表: …或系列:
-
在Pandas中分配列时处理SettingWithCopyWarning [重复]
问题内容: 这个问题已经在这里有了答案 : 如何在熊猫中处理SettingWithCopyWarning (15个答案) 1年前关闭。 我有一个要扩展的列,其中包含上一行的数据。 此脚本可以完成以下任务: 它输出: 这正是我想要的。在现在有两个附加列和包含列的值 1 点 2 之前的行。 但是,我也得到警告: 问题肯定来自我创建之前的过滤。如果我直接工作,则不会发生此问题。在我的应用程序中,我需要分
-
在字符串的pandas数据框中查找值计数
问题内容: 我想获取一列中字符串的频率计数。一方面,这类似于将数据框折叠为仅反映列中的字符串的一组行。我能够通过循环解决此问题,但知道有更好的解决方案。 df示例: 并想出去: 我搜索了很多论坛,但找不到合适的答案。 我假设使用pivot_table方法是正确的方法,但是无法获取正确的参数来折叠没有为输出df提供明显索引的表。 我可以通过使用value_counts()遍历每列并将每个值计数系列附
-
Python-将嵌套字典列表转换为Pandas Dataframe
本文向大家介绍Python-将嵌套字典列表转换为Pandas Dataframe,包括了Python-将嵌套字典列表转换为Pandas Dataframe的使用技巧和注意事项,需要的朋友参考一下 python很多时候会从各种来源接收数据,这些数据可以采用不同的格式,例如csv,JSON等,可以转换为python列表或字典等。但是要使用诸如pandas之类的包应用计算或分析,我们需要将此数据转换为一
-
自然排序Pandas DataFrame
问题内容: 我有一个熊猫DataFrame,它的索引要自然排序。Natsort似乎不起作用。在构建DataFrame之前对索引进行排序似乎无济于事,因为我对DataFrame所做的操作似乎使过程中的排序变得混乱。关于如何自然使用索引的任何想法? 问题答案: 如果要对df进行排序,只需对索引或数据进行排序,然后直接将其分配给df的索引,而不是尝试将df作为arg传递,因为这会产生一个空列表: 请注意
-
将2列中的值合并为pandas数据框中的单个列
问题内容: 我正在寻找一种行为与T-SQL中的合并类似的方法。我有2列(列A和B)稀疏地填充在pandas数据框中。我想使用以下规则创建一个新列: 如果A列中的值 不为null ,则将该值用于新C列 如果A列中的 值为null ,则将B列中的值用于新C列 就像我提到的那样,这可以通过合并功能在MS SQL Server中完成。我还没有找到一个好的pythonic方法。是否存在? 问题答案: 使用C
-
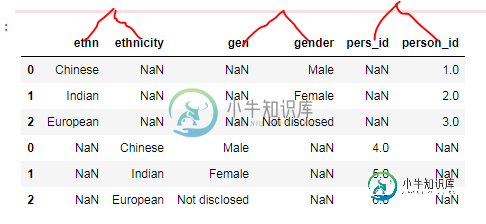 追加具有不同列名的数据框-Pandas
追加具有不同列名的数据框-Pandas问题内容: 我有3个数据框,可以从下面显示的代码中生成 我想做两件事 a) 将所有这三个数据帧追加到一个大数据帧中 当我尝试使用以下代码进行此操作时,输出结果与预期不符 因此,要解决此问题,我了解我们必须重命名导致以下目标b的列名 b) 以一种优雅的方式将这n个数据帧的列重命名为统一的 请注意,在实时情况下,我可能具有预先不知道的具有不同列名的数据框,但它们中的值始终属于列和,并且始终相同。但请注
-
如何检查python pandas中列的dtype
问题内容: 我需要使用不同的函数来处理数字列和字符串列。我现在正在做的事情真是愚蠢: 有没有更优雅的方法可以做到这一点?例如 问题答案: 您可以使用以下命令访问列的数据类型:
-
Python Pandas如何将groupby操作结果分配回父数据帧中的列?
问题内容: 我在IPython中具有以下数据框,其中每一行都是一只股票: 我想应用一个groupby操作,该操作计算“ yearmonth”列中每个日期的所有内容的上限加权平均回报。 这按预期工作: 但是,然后我想将这些值“广播”回原始数据帧中的索引,并将它们保存为日期匹配的常量列。 我意识到这种天真的任务不起作用。但是,将groupby操作的结果分配给父数据帧上新列的“正确” Pandas习惯用
-
pandas apply使用多列计算生成新的列实现示例
本文向大家介绍pandas apply使用多列计算生成新的列实现示例,包括了pandas apply使用多列计算生成新的列实现示例的使用技巧和注意事项,需要的朋友参考一下 在python数据分析中,有时需要根据多列数据生成中间结果,pandas给我们带来了很多方便,通常简短的代码可以实现一些高级功能,灵活掌握一些技巧可以事倍功半 pandas的apply方法用于对指定列的每个元素进行相同的操作,下
-
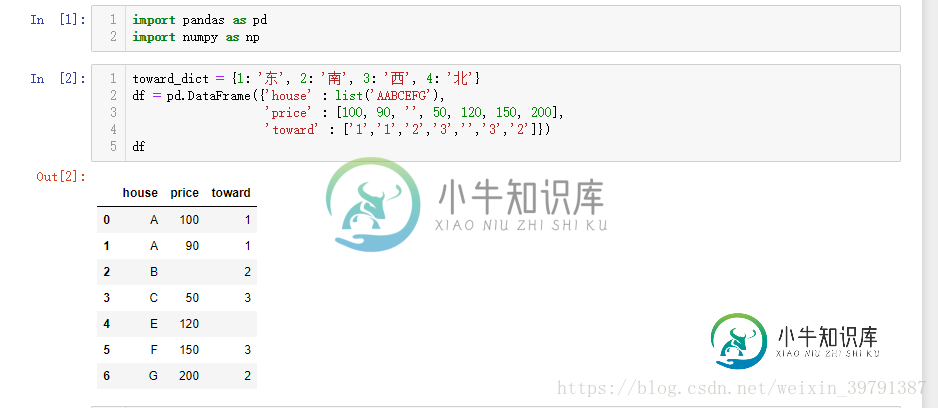 pandas map(),apply(),applymap()区别解析
pandas map(),apply(),applymap()区别解析本文向大家介绍pandas map(),apply(),applymap()区别解析,包括了pandas map(),apply(),applymap()区别解析的使用技巧和注意事项,需要的朋友参考一下 基础 以下操作基于python 3.6 windows 10 环境下 通过 将通过实例来演示三者的区别 map()方法 通过df.(tab)键,发现df的属性列表中有apply() 和 apply
-
Python Pandas:带有aggfunc的数据透视表=计数唯一唯一
问题内容: 追溯(最近一次呼叫最近):… AttributeError:“索引”对象没有属性“索引” 如何获得一个数据透视表,其中包含一个DataFrame列与其他两个列 的唯一值 的 计数 ? 是否有独特的计数?我应该使用吗? 注意 我知道“系列”,但是我需要一个数据透视表。 编辑:输出应为: 问题答案: 你的意思是这样吗? 请注意,使用假设您的DataFrame中没有。您可以做,否则可以。
-
python pandas,DF.groupby()。agg(),agg()中的列引用
问题内容: 关于一个具体问题,说我有一个DataFrame DF 我想 为每个“单词” 找到 具有最多“计数”的“标签” 。因此,回报将类似于 我不在乎计数列或订单/索引是原始的还是混乱的。返回字典{ ‘the’:’S’ ,…}很好。 我希望我能做 但这不起作用。我无法访问列信息。 更抽象地讲, agg( function ) 中的 函数 将其视为 __什么? 顺便说一句,.agg()与.aggr
-
如何使用索引将Pandas数据框写入sqlite
问题内容: 我在熊猫DataFrame中有一个从Yahoo提取的股市数据列表(请参见下面的格式)。该日期用作DataFrame中的索引。我想将数据(包括索引)写出到SQLite数据库中。 根据我对Pandas的write_frame代码的了解,它目前不支持编写index。我尝试使用to_records代替,但是遇到了Numpy 1.6.2和datetimes 的问题。现在,我尝试使用.itertu
-
获取pandas.read_csv以将空值读取为空字符串而不是nan
问题内容: 我正在使用pandas库读取一些CSV数据。在我的数据中,某些列包含字符串。该字符串是一个可能的值,一个空字符串也可以。我设法让大熊猫以字符串形式读取“ nan”,但我不知道如何获取它而不读取作为NaN的空值。这是示例数据和输出 它正确地写着“男”为字符串“南”,但仍读取空单元格作为NaN的。我想传递的参数read_csv(带),但它仍然读取空单元格作为NaN的。 我知道我可以在读取后